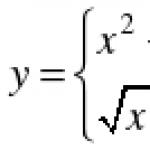İstatistiklerdeki önem seviyesi önemli gösterge, alınan (tahmin edilen) verilerin doğruluğuna ve doğruluğuna olan güven derecesini yansıtır. Konsept, çeşitli alanlarda yaygın olarak kullanılmaktadır: sosyolojik araştırma, bilimsel hipotezlerin istatistiksel testinden önce.
Tanım
Seviye İstatistiksel anlamlılık (veya istatistiksel olarak anlamlı sonuç), incelenen göstergelerin kazara oluşma olasılığının ne olduğunu gösterir. Olgunun genel istatistiksel önemi, p-değeri (p-seviyesi) katsayısı ile ifade edilir. Herhangi bir deneyde veya gözlemde, elde edilen verilerin örnekleme hatalarından kaynaklanma olasılığı vardır. Bu özellikle sosyoloji için geçerlidir.
Yani, istatistiksel olarak önemli bir değer, kazara meydana gelme olasılığı son derece küçük olan veya aşırı eğilimli bir değerdir. Bu bağlamdaki en uç nokta, istatistiklerin sıfır hipotezinden (elde edilen örnek verilerle tutarlılık için test edilen bir hipotez) sapma derecesidir. Bilimsel uygulamada, önem seviyesi veri toplamadan önce seçilir ve kural olarak katsayısı 0,05'tir (% 5). Doğru değerlerin son derece önemli olduğu sistemler için bu rakam 0,01 (% 1) veya daha az olabilir.

Sorunun tarihi
Anlamlılık düzeyi kavramı, İngiliz istatistikçi ve genetikçi Ronald Fisher tarafından 1925'te istatistiksel hipotezleri test etmek için bir yöntem geliştirirken tanıtıldı. Bir süreci analiz ederken, belirli olayların belirli bir olasılığı vardır. "Ölçüm hatası" kavramı kapsamına giren küçük (veya belirgin olmayan) olasılık yüzdeleri ile çalışırken zorluklar ortaya çıkar.
Bilim adamları, onları test etmek için yeterince spesifik olmayan istatistiksel verilerle çalışırken, küçük değerlerle çalışmayı "engelleyen" sıfır hipotezi problemiyle karşı karşıya kalırlar. Fisher, hesaplamalarda sıfır hipotezini reddetmek için uygun bir örnek kesimi olarak% 5 (0.05) 'de olayların olasılığını belirlemeyi önerdi.

Sabit katsayı tanıtımı
1933'te bilim adamları Jerzy Neumann ve Egon Pearson çalışmalarında önceden (veri toplamadan önce) belirli bir önem düzeyi belirlemesini tavsiye ettiler. Bu kuralların kullanımına ilişkin örnekler seçimler sırasında açıkça görülmektedir. Biri çok popüler, diğeri az bilinen iki aday olduğunu varsayalım. İlk adayın seçimleri kazanacağı, ikincinin şansının sıfıra yaklaşacağı açık. Çabalarlar - ama eşit değil: her zaman mücbir sebepler, sansasyonel bilgiler, tahmin edilen seçim sonuçlarını değiştirebilecek beklenmedik kararlar olasılığı vardır.
Neumann ve Pearson, Fisher'in önerdiği 0.05 anlamlılık seviyesinin (α ile gösterilir) en uygun olanı olduğu konusunda hemfikirdi. Ancak, 1956'da Fischer bu değerin sabitlenmesine karşı çıktı. Α seviyesinin belirli koşullara göre ayarlanması gerektiğine inanıyordu. Örneğin, parçacık fiziğinde 0.01'dir.

P düzeyi değer
P değeri terimi ilk olarak 1960 yılında Brownlee tarafından kullanılmıştır. P-değeri (p-değeri), sonuçların doğruluğu ile ters orantılı olan bir ölçüdür. En yüksek p değeri, değişkenler arasındaki ilişki örneklemindeki en düşük güven düzeyine karşılık gelir.
Bu değer, sonuçların yorumlanmasıyla ilişkili hataların olasılığını yansıtır. P düzeyinin 0,05 (1/20) olduğunu varsayalım. Örneklemde bulunan değişkenler arasındaki ilişkinin, örneğin rastgele bir özelliği olma olasılığının yüzde beşini gösterir. Yani, bu bağımlılık yoksa, tekrarlanan benzer deneylerle, ortalama olarak her yirminci çalışmada, değişkenler arasında aynı veya daha fazla bağımlılık beklenebilir. Çoğu zaman, p-seviyesi, hata oranının "kabul edilebilir sınırı" olarak kabul edilir.
Bu arada, p değeri değişkenler arasındaki gerçek ilişkiyi yansıtmayabilir, ancak varsayımlar dahilinde yalnızca belirli bir ortalama değeri gösterir. Özellikle, verilerin nihai analizi, bu katsayının seçilen değerlerine de bağlı olacaktır. P-düzeyinde \u003d 0.05, bazı sonuçlar ve 0.01 katsayısında diğerleri olacaktır.

İstatistiksel hipotezlerin test edilmesi
Hipotezleri test ederken istatistiksel önem düzeyi özellikle önemlidir. Örneğin, iki taraflı bir test hesaplanırken, reddetme alanı numune dağılımının her iki ucunda eşit olarak bölünür (sıfır koordinatına göre) ve elde edilen verilerin doğruluğu hesaplanır.
Farz edin ki, belirli bir süreci (fenomeni) izlerken, yeni istatistiksel bilginin önceki değerlere göre küçük değişiklikleri gösterdiğinin ortaya çıktığını varsayalım. Aynı zamanda, sonuçlardaki tutarsızlıklar küçüktür, açık değildir, ancak araştırma için önemlidir. Uzman bir ikilemle karşı karşıyadır: değişiklikler gerçekten meydana geliyor mu yoksa hataları mı örnekliyorlar (ölçüm yanlışlığı)?
Bu durumda, sıfır hipotezi ya kullanılır ya da reddedilir (her şey bir hataya yazılır ya da sistem değişikliği bir oldu bitmiş olarak kabul edilir). Problemi çözme süreci, genel istatistiksel anlamlılığın (p-değeri) ve anlamlılık düzeyinin (α) oranına dayanmaktadır. P düzeyindeyse< α, значит, нулевую гипотезу отвергают. Чем меньше р-value, тем более значимой является тестовая статистика.
Kullanılan değerler
Önem düzeyi, analiz edilen malzemeye bağlıdır. Pratikte aşağıdaki sabit değerler kullanılır:
- a \u003d 0.1 (veya% 10);
- a \u003d 0.05 (veya% 5);
- a \u003d 0.01 (veya% 1);
- α \u003d 0,001 (veya% 0,1).
Hesaplamalar ne kadar doğru olursa, α katsayısı o kadar küçük kullanılır. Doğal olarak, fizik, kimya, eczacılık ve genetik alanındaki istatistiksel tahminler, siyaset bilimi ve sosyolojiden daha fazla doğruluk gerektirir.

Belirli alanlardaki önem eşikleri
Parçacık fiziği ve imalat gibi yüksek hassasiyetli alanlarda, istatistiksel önem genellikle standart sapmanın (sigma katsayısı - σ ile gösterilir) normal olasılık dağılımına (Gauss dağılımı) oranı olarak ifade edilir. σ, belirli bir miktardaki değerlerin göreceli dağılımını belirleyen istatistiksel bir göstergedir. matematiksel beklentiler... Olayların olasılığını çizmek için kullanılır.
Bilgi alanına bağlı olarak, σ katsayısı büyük ölçüde değişir. Örneğin, Higgs bozonunun varlığını tahmin ederken, σ parametresi beşe eşittir (σ \u003d 5), bu da p-değeri \u003d 1 / 3,5 milyona karşılık gelir.Genom çalışmalarında, anlamlılık seviyesi 5 × 10 olabilir - 8, bu alan için nadir değildir.
Verimlilik
Lütfen α ve p-değerinin katsayılarının kesin karakteristikler olmadığını unutmayın. İncelenen olgunun istatistiğinin önem düzeyi ne olursa olsun, hipotezi kabul etmek için koşulsuz bir temel değildir. Örneğin daha az değer α, kurulan hipotezin anlamlı olma şansı o kadar yüksektir. Bununla birlikte, çalışmanın istatistiksel gücünü (anlamlılığını) azaltan bir hata riski vardır.
Yalnızca istatistiksel olarak önemli sonuçlara odaklanan araştırmacılar yanıltıcı sonuçlar elde edebilir. Aynı zamanda, varsayımları uyguladıklarından (aslında α ve p değerinin değerleridir) çalışmalarını iki kez kontrol etmek zordur. Bu nedenle, istatistiksel önemi hesaplamanın yanı sıra her zaman başka bir göstergenin - istatistiksel etkinin büyüklüğü - belirlenmesi önerilir. Etki boyutu, bir etkinin gücünün nicel bir ölçüsüdür.
Değişkenler arasındaki herhangi bir bağımlılığın temel özellikleri.
Değişkenler arasındaki ilişkinin en basit iki özelliği not edilebilir: (a) ilişkinin büyüklüğü ve (b) ilişkinin güvenilirliği.
- Miktar ... İlişkinin büyüklüğünü anlamak ve ölçmek, güvenilirliğe göre daha kolaydır. Örneğin, numunedeki herhangi bir erkeğin herhangi bir kadından daha yüksek bir beyaz kan hücresi sayımı (WCC) değeri varsa, iki değişken (Cinsiyet ve WCC) arasındaki ilişkinin çok yüksek olduğunu söyleyebilirsiniz. Başka bir deyişle, bir değişkenin değerlerini diğerinin değerlerinden tahmin edebilirsiniz.
- Güvenilirlik ("hakikat"). Karşılıklı bağımlılığın güvenilirliği, bağımlılığın büyüklüğünden daha az sezgiseldir, ancak son derece önemlidir. İlişkinin güvenilirliği, belirli bir örneğin temsili ile doğrudan ilişkilidir ve temelde sonuçlar çıkarılır. Başka bir deyişle, güvenilirlik, aynı popülasyondan alınan başka bir örneklemden alınan veriler üzerinde bir ilişkinin yeniden keşfedilme (başka bir deyişle doğrulanması) olasılığını gösterir.
Unutulmamalıdır ki nihai hedef neredeyse hiçbir zaman belirli bir değer örneğini incelemektir; örnek yalnızca popülasyonun tamamı hakkında bilgi sağladığı ölçüde ilgi çekicidir. Çalışma bazı özel kriterleri karşılıyorsa, örnek değişkenler arasında bulunan ilişkilerin güvenilirliği ölçülebilir ve standart bir istatistiksel ölçüm kullanılarak sunulabilir.
Bağımlılık ve güvenilirliğin büyüklüğü iki çeşitli özellikler değişkenler arasındaki bağımlılıklar. Ancak tamamen bağımsız oldukları söylenemez. Sıradan büyüklükteki bir örnekteki değişkenler arasındaki ilişkinin (ilişkinin) değeri ne kadar büyükse, o kadar güvenilirdir (sonraki bölüme bakın).
Bir sonucun istatistiksel önemi (p-seviyesi), "gerçeğine" ("örneğin temsil edilebilirliği" anlamında) olan tahmini bir güven ölçüsüdür. Daha teknik olarak konuşursak, p seviyesi sonucun güvenilirliği ile azalan bir göstergedir. Daha yüksek p seviyesi, daha fazlasına karşılık gelir düşük seviye örnekte bulunan değişkenler arasındaki bağımlılığa olan güven. Yani p-seviyesi, gözlemlenen sonucun tüm popülasyona yayılmasıyla ilişkili hata olasılığıdır.
Örneğin, p düzeyi \u003d 0.05 (yani 1/20), örnekte bulunan değişkenler arasındaki ilişkinin bu örneğin yalnızca rastgele bir özelliği olma olasılığının% 5 olduğunu gösterir. Birçok çalışmada, 0,05'lik bir p düzeyi, hata düzeyinin "kabul edilebilir sınırı" olarak kabul edilir.
Hangi önem düzeyinin gerçekten "önemli" olarak kabul edilmesi gerektiğine karar verirken keyfilikten kaçınmanın bir yolu yoktur. Sonuçların yanlış olduğu gerekçesiyle reddedildiği belirli bir önem düzeyinin seçimi oldukça keyfidir.
Pratikte son karar genellikle sonucun önceden mi tahmin edildiğine (yani deneyden önce) veya çeşitli verilerle yapılan birçok analiz ve karşılaştırmanın sonucu olarak bir posteriori keşfedilip keşfedilmediğine ve ayrıca verilen araştırma alanının geleneğine bağlıdır.
Tipik olarak, birçok alanda p .05 sonucu, istatistiksel anlamlılık için kabul edilebilir bir sınırdır, ancak bu düzeyin hala oldukça yüksek bir hata olasılığını (% 5) içerdiği unutulmamalıdır.
P .01 düzeyinde anlamlı olan sonuçlar genellikle istatistiksel olarak anlamlı kabul edilirken, p .005 veya p ile olanlar. 001 çok anlamlı. Ancak, bu önem seviyeleri sınıflandırmasının oldukça keyfi olduğu ve sadece pratik deneyime dayalı olarak kabul edilen gayri resmi bir anlaşma olduğu anlaşılmalıdır. belirli bir araştırma alanında.
Ne olduğu açık daha analizler bir dizi toplanan verilerle gerçekleştirilecek, önemli sonuçların sayısı (seçilen düzeyde) arttıkça tamamen şans eseri keşfedilecektir.
Birçok karşılaştırmayı içeren ve bu nedenle bu tür bir hatayı tekrarlama şansı önemli olan bazı istatistiksel yöntemler, özel ayarlamalar veya düzeltmeler yapar. toplam sayısı karşılaştırmalar. Bununla birlikte, birçok istatistiksel yöntem (özellikle basit yöntemler keşifsel veri analizi) bu soruna herhangi bir çözüm sunmamaktadır.
Değişkenler arasındaki ilişki "nesnel olarak" zayıfsa, böyle bir ilişkiyi test etmenin büyük bir örneği incelemekten başka bir yolu yoktur. Örnek mükemmel bir temsilci olsa bile, örnek küçükse etki istatistiksel olarak önemli olmayacaktır. Benzer şekilde, eğer ilişki "nesnel olarak" çok güçlü ise, o zaman çok küçük bir örneklemde bile yüksek derecede önemle bulunabilir.
Değişkenler arasındaki ilişki ne kadar zayıfsa, anlamlı bir şekilde tespit etmek için örneklem boyutu o kadar büyük olmalıdır.
Çok farklı bağlantılar değişkenler arasında. Belirli bir çalışmada belirli bir ölçünün seçimi, değişken sayısına, kullanılan ölçüm ölçeklerine, bağımlılıkların doğasına vb. Bağlıdır.
Bununla birlikte, bu önlemlerin çoğu, genel prensipGözlemlenen ilişkiyi, söz konusu değişkenler arasındaki "düşünülebilir maksimum ilişki" ile karşılaştırarak tahmin etmeye çalışırlar. Teknik olarak konuşursak, bu tür tahminler yapmanın yaygın bir yolu, değişkenlerin değerlerinin nasıl değiştiğine bakmak ve ardından mevcut toplam varyasyonun ne kadarının "ortak" ("ortak") varyasyonun varlığıyla ilişkilendirilebileceğini hesaplamaktır. iki (veya daha fazla) değişken.
Önem, esas olarak örneklem büyüklüğüne bağlıdır. Daha önce açıklandığı gibi, çok büyük örneklemlerde değişkenler arasındaki çok zayıf ilişkiler bile önemli olurken, küçük örneklemlerde çok güçlü ilişkiler bile güvenilir değildir.
Bu nedenle, istatistiksel anlamlılık düzeyini belirlemek için, her bir örneklem büyüklüğü için değişkenler arasındaki ilişkinin "büyüklüğü" ve "önemi" arasındaki ilişkiyi temsil edecek bir fonksiyona ihtiyaç vardır.
Böyle bir işlev, "popülasyonda böyle bir bağımlılık olmadığı varsayılarak, belirli bir büyüklükteki bir örnekte belirli bir değerin (veya daha fazlasının) bir bağımlılık elde etmenin ne kadar olası olduğunu" tam olarak belirtir. Başka bir deyişle, bu işlev bir anlam düzeyi verecektir.
(p -düzeyi) ve dolayısıyla, bu ilişkinin popülasyonda olmadığı varsayımını yanlışlıkla reddetme olasılığı.
Bu "alternatif" hipotez (popülasyonda bağımlılık olmadığı şeklindeki) genellikle sıfır hipotezi.
Hata olasılığını hesaplayan fonksiyonun doğrusal olması ve yalnızca farklı numune boyutları için farklı eğimlere sahip olması ideal olacaktır. Ne yazık ki, bu işlev çok daha karmaşıktır ve her zaman tam olarak aynı değildir. Bununla birlikte, çoğu durumda şekli bilinmektedir ve belirli bir büyüklükteki numuneleri incelerken önem seviyelerini belirlemek için kullanılabilir. Bu özelliklerin çoğu, adı verilen bir dağıtım sınıfı ile ilişkilidir. normal .
Görev 3. Beş anaokulu çocuğuna bir test yapılır. Her görevi çözme süresi kaydedilir. Testin ilk üç görevini tamamlamak için geçen süre arasında istatistiksel olarak önemli farklılıklar bulunacak mı?
|
Konu sayısı | |||
Referans malzemesi
Bu görev, varyans analizi teorisine dayanmaktadır. Genel olarak, varyans analizinin görevi, deneyin sonucu üzerinde önemli bir etkiye sahip olan faktörleri belirlemektir. ANOVA, örnek sayısı ikiden fazla ise birden fazla örneğin ortalamasını karşılaştırmak için kullanılabilir. Tek yönlü varyans analizi bu amaca hizmet eder.
Belirlenen görevleri çözmek için aşağıdakiler kabul edilir. Faktörlerin etkisi durumunda optimizasyon parametresinin elde edilen değerlerinin varyansları, faktörlerin etkisinin yokluğunda sonuçların varyanslarından farklıysa, böyle bir faktör önemli kabul edilir.
Problemin formülasyonundan görülebileceği gibi, burada istatistiksel hipotezleri test etmek için yöntemler, yani iki ampirik varyansı test etme problemi kullanılır. Sonuç olarak, varyans analizi Fisher'in testi ile varyansların kontrol edilmesine dayanır. Bu görevde, altı okul öncesi çocuğun her birinin testin ilk üç görevini çözme zamanı arasındaki farkların istatistiksel olarak anlamlı olup olmadığını kontrol etmek gerekir.
Boş (temel) hipotez H ® olarak adlandırılır. E'nin özü, karşılaştırılan parametreler arasındaki farkın sıfır olduğu (dolayısıyla hipotezin adı - sıfır) ve gözlemlenen farklılıkların rastgele olduğu varsayımına indirgenmiştir.
Rekabet eden (alternatif) hipotez, sıfır olanla çelişen hipotez H 1 olarak adlandırılır.
Karar:
Anlamlılık düzeyi α \u003d 0,05 olan varyans analizi yöntemini kullanarak, altı okul öncesi çocukta testin ilk üç görevini çözme zamanı arasında istatistiksel olarak anlamlı farklılıkların varlığına ilişkin sıfır hipotezini (H о) kontrol edeceğiz.
Üç test görevinin her birini çözmek için ortalama süreyi bulduğumuz görev koşulu tablosunu düşünün.
|
Konu sayısı |
Faktör seviyeleri |
||
|
İlk test görevini çözme süresi (saniye cinsinden). |
Testin ikinci görevini çözme süresi (saniye cinsinden). |
Üçüncü test görevini çözme süresi (saniye cinsinden). |
|
|
Grup ortalaması | |||
Genel ortalamayı bulun:
Her bir testin zamansal farklılıklarının önemini hesaba katmak için, toplam örneklem varyansı iki bölüme ayrılır; bunlardan ilki faktöryel, ikincisi ise kalıntıdır.
Formüle göre varyantın toplam ortalamadan sapmalarının toplam karelerinin toplamını hesaplayalım.
veya ![]() , burada p, test görevlerini çözme süresinin ölçüm sayısıdır, q, denek sayısıdır. Bunu yapmak için bir kareler tablosu yapın seçeneği
, burada p, test görevlerini çözme süresinin ölçüm sayısıdır, q, denek sayısıdır. Bunu yapmak için bir kareler tablosu yapın seçeneği
|
Konu sayısı |
Faktör seviyeleri |
||
|
İlk test görevini çözme süresi (saniye cinsinden). |
Testin ikinci görevini çözme süresi (saniye cinsinden). |
Üçüncü test görevini çözme süresi (saniye cinsinden). |
|
Ruh eşinizi özel, anlamlı kılan nedir sence? Onun kişiliğiyle mi yoksa bu kişi için sahip olduğunuz duygularınızla mı ilgili? Veya belki ile basit gerçekaraştırmanın gösterdiği gibi, beğendiğiniz rastgelelik hipotezinin% 5'in altında bir olasılığa sahip olduğunu? Son ifade güvenilir kabul edilirse, o zaman başarılı tanışma siteleri prensip olarak mevcut olmayacaktır:
Sitenizde A / C testi veya başka herhangi bir analiz yaparken, "istatistiksel önemin" yanlış anlaşılması, sonuçların yanlış yorumlanmasına ve dolayısıyla dönüşüm optimizasyonu sürecinde yanlış anlamalara yol açabilir. Bu, var olan herhangi bir sektörde günlük olarak gerçekleştirilen diğer binlerce istatistiksel test için de geçerlidir.
"İstatistiksel anlamın" ne olduğunu anlamak için, bu terimin ortaya çıkış tarihine dalmanız, gerçek anlamını öğrenmeniz ve bu "yeni" eski anlayışın araştırmanızın sonuçlarını doğru şekilde yorumlamanıza nasıl yardımcı olacağını anlamanız gerekir.
Biraz tarih
İnsanlık yüzyıllardır belirli problemleri çözmek için istatistiği kullanıyor olsa da, modern istatistiksel anlamlılık anlayışı, hipotez testi, randomizasyon ve hatta deneylerin tasarımı (Design of Experiments (DOE)) ancak 20. yüzyılın başında şekillenmeye başladı. yüzyıldır ve ayrılmaz bir şekilde Sir Ronald Fisher adıyla bağlantılıdır (Sir Ronald Fisher, 1890-1962):

Ronald Fisher, hayvanlar ve bitkiler krallığında evrim ve doğal seçilim araştırmalarına özel bir tutku duyan evrimsel bir biyolog ve istatistikçiydi. Şanlı kariyeri boyunca, bugün hala kullandığımız birçok yararlı istatistiksel aracı geliştirdi ve popüler hale getirdi.
Fischer, geliştirdiği teknikleri baskınlık, mutasyonlar ve genetik anormallikler gibi biyolojideki süreçleri açıklamak için kullandı. Web kaynaklarının içeriğini optimize etmek ve iyileştirmek için bugün aynı araçları kullanabiliriz. Bu analiz araçlarının, yaratıldıkları sırada var olmayan nesnelerle çalışmak için kullanılabileceği gerçeği oldukça şaşırtıcı görünüyor. İnsanların en karmaşık hesaplamaları hesap makineleri veya bilgisayarlar olmadan yapmaları da aynı derecede şaşırtıcı.
Fischer, istatistiksel bir deneyin sonuçlarını, doğru olma olasılığı yüksek olarak tanımlamak için anlamlı kelimesini kullandı.
Ayrıca Fischer'in en ilginç gelişmelerinden biri de "seksi oğul" hipotezi olarak adlandırılabilir. Bu teoriye göre, kadınlar tercihlerini rastgele erkeklere (yürümeye) verirler, çünkü bu, bu erkeklerden doğan oğulların aynı yatkınlığa sahip olmasına ve daha fazla yavru doğurmasına izin verecektir (bunun sadece bir teori olduğunu unutmayın).
Ama hiç kimse, hatta parlak bilim adamları bile hata yapmaktan muaf değildir. Fischer'in kusurları uzmanları bugüne kadar rahatsız ediyor. Ama Albert Einstein'ın sözlerini hatırlayın: "Hiç yanılmayan, yeni bir şey yaratmadı."
Bir sonraki noktaya geçmeden önce, istatistiksel anlamlılığın, test sonuçlarındaki farkın o kadar büyük olduğu ve farkın rastgele faktörlerin etkisiyle açıklanamayacağı bir durum olduğunu unutmayın.
Hipoteziniz nedir?
"İstatistiksel anlamlılığın" ne anlama geldiğini anlamak için, önce "hipotez testinin" ne olduğunu anlamanız gerekir, çünkü iki terim birbiriyle yakından iç içe geçmiştir.
Bir hipotez sadece bir teoridir. Herhangi bir teori geliştirdikten sonra, yeterli miktarda kanıt toplamak için bir prosedür oluşturmanız ve aslında bu kanıtı toplamanız gerekecektir. İki tür hipotez vardır.

Elma veya portakal - hangisi daha iyi?
Sıfır hipotezi
Kural olarak, bu yerde birçoklarının zorlukları var. Boş hipotezin kanıtlanması gereken bir şey olmadığı unutulmamalıdır, örneğin, sitedeki belirli bir değişikliğin dönüşümlerde artışa yol açacağını, ancak bunun tersini kanıtlamış olursunuz. Boş hipotez, sitede herhangi bir değişiklik yaptığınızda hiçbir şeyin olmayacağı teorisidir. Ve araştırmacının amacı bu teoriyi kanıtlamak değil, çürütmektir.
Araştırmacıların failin kim olduğu konusunda da hipotezler kurduğu suç çözme deneyimine dönersek, boş hipotez sözde masumiyet karinesi şeklini alır, bu kavram, sanığın mahkemede suçlu olduğu kanıtlanana kadar masum kabul edilir. .
Boş hipotez, iki nesnenin özelliklerinde eşit olduğu şeklindeyse ve bunlardan birinin daha iyi olduğunu kanıtlamaya çalışıyorsanız (örneğin, A, B'den daha iyidir), boş hipotezi bir alternatif lehine terk etmeniz gerekir. bir. Örneğin, bir veya başka bir dönüşüm optimizasyon aracını karşılaştırıyorsunuz. Sıfır hipotezinde, her ikisi de hedef üzerinde aynı etkiye sahiptir (veya hiç etkisi yoktur). Alternatif olarak, birinin etkisi daha iyidir.
Alternatif hipoteziniz sayısal bir değer içerebilir, örneğin B - A\u003e% 20. Bu durumda, boş hipotez ve alternatif aşağıdaki biçimi alabilir:

Alternatif bir hipotezin başka bir adı, araştırma hipotezidir, çünkü araştırmacı her zaman bu özel hipotezi kanıtlamakla ilgilenir.
İstatistiksel anlamlılık ve p değeri
Ronald Fischer ve onun istatistiksel anlamlılık kavramına geri dönelim.
Artık boş bir hipoteziniz ve alternatif bir hipoteziniz olduğuna göre, birini nasıl kanıtlayıp diğerini çürütebilirsiniz?
İstatistikler doğası gereği belirli bir popülasyonu (örneklem) incelemeyi içerdiğinden, elde ettiğiniz sonuçlardan asla% 100 emin olamazsınız. Açıklayıcı bir örnek: genellikle seçim sonuçları ön anketlerin sonuçlarından ve hatta çıkış havuzlarından farklılık gösterir.
Dr. Fisher, deneyinizin başarılı olup olmadığını anlamak için bir bölme çizgisi oluşturmak istedi. Güven endeksi böyle ortaya çıktı. İnandırıcılık, neyi “önemli” olarak gördüğümüzü neyin olmadığını söylemek için aldığımız seviyedir. Güven endeksi olan "p" 0.05 veya daha düşükse, sonuçlar güvenilirdir.
Merak etmeyin, aslında göründüğü kadar kafa karıştırıcı değil.

Gauss olasılık dağılımı. Kenarlarda - değişkenin daha az olası değerleri, merkezde - en olası olanlar. P skoru (yeşil gölgeli alan), gözlemlenen sonucun rastgele meydana gelme olasılığıdır.
Normal olasılık dağılımı (Gauss dağılımı), hepsinin bir temsilidir olası değerler grafikteki bazı değişkenler (yukarıdaki şekilde) ve frekansları. Araştırmanızı doğru yaparsanız ve aldığınız tüm cevapları bir grafiğe çizerseniz, bu dağılımı elde edersiniz. Normal dağılıma göre, benzer yanıtların büyük bir yüzdesini alacaksınız ve kalan seçenekler grafiğin kenarlarında ("kuyruklar" olarak adlandırılır) yer alacaktır. Bu tür miktar dağılımı genellikle doğada bulunur, bu nedenle buna "normal" denir.
Örneğinize ve test sonuçlarına dayalı bir denklem kullanarak, sonuçların ne kadar değiştiğini gösteren "test istatistikleri" olarak adlandırılanları hesaplayabilirsiniz. Aynı zamanda boş hipotezi doğru yapmaya ne kadar yakın olduğunuzu da söyleyecektir.
Başınızı eğmek için, istatistiksel önemi hesaplamak için çevrimiçi hesap makinelerini kullanın:

Bu tür hesap makinelerine bir örnek
"P" harfi, sıfır hipotezinin doğru olma olasılığını gösterir. Küçük bir sayı, test grupları arasında bir fark olduğunu gösterirken, sıfır hipotezi aynı oldukları şeklindedir. Grafiksel olarak, test istatistiğiniz çan şeklindeki dağılımınızın kuyruklarından birine daha yakın gibi görünecektir.
Dr. Fisher sonuçların güvenilirliği için eşiği p 0,05 olarak belirlemeye karar verdi. Ancak bu ifade, iki zorluğa yol açtığı için de tartışmalıdır:
1. Öncelikle, boş hipotezin geçersiz olduğunu kanıtlamış olmanız, alternatif hipotezi kanıtladığınız anlamına gelmez. Bütün bu önem, A ya da B'yi ispatlayamayacağınız anlamına gelir.
2. İkinci olarak, eğer p-skoru 0.049 ise, bu boş hipotez olasılığının% 4.9 olduğu anlamına gelir. Bu, test sonuçlarınızın aynı anda hem geçerli hem de hatalı olabileceği anlamına gelebilir.
Bir p-üssü kullanabilirsin veya reddedebilirsin, ama sonra her ikisinde de ihtiyacın olacak özel durum boş hipotezin gerçekleştirilme olasılığını hesaplayın ve planladığınız ve test ettiğiniz değişiklikleri yapmamak için yeterince büyük olup olmadığına karar verin.
Bugün istatistiksel bir test yürütmenin en yaygın senaryosu, testin kendisini çalıştırmadan önce p 0,05'lik bir anlamlılık eşiği ayarlamaktır. Sonuçları kontrol ederken p-değerine dikkatlice bakmayı unutmayın.
Hata 1 ve 2
İstatistiksel anlamlılık göstergesini kullanırken oluşabilecek hataların kendi adlarına bile sahip olduğu çok uzun zaman olmuştur.
Hata 1 (Tip 1 Hataları)
Yukarıda bahsedildiği gibi, 0,05'lik bir p değeri, boş hipotezin doğru olma olasılığının% 5 olduğu anlamına gelir. Eğer onu terk ederseniz, 1 numaralı hatayı yapacaksınız. Sonuçlar, yeni web sitenizin dönüşüm oranlarını artırdığını söylüyor, ancak% 5'lik bir olasılık yok.
Hata 2 (Tip 2 Hataları)
Bu hata, 1. hatanın tersidir: yanlış olduğu halde boş hipotezi kabul edersiniz. Örneğin, test sonuçları size sitede yapılan değişikliklerin herhangi bir iyileştirme getirmediğini, ancak değişiklikler yapıldığını söyler. Sonuç olarak, performansınızı iyileştirme fırsatını kaçırıyorsunuz.
Bu hata, az örneklenmiş testlerde yaygındır, bu nedenle unutmayın: örnek ne kadar büyükse, sonuç o kadar güvenilirdir.
Sonuç
Belki de araştırmacılar arasında başka hiçbir terim istatistiksel anlamlılık kadar popüler değildir. Test sonuçları istatistiksel olarak önemli görülmediğinde, sonuçlar çok farklı olabilir: dönüşüm oranlarındaki artıştan şirketin çöküşüne kadar.
Pazarlamacılar varlıklarını optimize ederken bu terimi kullandıklarından, gerçekte ne anlama geldiğini bilmeniz gerekir. Test koşulları değişebilir, ancak örnek boyutu ve başarı kriterleri her zaman önemlidir. Hatırla bunu.
İstatistiksel anlamlılık veya p-anlamlılık seviyesi ana test sonucudur
istatistiksel hipotez. Konuşuyorum teknik dil, bu verileni alma olasılığıdır
örnek bir çalışmanın sonucu, aslında genel olarak
popülasyon, boş istatistiksel hipotez doğrudur - yani ilişki yoktur. Başka bir deyişle,
keşfedilen ilişkinin rastgele olması ve bir özellik olmaması olasılığı
toplam. Bu istatistiksel anlamlılıktır, p-anlamlılık seviyesi
ölçmek iletişim güvenilirliği: bu olasılık ne kadar azsa, iletişim o kadar güvenilirdir.
Diyelim ki, iki örnek aracı karşılaştırırken, seviyenin değeri elde edildi
istatistiksel anlamlılık p \u003d 0.05. Bu, ilgili istatistiksel hipotezi test etmek anlamına gelir.
genel popülasyondaki araçların eşitliği, eğer doğruysa, olasılığın
tespit edilen farklılıkların rastgele oluşması% 5'ten fazla değildir. Başka bir deyişle, eğer
aynı genel popülasyondan tekrar tekrar iki örnek alındı, ardından
20 vaka, bu numunelerin ortalamaları arasında aynı veya daha büyük farkı gösterecektir.
Yani, bulunan farklılıkların rastgele olma olasılığı% 5'dir.
karakterdir ve bütünlüğün bir özelliği değildir.
Bir ilişkide bilimsel hipotez istatistiksel anlamlılık düzeyi niceldir
sonuçlardan hesaplanan, bir bağlantının varlığına ilişkin sonuca güvensizlik derecesinin göstergesi
bu hipotezin seçici, ampirik testi. P-seviyesi değeri ne kadar düşükse, o kadar yüksek
bilimsel hipotezi doğrulayan araştırma sonucunun istatistiksel önemi.
Önem düzeyini neyin etkilediğini bilmek faydalıdır. Önem seviyesi, diğer şeyler eşittir
aşağıdaki durumlarda daha yüksek koşullar (p-seviye değeri daha düşüktür):
Bağlantı miktarı (fark) daha fazladır;
Özellik (ler) in değişkenliği daha azdır;
Örnek boyutu (örnekler) daha büyüktür.
Tek taraflıepi ve iki taraflı anlamlılık testi kriterleri
Çalışmanın amacı, iki genel parametrelerdeki farkı belirlemekse
çeşitli doğal koşullarına karşılık gelen koleksiyonlar ( yaşam koşulları,
deneklerin yaşı vb.), o zaman bu parametrelerden hangisinin daha yüksek olacağı genellikle bilinmez ve
hangisi daha az.
Örneğin, kontroldeki sonuçların değişkenliğiyle ilgileniyorsanız ve
deneysel gruplar, o zaman, kural olarak, varyans farkının işaretine güven yoktur veya
standart sapma değişkenliğin değerlendirildiği sonuçlar. Bu durumda
boş hipotez, varyansların eşit olmasıdır ve çalışmanın amacı
tersini kanıtlayın, yani varyanslar arasındaki fark. Dahası, varsayılmaktadır ki
fark herhangi bir işaret olabilir. Bu tür hipotezlere iki taraflı denir.
Ancak bazen zorluk, bir parametrede bir artış veya azalma olduğunu kanıtlamaktır;
örneğin, deney grubundaki ortalama sonuç kontrol grubundakinden daha yüksektir. Nerede
artık farkın başka bir işaret olabileceği kabul edilmiyor. Bu tür hipotezler denir
Tek taraflı.
İki taraflı hipotezleri test etmek için kullanılan önem kriterleri denir
İkili ve tek taraflı - tek taraflı.
Soru şu veya bu durumda kriterlerden hangisinin seçilmesi gerektiği konusunda ortaya çıkar. Cevap
Bu soru resminin ötesinde istatistiksel yöntemler ve tamamen
Çalışmanın amaçlarına bağlıdır. Hiçbir durumda bir veya daha fazla kriter seçilmemelidir.
Olabildiğince deneysel verilerin analizine dayalı bir deney yapmak
Yanlış sonuçlara varın. Deneyden önce farkın
Karşılaştırılan parametreler pozitif veya negatif olabilir, ardından takip eder