Temat nr 11
W praktyce do określenia zmiennych losowych ogólna perspektywa zwykle używana jest funkcja dystrybucji.
Prawdopodobieństwo, że wartość losowa X przyjmie określoną wartość x 0, wyrażoną dystrybuantą zgodnie ze wzorem
R (X = x 0) = F(x 0 +0) – F(x 0).(3)
W szczególności, jeśli w punkcie x = x 0 funkcja F(x) jest ciągła, to
R (X = x 0) = 0.
Losowa wartość X z dystrybucją rocznie) nazywa się dyskretnym, jeśli na osi liczbowej istnieje skończony lub policzalny zbiór W taki, że R(W,) = 1.
Niech W = ( x 1 , x 2 ,…) I Liczba Pi= P({x ja}) = P(X = x ja), I= 1,2,….Wtedy dla dowolnego zbioru borelowskiego A prawdopodobieństwo rocznie) jest określona jednoznacznie przez wzór
Wprowadzając tę formułę A = (x ja / x ja< x}, x Î R , otrzymujemy wzór na dystrybuantę F(x) Dyskretna zmienna losowa X:
F(x) = P(X < X) =. (5)
Wykres funkcji F(x) jest linią schodkową. Funkcja przeskakuje F(x) w punktach x = x 1, x 2…(x 1
Przykład 1: Znajdź funkcję dystrybucji
dyskretna zmienna losowa x z Przykładu 1 § 13.
Korzystając z funkcji rozkładu, oblicz
prawdopodobieństwo zdarzeń: x< 3, 1 £ x < 4, 1 £ x £ 3.

|
|
otrzymane w § 13 i wzór (5) otrzymujemy
funkcja dystrybucyjna:

Zgodnie ze wzorem (1) Р(x< 3) = F(3) = 0,1808; по формуле (2)
p(1 £ x< 4) = F (4) – F(1) = 0,5904 – 0,0016 = 0,5888;
p (1 £ x 3 £) = p (1 £ x<3) + p(x = 3) = F(3) – F(1) + F(3+0) – F(3) =
F(3+0) – F(1) = 0,5904 – 0,0016 = 0,5888.
Przykład 2. Podana funkcja

Czy funkcja F(x) jest dystrybuantą jakiejś zmiennej losowej? Jeśli odpowiedź brzmi tak, znajdź ![]() . Narysuj wykres funkcji F(x).
. Narysuj wykres funkcji F(x).
Rozwiązanie. Aby z góry określona funkcja F(x) była dystrybuantą jakiejś zmiennej losowej x, konieczne i wystarczające jest spełnienie następujących warunków (charakterystycznych właściwości funkcji dystrybuanty):
1.  F(x) jest funkcją niemalejącą.
F(x) jest funkcją niemalejącą.
3. Dla dowolnego x О R F( X– 0) = F( X).
Dla danej funkcji F(x), wykonanie
przesłanki te są oczywiste. Oznacza,
F(x) – dystrybuanta.
Prawdopodobieństwo  obliczyć według
obliczyć według
wzór (2):
Wykres funkcji F( X) przedstawiono na rysunku 13.
Przykład 3. Niech F 1 ( X) i F 2 ( X) – funkcje rozkładu zmiennych losowych X 1 i X 2 odpowiednio, A 1 i A 2 to liczby nieujemne, których suma wynosi 1.
Udowodnić, że F( X) = A 1 F 1 ( X) + A 2 F 2 ( X) jest dystrybuantą pewnej zmiennej losowej X.
Rozwiązanie. 1) Ponieważ F 1 ( X) i F 2 ( X) są funkcjami niemalejącymi i A 1 ł 0, A Zatem 2 ³ 0 A 1 F 1 ( X) I A 2 F 2 ( X) są niemalejące, dlatego ich suma F( X) również nie maleje.
3) Dla dowolnego x О R F( X - 0) = A 1 F 1 ( X - 0) + A 2 F 2 ( X - 0)= A 1 F 1 ( X) + A 2 F 2 ( X) = F( X).
Przykład 4. Podana funkcja

Czy F(x) jest dystrybuantą zmiennej losowej?
Rozwiązanie. Łatwo zauważyć, że F(1) = 0,2 > 0,11 = F(1,1). Dlatego F( X) nie jest niemalejący, a zatem nie jest funkcją rozkładu zmiennej losowej. Należy zauważyć, że pozostałe dwie właściwości obowiązują dla tej funkcji.
Zadanie testowe nr 11
1. Dyskretna zmienna losowa X
X) i korzystając z niego znaleźć prawdopodobieństwa zdarzeń: a) –2 £ X < 1; б) ½X½£ 2. Narysuj wykres funkcji rozkładu.
3. Dyskretna zmienna losowa X podane przez tablicę rozkładów:
| x ja | |||||
| Liczba Pi | 0,05 | 0,2 | 0,3 | 0,35 | 0,1 |
Znajdź funkcję rozkładu F( X) i znajdź prawdopodobieństwa następujących zdarzeń: a) X < 2; б) 1 £ X < 4; в) 1 £ X 4 GBP; d) 1< X 4 GBP; D) X = 2,5.
4. Znajdź dystrybuantę dyskretnej zmiennej losowej X, równa liczbie punktów zdobytych podczas jednego rzutu kostką. Korzystając z funkcji rozkładu, znajdź prawdopodobieństwo wyrzucenia co najmniej 5 punktów.
5. Przeprowadzane są kolejne badania niezawodności 5 urządzeń. Każde kolejne urządzenie jest testowane tylko wtedy, gdy poprzednie okazało się niezawodne. Utwórz tabelę rozkładu i znajdź funkcję rozkładu losowej liczby testów urządzeń, jeśli prawdopodobieństwo zaliczenia testów dla każdego urządzenia wynosi 0,9.
6. Podano dystrybuantę dyskretnej zmiennej losowej X:

a) Znajdź prawdopodobieństwo zdarzenia 1 £ X 3 funty.
b) Znajdź tablicę rozkładu zmiennej losowej X.
7. Podano dystrybuantę dyskretnej zmiennej losowej X:

Zrób tabelę rozkładu tej zmiennej losowej.
8. Rzut monetą N raz. Utwórz tabelę rozkładu i znajdź funkcję rozkładu liczby wystąpień herbu. Wykreśl funkcję rozkładu w punkcie N = 5.
9. Monetę rzucamy do momentu pojawienia się herbu. Utwórz tabelę rozkładu i znajdź funkcję rozkładu liczby wystąpień cyfry.
10. Snajper strzela do celu aż do pierwszego trafienia. Prawdopodobieństwo chybienia przy pojedynczym strzale jest równe R. Znajdź dystrybuantę liczby chybień.
1.2.4. Zmienne losowe i ich rozkłady
Rozkłady zmiennych losowych i funkcje rozkładu. Rozkład numerycznej zmiennej losowej to funkcja, która w jednoznaczny sposób określa prawdopodobieństwo, że zmienna losowa przyjmie daną wartość lub będzie należeć do określonego przedziału.
Po pierwsze, zmienna losowa przyjmuje skończoną liczbę wartości. Następnie rozkład jest dany przez funkcję P(X = x), przypisanie każdej możliwej wartości X zmienna losowa X prawdopodobieństwo, że X = x.
Po drugie, zmienna losowa przyjmuje nieskończenie wiele wartości. Jest to możliwe tylko wtedy, gdy przestrzeń probabilistyczna, na której zdefiniowana jest zmienna losowa, składa się z nieskończonej liczby zdarzeń elementarnych. Następnie rozkład jest dany przez zbiór prawdopodobieństw Rocznie <
X
Rocznie <
X
Zależność ta pokazuje, że zarówno rozkład można obliczyć z funkcji dystrybucji, jak i odwrotnie, funkcję rozkładu można obliczyć z rozkładu.
Używane w probabilistyce metody statystyczne podejmowanie decyzji i inne badania stosowane Funkcje rozkładu są albo dyskretne, albo ciągłe, albo ich kombinacje.
Dystrybuanty dyskretne odpowiadają dyskretnym zmiennym losowym, które przyjmują skończoną liczbę wartości lub wartości ze zbioru, którego elementy można ponumerować liczbami naturalnymi (takie zbiory nazywane są w matematyce policzalnymi). Ich wykres wygląda jak drabina schodkowa (ryc. 1).
Przykład 1. Numer X wadliwe elementy w partii przyjmują wartość 0 z prawdopodobieństwem 0,3, wartość 1 z prawdopodobieństwem 0,4, wartość 2 z prawdopodobieństwem 0,2 i wartość 3 z prawdopodobieństwem 0,1. Wykres funkcji rozkładu zmiennej losowej X pokazano na ryc. 1.
Ryc.1. Wykres funkcji rozkładu liczby wadliwych produktów.
Funkcje rozkładu ciągłego nie mają skoków. Zwiększają się monotonicznie wraz ze wzrostem argumentu - od 0 do 1 w . Zmienne losowe posiadające rozkład ciągły nazywane są ciągłymi.
Funkcje rozkładu ciągłego stosowane w probabilistyczno-statystycznych metodach podejmowania decyzji mają pochodne. Pierwsza pochodna k(x) funkcje dystrybucji F(x) nazywa się gęstością prawdopodobieństwa,
Korzystając z gęstości prawdopodobieństwa, możesz wyznaczyć funkcję rozkładu:
![]()
Dla dowolnej funkcji rozkładu
Wymienione właściwości funkcji rozkładu są stale wykorzystywane w probabilistycznych i statystycznych metodach podejmowania decyzji. W szczególności ostatnia równość implikuje specyficzną formę stałych we wzorach na gęstości prawdopodobieństwa rozważanych poniżej.
Przykład 2. Często używana jest następująca funkcja rozkładu:
 (1)
(1)
Gdzie A I B– kilka liczb, A . Znajdźmy gęstość prawdopodobieństwa tej funkcji rozkładu:

(w punktach x = a I x = b pochodna funkcji F(x) nie istnieje).
Zmienna losowa posiadająca dystrybuantę (1) nazywana jest „równomiernie rozłożoną na przedziale [ A; B]».
Mieszane funkcje rozkładu występują w szczególności wtedy, gdy obserwacje zatrzymują się w pewnym momencie. Na przykład podczas analizy danych statystycznych uzyskanych w wyniku wykorzystania planów testów niezawodności, które przewidują zakończenie testów po pewnym czasie. Lub przy analizie danych o produktach technicznych wymagających napraw gwarancyjnych.
Przykład 3. Niech na przykład żywotność żarówki elektrycznej będzie zmienną losową z funkcją rozkładu F(t), i badanie prowadzi się do momentu przepalenia się żarówki, jeżeli nastąpi to w czasie krótszym niż 100 godzin od rozpoczęcia badania, lub do czasu t 0= 100 godzin. Pozwalać G(t)– rozkład czasu pracy żarówki w dobrym stanie podczas tego testu. Następnie

Funkcjonować G(t) ma skok w pewnym momencie t 0, ponieważ odpowiednia zmienna losowa przyjmuje wartość t 0 z prawdopodobieństwem 1- F(t0)> 0.
Charakterystyka zmiennych losowych. W probabilistyczno-statystycznych metodach podejmowania decyzji wykorzystuje się szereg charakterystyk zmiennych losowych, wyrażanych za pomocą funkcji rozkładu i gęstości prawdopodobieństwa.
Przy opisie zróżnicowania dochodów, przy wyznaczaniu granic ufności dla parametrów rozkładów zmiennych losowych i w wielu innych przypadkach posługuje się pojęciem „kwantyla rzędu”. R", gdzie 0< P < 1 (обозначается x s). Zamów kwantyl R– wartość zmiennej losowej, dla której funkcja rozkładu przyjmuje wartość R lub następuje „skok” od wartości mniejszej R do wartości większej R(ryc. 2). Może się zdarzyć, że warunek ten będzie spełniony dla wszystkich wartości x należących do tego przedziału (czyli dystrybuanta jest na tym przedziale stała i wynosi R). Wówczas każdą taką wartość nazywamy „kwantylem porządku” R" W przypadku funkcji rozkładu ciągłego z reguły istnieje jeden kwantyl x s zamówienie R(ryc. 2) i
F(x p) = p. (2)

Ryc.2. Definicja kwantyla x s zamówienie R.
Przykład 4. Znajdźmy kwantyl x s zamówienie R dla funkcji dystrybucji F(x) od 1).
O godzinie 0< P < 1 квантиль x s wynika z równania
te. x s = za + p(b – a) = a( 1- p) +bp. Na P= 0 dowolne X < A jest kwantylem porządku P= 0. Kwantyl porządku P= 1 to dowolna liczba X > B.
W przypadku dystrybucji dyskretnych z reguły nie ma x s, spełniające równanie (2). Dokładniej, jeśli rozkład zmiennej losowej podano w tabeli 1, gdzie x 1< x 2 < … < x k , następnie równość (2), rozpatrywana jako równanie ze względu na x s, zawiera rozwiązania tylko dla k wartości P, mianowicie,
p = p 1 ,
p = p 1 + p 2 ,
p = p 1 + p 2 + p 3 ,
p = p 1 + p 2 + …+ po południu, 3 < M < k,
P = P 1 + P 2 + … + p.k.
Tabela 1.
Rozkład dyskretnej zmiennej losowej
Dla wymienionych k wartości prawdopodobieństwa P rozwiązanie x s równanie (2) nie jest unikalne, mianowicie
F(x) = p 1 + p 2 + … + p m
dla wszystkich X takie, że x m< x < x m+1 . Te. x p – dowolna liczba z przedziału (x m; x m+1]. Dla wszystkich innych R z przedziału (0;1), nieujętego na liście (3), następuje „skok” od wartości mniejszej R do wartości większej R. Mianowicie, jeśli
p 1 + p 2 + … + p m
To x p = x m+1.
Rozważana właściwość rozkładów dyskretnych stwarza znaczne trudności podczas zestawiania i stosowania takich rozkładów, ponieważ niemożliwe jest dokładne zachowanie typowych wartości liczbowych charakterystyk rozkładu. W szczególności dotyczy to wartości krytycznych i poziomów istotności nieparametrycznych testów statystycznych (patrz poniżej), ponieważ rozkłady statystyk tych testów są dyskretne.
Kolejność kwantylowa ma ogromne znaczenie w statystyce R= ½. Nazywa się to medianą (zmienna losowa X lub jego funkcja dystrybucji F(x)) i jest wyznaczony Ja(X). W geometrii istnieje pojęcie „środkowej” - linii prostej przechodzącej przez wierzchołek trójkąta i dzielącej jego przeciwny bok na pół. W statystyce matematycznej mediana dzieli na pół nie bok trójkąta, ale rozkład zmiennej losowej: równość F(x 0,5)= 0,5 oznacza prawdopodobieństwo dostania się w lewo x 0,5 i prawdopodobieństwo dotarcia w prawo x 0,5(lub bezpośrednio do x 0,5) są sobie równe i równe ½, tj.
P(X < X 0,5) = P(X > X 0,5) = ½.
Mediana wskazuje „centrum” rozkładu. Z punktu widzenia jednej ze współczesnych koncepcji – teorii stabilnych procedur statystycznych – mediana jest lepszą charakterystyką zmiennej losowej niż wartość oczekiwana. Podczas przetwarzania wyników pomiarów na skali porządkowej (patrz rozdział o teorii pomiaru) można zastosować medianę, ale nie można zastosować oczekiwań matematycznych.
Cecha zmiennej losowej taka jak mod ma jasne znaczenie - wartość (lub wartości) zmiennej losowej odpowiadająca lokalnemu maksimum gęstości prawdopodobieństwa dla ciągłej zmiennej losowej lub lokalnemu maksimum prawdopodobieństwa dla dyskretnej zmiennej losowej .
Jeśli x 0– postać zmiennej losowej z gęstością f(x), wówczas, jak wiadomo z rachunku różniczkowego, .
Zmienna losowa może mieć wiele postaci. Zatem dla równomiernego rozkładu (1) każdy punkt X takie, że A< x < b , jest moda. Jest to jednak wyjątek. Większość zmiennych losowych stosowanych w probabilistycznych statystycznych metodach podejmowania decyzji i innych badaniach stosowanych ma jeden tryb. Zmienne losowe, gęstości i rozkłady posiadające jeden tryb nazywane są unimodalnymi.
Oczekiwanie matematyczne dla dyskretnych zmiennych losowych o skończonej liczbie wartości zostało omówione w rozdziale „Zdarzenia i prawdopodobieństwa”. Dla ciągłej zmiennej losowej X wartość oczekiwana M(X) spełnia równość
![]()
co jest analogią wzoru (5) ze stwierdzenia 2 rozdziału „Zdarzenia i prawdopodobieństwa”.
Przykład 5. Oczekiwanie na równomiernie rozłożoną zmienną losową X równa się
W przypadku zmiennych losowych rozpatrywanych w tym rozdziale wszystkie właściwości oczekiwań matematycznych i wariancji, które rozważano wcześniej dla dyskretnych zmiennych losowych o skończonej liczbie wartości, są prawdziwe. Nie przedstawiamy jednak dowodu na te właściwości, ponieważ wymagają one zagłębienia się w subtelności matematyczne, co nie jest konieczne do zrozumienia i kwalifikowanego zastosowania probabilistyczno-statystycznych metod podejmowania decyzji.
Komentarz. Podręcznik ten świadomie unika subtelności matematycznych, związanych w szczególności z pojęciami zbiorów mierzalnych i funkcji mierzalnych, algebry zdarzeń itp. Pragnący opanować te pojęcia powinni sięgnąć po literaturę specjalistyczną, w szczególności encyklopedię.
Każda z trzech cech – oczekiwanie matematyczne, mediana, moda – opisuje „środek” rozkładu prawdopodobieństwa. Pojęcie „centrum” można definiować na różne sposoby – stąd trzy różne cechy. Jednak w przypadku ważnej klasy rozkładów – symetrycznych unimodalnych – wszystkie trzy cechy są zbieżne.
Gęstość dystrybucji k(x)– gęstość rozkładu symetrycznego, jeśli istnieje liczba x 0 takie, że
![]() . (3)
. (3)
Równość (3) oznacza, że wykres funkcji y = f(x) symetryczny względem linii pionowej przechodzącej przez środek symetrii X = X 0. Z (3) wynika, że rozkład symetryczny spełnia zależność
![]() (4)
(4)
W przypadku rozkładu symetrycznego z jedną modą oczekiwanie matematyczne, mediana i moda pokrywają się i są równe x 0.
Najważniejszym przypadkiem jest symetria wokół 0, tj. x 0= 0. Wtedy (3) i (4) stają się równościami
![]() (6)
(6)
odpowiednio. Powyższe zależności pokazują, że nie ma potrzeby zestawiania rozkładów symetrycznych dla wszystkich X, wystarczy mieć stoliki przy X > x 0.
Zwróćmy uwagę na jeszcze jedną właściwość rozkładów symetrycznych, która jest stale wykorzystywana w probabilistyczno-statystycznych metodach podejmowania decyzji i innych badaniach stosowanych. Dla funkcji rozkładu ciągłego
P(|X| < a) = P(-a < X < a) = F(a) – F(-a),
Gdzie F– dystrybuanta zmiennej losowej X. Jeśli funkcja dystrybucji F jest symetryczny względem 0, tj. wówczas obowiązuje dla niego wzór (6).
P(|X| < a) = 2F(a) – 1.
Często używane jest inne sformułowanie omawianego stwierdzenia: jeśli
![]() .
.
Jeżeli i są kwantylami rzędu i odpowiednio (patrz (2)) funkcji rozkładu symetrycznej wokół 0, to z (6) wynika, że
Z charakterystyki pozycji – oczekiwanie matematyczne, mediana, moda – przejdźmy do charakterystyki rozrzutu zmiennej losowej X: wariancja, odchylenie standardowe i współczynnik zmienności w. Definicja i właściwości dyspersji dyskretnych zmiennych losowych zostały omówione w poprzednim rozdziale. Dla ciągłych zmiennych losowych
Odchylenie standardowe to nieujemna wartość pierwiastka kwadratowego wariancji:
Współczynnik zmienności to stosunek odchylenia standardowego do oczekiwań matematycznych:
Współczynnik zmienności stosuje się, gdy M(X)> 0. Mierzy rozrzut w jednostkach względnych, podczas gdy odchylenie standardowe jest wyrażone w jednostkach bezwzględnych.
Przykład 6. Dla równomiernie rozłożonej zmiennej losowej X Znajdźmy dyspersję, odchylenie standardowe i współczynnik zmienności. Wariancja wynosi:

Zmiana zmiennej umożliwia zapis:
Gdzie C = (B – A)/ 2. Zatem odchylenie standardowe jest równe, a współczynnik zmienności wynosi:
Dla każdej zmiennej losowej X określ jeszcze trzy wielkości - wyśrodkowane Y, znormalizowany V i dane U. Wyśrodkowana zmienna losowa Y jest różnicą między daną zmienną losową X i jego matematyczne oczekiwanie M(X), te. Y = X – M(X). Oczekiwanie wyśrodkowanej zmiennej losowej Y równa się 0, a wariancja jest wariancją danej zmiennej losowej: M(Y) = 0, D(Y) = D(X). Funkcja dystrybucyjna F Y(X) wyśrodkowana zmienna losowa Y związane z funkcją dystrybucji F(X) pierwotna zmienna losowa X stosunek:
F Y(X) = F(X + M(X)).
Gęstości tych zmiennych losowych spełniają równość
dla Y(X) = F(X + M(X)).
Znormalizowana zmienna losowa V jest stosunkiem danej zmiennej losowej X do odchylenia standardowego, tj. . Oczekiwanie i wariancja znormalizowanej zmiennej losowej V wyrażone poprzez cechy X Więc:
![]() ,
,
Gdzie w– współczynnik zmienności pierwotnej zmiennej losowej X. Dla funkcji dystrybucji F V(X) i gęstość f V(X) znormalizowana zmienna losowa V mamy:
Gdzie F(X) – rozkład pierwotnej zmiennej losowej X, A F(X) – jego gęstość prawdopodobieństwa.
Zredukowana zmienna losowa U jest wyśrodkowaną i znormalizowaną zmienną losową:
![]() .
.
Dla danej zmiennej losowej
Znormalizowane, wyśrodkowane i zredukowane zmienne losowe są stale wykorzystywane zarówno w badaniach teoretycznych, jak i w algorytmach, oprogramowaniu, dokumentacji regulacyjnej, technicznej i instruktażowej. W szczególności ze względu na równości ![]() umożliwiają uproszczenie uzasadniania metod, formułowania twierdzeń i wzorów obliczeniowych.
umożliwiają uproszczenie uzasadniania metod, formułowania twierdzeń i wzorów obliczeniowych.
Stosuje się transformacje zmiennych losowych i bardziej ogólne. Więc jeśli Y = topór + B, Gdzie A I B– w takim razie kilka liczb
Przykład 7. Jeśli następnie Y jest zredukowaną zmienną losową, a wzory (8) przekształcają się we wzory (7).
Z każdą zmienną losową X możesz powiązać wiele zmiennych losowych Y, dane ze wzoru Y = topór + B w różnych A> 0 i B. Zestaw ten nazywa się rodzina z przesunięciem skali, generowane przez zmienną losową X. Funkcje dystrybucji F Y(X) stanowią rodzinę rozkładów z przesunięciem skali generowaną przez funkcję dystrybucji F(X). Zamiast Y = topór + B często korzystaj z nagrywania
![]()
Numer Z nazywa się parametrem przesunięcia i liczbą D- parametr skali. Pokazuje to wzór (9). X– wynik pomiaru określonej wielkości – trafia do U– wynik pomiaru tej samej wielkości w przypadku przesunięcia początku pomiaru do punktu Z, a następnie użyj nowej jednostki miary, in D razy większy od starego.
Dla rodziny przesunięć skali (9) rozkład X nazywany jest standardem. W probabilistycznych statystycznych metodach podejmowania decyzji i innych badaniach stosowanych stosuje się standardowy rozkład normalny, standardowy rozkład Weibulla-Gnedenko, standardowy rozkład gamma itp. (patrz poniżej).
Stosowane są również inne transformacje zmiennych losowych. Na przykład dla dodatniej zmiennej losowej X rozważają Y= log X, gdzie lg X– logarytm dziesiętny liczby X. Łańcuch równości
F Y (x) = P( lg X< x) = P(X < 10x) = F( 10X)
łączy funkcje dystrybucyjne X I Y.
Podczas przetwarzania danych wykorzystywane są następujące cechy zmiennej losowej X jako chwile porządku Q, tj. oczekiwania matematyczne wobec zmiennej losowej Xk, Q= 1, 2, ... Zatem samo oczekiwanie matematyczne jest momentem porządku 1. W przypadku dyskretnej zmiennej losowej momentem porządku Q można obliczyć jako
![]()
Dla ciągłej zmiennej losowej
![]()
Chwile porządku Q zwane także początkowymi momentami porządku Q, w przeciwieństwie do pokrewnych cech - centralne momenty porządku Q, podane przez wzór
Zatem dyspersja jest centralnym momentem rzędu 2.
Rozkład normalny i centralne twierdzenie graniczne. W probabilistyczno-statystycznych metodach podejmowania decyzji często mówimy o rozkładzie normalnym. Czasami próbują go wykorzystać do modelowania rozkładu danych wyjściowych (próby te nie zawsze są uzasadnione - patrz poniżej). Co ważniejsze, wiele metod przetwarzania danych opiera się na tym, że obliczone wartości mają rozkłady zbliżone do normalnych.
Pozwalać X 1 , X 2 ,…, X rz M(X ja) = M i odchylenia D(X ja) = , I = 1, 2,…, N,... Jak wynika z wyników poprzedniego rozdziału,
Rozważ zredukowaną zmienną losową U n za kwotę ![]() , mianowicie,
, mianowicie,
![]()
Jak wynika ze wzorów (7), M(U n) = 0, D(U n) = 1.
(dla warunków o identycznym rozkładzie). Pozwalać X 1 , X 2 ,…, X rz, … – niezależne zmienne losowe o jednakowym rozkładzie z oczekiwaniami matematycznymi M(X ja) = M i odchylenia D(X ja) = , I = 1, 2,…, N,... Wtedy dla dowolnego x istnieje granica
![]()
Gdzie F(x)– funkcja standardowa normalna dystrybucja.
Więcej o funkcji F(x) – poniżej (czytaj „fi od x”, ponieważ F- Grecka wielka litera „phi”).
Centralne twierdzenie graniczne (CLT) ma swoją nazwę, ponieważ jest centralnym, najczęściej używanym matematycznym wynikiem teorii prawdopodobieństwa i statystyki matematycznej. Historia CLT trwa około 200 lat – od roku 1730, kiedy to angielski matematyk A. Moivre (1667-1754) opublikował pierwszy wynik związany z CLT (patrz niżej o twierdzeniu Moivre’a-Laplace’a), aż do lat dwudziestych i trzydziestych XX wieku XX wieku, kiedy Finn J.W. Lindeberg, Francuz Paul Levy (1886-1971), Jugosławia V. Feller (1906-1970), Rosjanin A.Ya. Khinchin (1894-1959) i inni naukowcy uzyskali warunki konieczne i wystarczające dla ważności klasycznego centralnego twierdzenia granicznego.
Na tym nie zakończył się rozwój rozważanego tematu - badano zmienne losowe, które nie mają dyspersji, tj. ci dla kogo
![]()
(akademik B.V. Gnedenko i inni), sytuacja, gdy sumowane są zmienne losowe (a dokładniej elementy losowe) o bardziej złożonym charakterze niż liczby (naukowcy Yu.V. Prochorow, A.A. Borovkov i ich współpracownicy) itp. .d.
Funkcja dystrybucyjna F(x) jest dana przez równość
![]() ,
,
gdzie jest gęstość standardowego rozkładu normalnego, który ma dość złożone wyrażenie:
![]() .
.
Tutaj =3,1415925… jest liczbą znaną w geometrii, równą stosunkowi obwodu do średnicy, mi = 2,718281828... - podstawa logarytmów naturalnych (aby zapamiętać tę liczbę, należy pamiętać, że rok 1828 to rok urodzenia pisarza L.N. Tołstoja). Jak wiadomo z analizy matematycznej,
![]()
Podczas przetwarzania wyników obserwacji funkcja rozkładu normalnego nie jest obliczana za pomocą podanych wzorów, ale znajduje się za pomocą specjalnych tabel lub programów komputerowych. Najlepsze „Tabele statystyki matematycznej” w języku rosyjskim zostały opracowane przez odpowiednich członków Akademii Nauk ZSRR L.N. Bolszewa i N.V. Smirnowa.
Postać gęstości standardowego rozkładu normalnego wynika z teorii matematycznej, której nie możemy tutaj rozważać, a także z dowodu CLT.
Dla ilustracji podajemy małe tabele funkcji rozkładu F(x)(Tabela 2) i jej kwantyle (Tabela 3). Funkcjonować F(x) symetryczny wokół 0, co przedstawiono w tabeli 2-3.
Tabela 2.
Standardowa funkcja rozkładu normalnego.
Jeśli zmienna losowa X ma funkcję dystrybucji F(x), To M(X) = 0, D(X) = 1. To stwierdzenie zostało udowodnione w teorii prawdopodobieństwa w oparciu o rodzaj gęstości prawdopodobieństwa. Jest to spójne z podobnym stwierdzeniem dotyczącym charakterystyki zredukowanej zmiennej losowej U n, co jest całkiem naturalne, gdyż CLT stwierdza, że przy nieograniczonym wzroście liczby wyrazów funkcja dystrybucji U n zmierza do standardowej funkcji rozkładu normalnego F(x), i dla każdego X.
Tabela 3.
Kwantyle standardowego rozkładu normalnego.
Zamów kwantyl R |
Zamów kwantyl R |
||
Wprowadźmy pojęcie rodziny rozkładów normalnych. Z definicji rozkład normalny to rozkład zmiennej losowej X, dla którego rozkład zredukowanej zmiennej losowej wynosi F(x). Jak wynika z ogólnych właściwości rodzin rozkładów z przesunięciem skali (patrz wyżej), rozkład normalny jest rozkładem zmiennej losowej
Gdzie X– zmienna losowa z rozkładem F(X), I M = M(Y), = D(Y). Rozkład normalny z parametrami przesunięcia M i skala jest zwykle wskazana N(M, ) (czasami używana jest notacja N(M, ) ).
Jak wynika z (8), gęstość prawdopodobieństwa rozkładu normalnego N(M, ) Jest

Rozkłady normalne tworzą rodzinę z przesunięciem skali. W tym przypadku parametrem skali jest D= 1/ i parametr przesunięcia C = - M/ .
Dla momentów centralnych trzeciego i czwartego rzędu rozkładu normalnego obowiązują równości:
![]()
Równości te stanowią podstawę klasycznych metod sprawdzania, czy obserwacje mają rozkład normalny. Obecnie zwykle zaleca się badanie normalności za pomocą kryterium W Shapiro – Wilka. Problem testowania normalności omówiono poniżej.
Jeśli zmienne losowe X 1 I X2 mają funkcje dystrybucyjne N(M 1
, 1)
I N(M 2
, 2)
zatem odpowiednio X 1+ X2 ma dystrybucję ![]() Dlatego też, jeśli zmienne losowe X 1
,
X 2
,…,
X rz N(M, )
, a następnie ich średnia arytmetyczna
Dlatego też, jeśli zmienne losowe X 1
,
X 2
,…,
X rz N(M, )
, a następnie ich średnia arytmetyczna
![]()
ma dystrybucję N(M, ) . Te właściwości rozkładu normalnego są stale wykorzystywane w różnych probabilistycznych i statystycznych metodach podejmowania decyzji, w szczególności w statystycznej regulacji procesów technologicznych oraz w statystycznej kontroli akceptacji opartej na kryteriach ilościowych.
Korzystając z rozkładu normalnego, zdefiniowano trzy rozkłady, które są obecnie często stosowane w przetwarzaniu danych statystycznych.
Rozkład (chi – kwadrat) – rozkład zmiennej losowej
gdzie są zmienne losowe X 1 , X 2 ,…, X rz niezależne i mają ten sam rozkład N(0,1). W tym przypadku liczba terminów, tj. N, nazywana jest „liczbą stopni swobody” rozkładu chi-kwadrat.
Dystrybucja T T Studenta jest rozkładem zmiennej losowej
gdzie są zmienne losowe U I X niezależny, U ma standardowy rozkład normalny N(0,1) i X– rozkład chi – kwadrat c N stopnie swobody. W której N nazywana jest „liczbą stopni swobody” rozkładu Studenta. Podział ten wprowadził w 1908 roku angielski statystyk W. Gosset, który pracował w fabryce piwa. W tej fabryce przy podejmowaniu decyzji ekonomicznych i technicznych stosowano metody probabilistyczne i statystyczne, dlatego jej kierownictwo zabroniło V. Gossetowi publikowania artykułów naukowych pod własnym nazwiskiem. W ten sposób chroniono tajemnice przedsiębiorstwa oraz „know-how” w postaci metod probabilistycznych i statystycznych opracowanych przez V. Gosseta. Miał jednak okazję publikować pod pseudonimem „Student”. Historia Gosset-Student pokazuje, że przez kolejne sto lat menedżerowie w Wielkiej Brytanii byli świadomi większej efektywności ekonomicznej probabilistyczno-statystycznych metod podejmowania decyzji.
Rozkład Fishera to rozkład zmiennej losowej
gdzie są zmienne losowe X 1 I X2 są niezależne i mają rozkład chi-kwadrat z liczbą stopni swobody k 1 I k 2 odpowiednio. W tym samym czasie para (k 1 , k 2 ) – parę „stopni swobody” rozkładu Fishera, czyli: k 1 jest liczbą stopni swobody licznika, oraz k 2 – liczba stopni swobody mianownika. Rozkład zmiennej losowej F nosi imię wielkiego angielskiego statystyka R. Fishera (1890-1962), który aktywnie wykorzystywał go w swoich pracach.
Wyrażenia dla funkcji rozkładu chi-kwadrat, Studenta i Fishera, ich gęstości i charakterystyki, a także tabele można znaleźć w literaturze specjalistycznej (patrz na przykład).
Jak już wspomniano, rozkłady normalne są obecnie często stosowane w modelach probabilistycznych w różnych obszarach zastosowań. Jaki jest powód tak powszechnego rozpowszechnienia tej dwuparametrowej rodziny rozkładów? Wyjaśnia to następujące twierdzenie.
Centralne twierdzenie graniczne(dla terminów o różnym rozkładzie). Pozwalać X 1 , X 2 ,…, X rz,… - niezależne zmienne losowe z oczekiwaniami matematycznymi M(X 1 ), M(X 2 ),…, M(X n), ... i odchylenia D(X 1 ), D(X 2 ),…, D(X n), ... odpowiednio. Pozwalać
Następnie, jeśli spełnione są pewne warunki, które zapewniają niewielki udział któregokolwiek z terminów w U n,
![]()
dla kazdego X.
Nie będziemy tutaj formułować omawianych warunków. Można je znaleźć w literaturze specjalistycznej (patrz na przykład). „Wyjaśnienie warunków, w jakich działa CPT, jest zasługą wybitnych rosyjskich naukowców A.A. Markowa (1857–1922), a w szczególności A.M. Lapunowa (1857–1918)”.
Centralne twierdzenie graniczne pokazuje, że w przypadku, gdy wynik pomiaru (obserwacja) kształtuje się pod wpływem wielu przyczyn, z których każda ma niewielki udział, i określa się wynik całkowity dodatkowo, tj. przez dodanie, to rozkład wyniku pomiaru (obserwacji) jest zbliżony do normalnego.
Czasami uważa się, że aby rozkład był normalny wystarczy, że wynik pomiaru (obserwacji) X powstaje pod wpływem wielu przyczyn, z których każdy ma niewielki wpływ. To jest źle. Ważne jest, jak te przyczyny działają. Jeśli dodatek, to X ma w przybliżeniu rozkład normalny. Jeśli multiplikatywnie(tj. działania poszczególnych przyczyn są mnożone, a nie dodawane), a następnie podział X zbliżone nie do normalnego, ale do tzw. logarytmicznie normalne, tj. Nie X, a log X ma w przybliżeniu rozkład normalny. Jeśli nie ma powodu sądzić, że działa jeden z tych dwóch mechanizmów kształtowania się wyniku końcowego (lub jakiś inny dobrze zdefiniowany mechanizm), to o dystrybucji X nic konkretnego nie da się powiedzieć.
Z powyższego wynika, że w konkretnym stosowanym problemie normalności wyników pomiarów (obserwacji) z reguły nie można ustalić na podstawie rozważań ogólnych, należy to sprawdzić za pomocą kryteriów statystycznych. Lub użyj nieparametrycznych metod statystycznych, które nie opierają się na założeniach dotyczących przynależności funkcji rozkładu wyników pomiarów (obserwacji) do tej lub innej rodziny parametrycznej.
Rozkłady ciągłe stosowane w probabilistycznych i statystycznych metodach podejmowania decyzji. Oprócz rodziny rozkładów normalnych z przesunięciem skali, szeroko stosuje się wiele innych rodzin rozkładów - rozkłady lognormalne, wykładnicze, Weibulla-Gnedenki, rozkłady gamma. Przyjrzyjmy się tym rodzinom.
Losowa wartość X ma rozkład lognormalny, jeśli zmienna losowa Y= log X ma rozkład normalny. Następnie Z= log X = 2,3026…Y ma również rozkład normalny N(A 1 ,σ 1), gdzie ln X- naturalny logarytm X. Gęstość rozkładu lognormalnego wynosi:

Z centralnego twierdzenia granicznego wynika, że iloczyn X = X 1 X 2 … X rz niezależne dodatnie zmienne losowe X ja, I = 1, 2,…, N, ogólnie N można przybliżyć za pomocą rozkładu logarytmiczno-normalnego. W szczególności multiplikatywny model kształtowania płac lub dochodów prowadzi do zalecenia, aby aproksymować rozkłady płac i dochodów za pomocą logarytmicznie normalnych praw. Dla Rosji zalecenie to okazało się uzasadnione – potwierdzają to dane statystyczne.
Istnieją inne modele probabilistyczne, które prowadzą do prawa lognormalnego. Klasyczny przykład takiego modelu podał A.N. Kołmogorow, który na podstawie fizycznego systemu postulatów doszedł do wniosku, że wielkość cząstek podczas kruszenia kawałków rudy, węgla itp. w młynach kulowych mają rozkład logarytmiczno-normalny.
Przejdźmy do innej rodziny rozkładów, szeroko stosowanej w różnych probabilistyczno-statystycznych metodach podejmowania decyzji i innych badaniach stosowanych – rodziny rozkładów wykładniczych. Zacznijmy od modelu probabilistycznego, który prowadzi do takich rozkładów. Aby to zrobić, należy wziąć pod uwagę „przebieg zdarzeń”, tj. sekwencja zdarzeń następujących po sobie w określonych momentach czasu. Przykłady obejmują: przepływ połączeń w centrali telefonicznej; przepływ awarii urządzeń w łańcuchu technologicznym; przepływ usterek produktów podczas testowania produktów; przepływ wniosków klientów do oddziału banku; przepływ nabywców ubiegających się o towary i usługi itp. W teorii przepływów zdarzeń obowiązuje twierdzenie podobne do centralnego twierdzenia granicznego, tyle że nie chodzi tu o sumowanie zmiennych losowych, ale o sumowanie przepływów zdarzeń. Rozważamy przepływ całkowity złożony z dużej liczby niezależnych przepływów, z których żaden nie ma dominującego wpływu na przepływ całkowity. Na przykład strumień połączeń przychodzących do centrali telefonicznej składa się z dużej liczby niezależnych strumieni połączeń pochodzących od poszczególnych abonentów. Udowodniono, że w przypadku, gdy charakterystyki przepływów nie zależą od czasu, przepływ całkowity opisuje się w całości jedną liczbą – natężeniem przepływu. Dla całkowitego przepływu rozważ zmienną losową X- długość odstępu czasu pomiędzy kolejnymi zdarzeniami. Jego funkcja rozkładu ma postać
 (10)
(10)
Rozkład ten nazywa się rozkładem wykładniczym, ponieważ wzór (10) zawiera funkcję wykładniczą mi -λ X. Wartość 1/λ jest parametrem skali. Czasami wprowadzany jest również parametr przesunięcia Z, rozkład zmiennej losowej nazywany jest wykładniczym X + s, gdzie dystrybucja X wyraża się wzorem (10).
Rozkłady wykładnicze są szczególnym przypadkiem tzw. Rozkłady Weibulla-Gnedenki. Ich nazwy pochodzą od nazwisk inżyniera V. Weibulla, który wprowadził te rozkłady do praktyki analizy wyników badań zmęczeniowych, oraz matematyka B.V. Gnedenko (1912-1995), który otrzymał takie rozkłady jako granice przy badaniu maksimum wyniki testu. Pozwalać X- zmienna losowa charakteryzująca czas funkcjonowania produktu, złożonego systemu, elementu (tj. zasobu, czasu działania do stanu granicznego itp.), czas funkcjonowania przedsiębiorstwa lub życia istoty żywej itp. Intensywność awarii odgrywa ważną rolę
![]() (11)
(11)
Gdzie F(X) I F(X) - funkcja rozkładu i gęstość zmiennej losowej X.
Opiszmy typowe zachowanie wskaźnika awaryjności. Cały przedział czasowy można podzielić na trzy okresy. Na pierwszym z nich funkcja λ(x) ma wysokie wartości i wyraźną tendencję spadkową (najczęściej maleje monotonicznie). Można to wytłumaczyć obecnością w danej partii wyrobów jednostek z wadami oczywistymi i ukrytymi, które prowadzą do stosunkowo szybkiej awarii tych jednostek wyrobów. Pierwszy okres nazywany jest „okresem docierania” (lub „okresem docierania”). Tyle zazwyczaj obejmuje okres gwarancji.
Następnie następuje okres normalnej pracy, charakteryzujący się w przybliżeniu stałą i stosunkowo niską awaryjnością. Charakter awarii w tym okresie jest nagły (wypadki, błędy obsługi itp.) i nie jest zależny od czasu eksploatacji urządzenia.
Wreszcie ostatnim okresem eksploatacji jest okres starzenia i zużycia. Awarie występujące w tym okresie polegają na nieodwracalnych zmianach fizycznych, mechanicznych i chemicznych w materiałach, prowadzących do postępującego pogorszenia jakości jednostki produktu i jego ostatecznej awarii.
Każdy okres ma swój własny typ funkcji λ(x). Rozważmy klasę zależności mocy
λ(x) = λ 0bx b -1 , (12)
Gdzie λ 0 > 0 i B> 0 - niektóre parametry numeryczne. Wartości B < 1, B= 0 i B> 1 odpowiadają rodzajowi awaryjności odpowiednio w okresach docierania, normalnej pracy i starzenia.
Zależność (11) przy zadanym współczynniku awaryjności λ(x)- równanie różniczkowe funkcji F(X). Z teorii równania różniczkowe wynika z tego
 (13)
(13)
Podstawiając (12) do (13) otrzymujemy to
 (14)
(14)
Rozkład podany wzorem (14) nazywany jest rozkładem Weibulla – Gnedenko. Ponieważ
to ze wzoru (14) wynika, że ilość A, dany wzorem (15), jest parametrem skali. Czasami wprowadzany jest także parametr shift, tj. Nazywa się dystrybuanty Weibulla-Gnedenki F(X - C), Gdzie F(X) jest określone wzorem (14) dla niektórych λ 0 i B.
Gęstość rozkładu Weibulla-Gnedenko ma postać
 (16)
(16)
Gdzie A> 0 - parametr skali, B> 0 - parametr formularza, Z- parametr zmiany. W tym przypadku parametr A ze wzoru (16) jest powiązany z parametrem λ 0 ze wzoru (14) przez zależność określoną we wzorze (15).
Rozkład wykładniczy jest bardzo szczególnym przypadkiem rozkładu Weibulla-Gnedenki, odpowiadającym wartości parametru kształtu B = 1.
Rozkład Weibulla-Gnedenki wykorzystuje się także przy konstruowaniu probabilistycznych modeli sytuacji, w których o zachowaniu obiektu decyduje „najsłabsze ogniwo”. Istnieje analogia z łańcuchem, którego bezpieczeństwo zależy od ogniwa o najmniejszej wytrzymałości. Inaczej mówiąc, niech X 1 , X 2 ,…, X rz- niezależne zmienne losowe o jednakowym rozkładzie,
X(1)=min( X 1, X 2,…, X rz), X(n)=maks.( X 1, X 2,…, X n).
W wielu stosowanych problemach odgrywają one ważną rolę X(1) I X(N) w szczególności przy badaniu maksymalnych możliwych wartości („zapisów”) niektórych wartości, na przykład płatności ubezpieczeniowych lub strat wynikających z ryzyka handlowego, podczas badania granic elastyczności i wytrzymałości stali, szeregu cech niezawodności itp. . Pokazano, że dla dużych n rozkładów X(1) I X(N) , są z reguły dobrze opisane rozkładami Weibulla-Gnedenki. Zasadniczy wkład w badanie rozkładów X(1) I X(N) wniesiony przez radzieckiego matematyka B.V. Gnedenko. Prace V. Weibulla, E. Gumbela, V.B. poświęcone są wykorzystaniu wyników uzyskanych w ekonomii, zarządzaniu, technologii i innych dziedzinach. Nevzorova, E.M. Kudlaev i wielu innych specjalistów.
Przejdźmy do rodziny rozkładów gamma. Znajdują szerokie zastosowanie w ekonomii i zarządzaniu, teorii i praktyce niezawodności oraz testowaniu, w różnych dziedzinach techniki, meteorologii itp. W szczególności w wielu sytuacjach rozkład gamma zależy od takich wielkości, jak całkowity okres użytkowania produktu, długość łańcucha przewodzących cząstek pyłu, czas, w którym produkt osiąga stan graniczny podczas korozji, czas pracy do k-ta odmowa, k= 1, 2, … itd. Oczekiwana długość życia pacjentów choroby przewlekłe, czas do osiągnięcia określonego efektu podczas leczenia w niektórych przypadkach ma rozkład gamma. Rozkład ten jest najwłaściwszy do opisu popytu w ekonomicznych i matematycznych modelach zarządzania zapasami (logistyka).
Gęstość rozkładu gamma ma postać
 (17)
(17)
Gęstość prawdopodobieństwa we wzorze (17) wyznaczają trzy parametry A, B, C, Gdzie A>0, B>0. W której A jest parametrem formularza, B- parametr skali i Z- parametr zmiany. Czynnik 1/Γ(a) normalizuje się, do tego wprowadzono
![]()
Tutaj Γ(a)- jeden z tych stosowanych w matematyce funkcje specjalne, tzw. „funkcja gamma”, od której nazwany jest rozkład określony wzorem (17),

Na stałe A wzór (17) określa rodzinę rozkładów z przesunięciem skali generowaną przez rozkład z gęstością
 (18)
(18)
Rozkład postaci (18) nazywany jest standardowym rozkładem gamma. Otrzymuje się go ze wzoru (17) w B= 1 i Z= 0.
Szczególny przypadek rozkładów gamma dla A= 1 to rozkłady wykładnicze (z λ = 1/B). Z naturalnym A I Z Rozkłady gamma =0 nazywane są rozkładami Erlanga. Z prac duńskiego naukowca K.A. Erlanga (1878–1929), pracownika Kopenhaskiej Spółki Telefonicznej, który studiował w latach 1908–1922. funkcjonowania sieci telefonicznych rozpoczął się rozwój teorii kolejkowania. Teoria ta zajmuje się probabilistycznym i statystycznym modelowaniem systemów, w których obsługiwany jest przepływ żądań w celu podejmowania optymalnych decyzji. Rozkłady Erlanga są używane w tych samych obszarach zastosowań, w których używane są rozkłady wykładnicze. Opiera się to na następującym fakcie matematycznym: suma k niezależnych zmiennych losowych o rozkładzie wykładniczym o tych samych parametrach λ i Z, ma rozkład gamma z parametrem kształtu a =k, parametr skali B= 1/λ i parametr przesunięcia kc. Na Z= 0 otrzymujemy rozkład Erlanga.
Jeśli zmienna losowa X ma rozkład gamma z parametrem kształtu A takie, że D = 2 A- liczba całkowita, B= 1 i Z= 0, następnie 2 X ma rozkład chi-kwadrat z D stopnie swobody.
Losowa wartość X z dystrybucją gvmma ma następujące cechy:
Wartość oczekiwana M(X) =ok + C,
Zmienność D(X) = σ 2 = ok 2 ,
Współczynnik zmienności
Asymetria ![]()
Nadmiar ![]()
Rozkład normalny jest skrajnym przypadkiem rozkładu gamma. Dokładniej, niech Z będzie zmienną losową o standardowym rozkładzie gamma określonym wzorem (18). Następnie
![]()
dla dowolnej liczby rzeczywistej X, Gdzie F(x)- standardowa funkcja rozkładu normalnego N(0,1).
W badaniach stosowanych wykorzystuje się także inne parametryczne rodziny rozkładów, z których najbardziej znane to układ krzywych Pearsona, szeregi Edgewortha i Charliera. Nie są one tutaj brane pod uwagę.
Oddzielny rozkłady stosowane w probabilistycznych i statystycznych metodach podejmowania decyzji. Najczęściej stosowane są trzy rodziny rozkładów dyskretnych – dwumianowy, hipergeometryczny i Poissona, a także kilka innych rodzin – geometryczna, ujemna dwumianowa, wielomianowa, ujemna hipergeometryczna itp.
Jak już wspomniano, rozkład dwumianowy występuje w niezależnych próbach, z których w każdej z prawdopodobieństwem R pojawia się wydarzenie A. Jeśli Łączna testy N podane, następnie liczba testów Y, w którym pojawiło się wydarzenie A, ma rozkład dwumianowy. W przypadku rozkładu dwumianowego prawdopodobieństwo uznania go za zmienną losową wynosi Y wartości y określa się na podstawie wzoru
![]()
Liczba kombinacji N elementy wg y, znane z kombinatoryki. Dla wszystkich y, z wyjątkiem 0, 1, 2, …, N, mamy P(Y= y)= 0. Rozkład dwumianowy ze stałą wielkością próby N jest określony przez parametr P, tj. rozkłady dwumianowe tworzą rodzinę jednoparametrową. Wykorzystuje się je do analizy danych z badań reprezentacyjnych, w szczególności do badania preferencji konsumentów, selektywnej kontroli jakości produktu według jednostopniowych planów kontroli, przy badaniu populacji jednostek w zakresie demografii, socjologii, medycyny, biologii itp. .
Jeśli Y 1 I Y 2 - niezależne dwumianowe zmienne losowe o tym samym parametrze P 0 , określone na podstawie próbek o objętościach N 1 I N 2 zatem odpowiednio Y 1 + Y 2 - dwumianowa zmienna losowa o rozkładzie (19) z R = P 0 I N = N 1 + N 2 . Uwaga ta rozszerza stosowalność rozkładu dwumianowego, umożliwiając łączenie wyników kilku grup testów, gdy istnieją podstawy, aby sądzić, że ten sam parametr odpowiada wszystkim tym grupom.
Charakterystyki rozkładu dwumianowego obliczono wcześniej:
M(Y) = n.p., D(Y) = n.p.( 1- P).
W części „Zdarzenia i prawdopodobieństwa” udowodniono prawo wielkich liczb dla dwumianowej zmiennej losowej:
![]()
dla kazdego . Korzystając z centralnego twierdzenia granicznego, prawo wielkich liczb można udoskonalić, wskazując, ile Y/ N różni się od R.
Twierdzenie de Moivre’a-Laplace’a. Dla dowolnych liczb a i B, A< B, mamy

Gdzie F(X) jest funkcją standardowego rozkładu normalnego z oczekiwaniem matematycznym 0 i wariancją 1.
Aby to udowodnić, wystarczy skorzystać z reprezentacji Y w postaci sumy niezależnych zmiennych losowych odpowiadających wynikom poszczególnych testów, wzory na M(Y) I D(Y) oraz centralne twierdzenie graniczne.
To twierdzenie dotyczy przypadku R= ½ udowodnił angielski matematyk A. Moivre (1667-1754) w 1730 r. W powyższym sformułowaniu udowodnił to w 1810 r. francuski matematyk Pierre Simon Laplace (1749 - 1827).
Rozkład hipergeometryczny zachodzi podczas selektywnego sterowania skończonym zbiorem obiektów o objętości N według alternatywnego kryterium. Każdy kontrolowany obiekt jest klasyfikowany jako posiadający dany atrybut A lub jako nieposiadający tej cechy. Rozkład hipergeometryczny ma zmienną losową Y, równa liczbie obiekty posiadające daną cechę A w losowej próbce objętości N, Gdzie N< N. Na przykład liczba Y wadliwe jednostki produktu w losowej próbce objętościowej N od objętości partii N ma rozkład hipergeometryczny jeśli N< N. Innym przykładem jest loteria. Niech znak A bilet jest oznaką „bycia zwycięzcą”. Niech całkowita liczba biletów N, i pewna osoba nabyta N z nich. Wówczas liczba zwycięskich kuponów dla tej osoby ma rozkład hipergeometryczny.
Dla rozkładu hipergeometrycznego prawdopodobieństwo, że zmienna losowa Y przyjmie wartość y, ma postać
 (20)
(20)
Gdzie D– liczba obiektów posiadających dany atrybut A, w rozważanym zestawie objętości N. W której y przyjmuje wartości od max(0, N - (N - D)) do min( N, D), inne rzeczy y prawdopodobieństwo we wzorze (20) jest równe 0. Zatem rozkład hipergeometryczny wyznaczają trzy parametry - objętość populacja N, liczba obiektów D w nim, posiadająca daną cechę A i wielkość próbki N.
Proste losowe próbkowanie objętości N od całkowitej objętości N to próbka otrzymana w wyniku losowego doboru, w którym dowolny ze zbiorów N obiekty mają takie samo prawdopodobieństwo wybrania. Metody losowego doboru próby respondentów (rozmówców) lub jednostek towarów na sztuki omówiono w dokumentach instruktażowych, metodologicznych i regulacyjnych. Jedna z metod selekcji jest następująca: obiekty wybiera się jeden po drugim i na każdym etapie każdy z pozostałych obiektów w zestawie ma taką samą szansę na wybranie. W literaturze na określenie rodzaju rozpatrywanych próbek stosowane są także określenia „próbka losowa” i „próbka losowa bez zwrotu”.
Ponieważ wielkość populacji (partia) N i próbki N są zwykle znane, wówczas parametrem rozkładu hipergeometrycznego, który należy oszacować, jest: D. W statystycznych metodach zarządzania jakością produktów D– zwykle liczba wadliwych jednostek w partii. Interesująca jest także charakterystyka dystrybucji D/ N– poziom usterek.
Dla rozkładu hipergeometrycznego
Ostatni czynnik w wyrażeniu wariancji jest bliski 1, jeśli N>10 N. Jeśli dokonasz wymiany P = D/ N, wówczas wyrażenia na matematyczne oczekiwanie i wariancję rozkładu hipergeometrycznego zamienią się w wyrażenia na matematyczne oczekiwanie i wariancję rozkładu dwumianowego. To nie przypadek. Można to wykazać

Na N>10 N, Gdzie P = D/ N. Stosunek ograniczający obowiązuje
i tę ograniczającą relację można zastosować kiedy N>10 N.
Trzecią powszechnie stosowaną dystrybucją dyskretną jest rozkład Poissona. Zmienna losowa Y ma rozkład Poissona jeśli
![]() ,
,
gdzie λ jest parametrem rozkładu Poissona, oraz P(Y= y)= 0 dla wszystkich pozostałych y(dla y=0 oznacza się 0! =1). Dla rozkładu Poissona
M(Y) = λ, D(Y) = λ.
Rozkład ten został nazwany na cześć francuskiego matematyka S. D. Poissona (1781-1840), który uzyskał go po raz pierwszy w 1837 r. Rozkład Poissona jest granicznym przypadkiem rozkładu dwumianowego, gdy prawdopodobieństwo R realizacja zdarzenia jest niewielka, ale ilość testów Nświetnie, i n.p.= λ. Dokładniej, obowiązuje relacja graniczna
Dlatego rozkład Poissona (w starej terminologii „prawo dystrybucji”) często nazywany jest także „prawem rzadkich zdarzeń”.
Rozkład Poissona wywodzi się z teorii przepływu zdarzeń (patrz wyżej). Udowodniono, że dla najprostszego przepływu o stałym natężeniu Λ liczba zdarzeń (wywołań), które wystąpiły w czasie T, ma rozkład Poissona z parametrem λ = Λ T. Dlatego prawdopodobieństwo, że w tym czasie Tżadne zdarzenie nie nastąpi, równe mi - Λ T, tj. funkcja rozkładu długości odstępu między zdarzeniami jest wykładnicza.
Rozkład Poissona wykorzystuje się do analizy wyników przykładowych badań marketingowych konsumentów, obliczania charakterystyki operacyjnej statystycznych planów kontroli akceptacji w przypadku małych wartości poziomu akceptacji wad, do opisu liczby awarii kontrolowanego statystycznie procesu technologicznego w jednostce czasu, liczby „zapotrzebowań na usługi” otrzymanych w jednostce czasu w systemie kolejkowym, statystycznych wzorców wypadków i rzadkie choroby itp.
Opis innych rodzin parametrycznych rozkładów dyskretnych i ich możliwości praktyczne użycie są rozpatrywane w literaturze.
W niektórych przypadkach, na przykład podczas badania cen, wielkości produkcji lub całkowitego czasu między awariami w problemach z niezawodnością, funkcje rozkładu są stałe w pewnych przedziałach, w które nie mogą spaść wartości badanych zmiennych losowych.
| Poprzedni |
3. Funkcja dystrybucji to nie malejący: Jeśli następnie
4. Funkcja dystrybucji pozostawiony ciągły: dla kazdego .
Notatka. Ostatnia właściwość wskazuje, jakie wartości przyjmuje funkcja rozkładu w punktach przerwania. Czasami definicję funkcji rozkładu formułuje się za pomocą luźnej nierówności: . W tym przypadku ciągłość po lewej stronie zostaje zastąpiona ciągłością po prawej stronie: kiedy . Nie zmienia to żadnych znaczących właściwości funkcji rozkładu, więc to pytanie ma charakter wyłącznie terminologiczny.
Właściwości 1-4 są charakterystyczne, tj. każda funkcja spełniająca te własności jest dystrybuantą jakiejś zmiennej losowej.
Funkcja rozkładu jednoznacznie definiuje rozkład prawdopodobieństwa zmiennej losowej. Właściwie jest to uniwersalny i najbardziej wizualny sposób opisu tego rozkładu.
Im bardziej rośnie funkcja rozkładu w danym przedziale osi liczbowej, tym większe jest prawdopodobieństwo, że zmienna losowa znajdzie się w tym przedziale. Jeśli prawdopodobieństwo wpadnięcia w przedział wynosi zero, to funkcja rozkładu na nim jest stała.
W szczególności prawdopodobieństwo, że zmienna losowa przyjmie daną wartość, jest równe skokowi funkcji rozkładu w danym punkcie:
.Jeżeli rozkład jest ciągły w punkcie , to prawdopodobieństwo przyjęcia tej wartości przez zmienną losową wynosi zero. W szczególności, jeśli funkcja rozkładu jest ciągła na całej osi liczbowej (w tym przypadku nazywa się odpowiedni rozkład ciągły), wówczas prawdopodobieństwo przyjęcia dowolnej wartości wynosi zero.
Z definicji dystrybuanty wynika, że prawdopodobieństwo wpadnięcia zmiennej losowej w przedział zamknięty z lewej strony i otwarty z prawej strony wynosi:
Stosując ten wzór oraz powyższą metodę wyznaczania prawdopodobieństwa trafienia w dowolny punkt, można łatwo wyznaczyć prawdopodobieństwo, że zmienna losowa znajdzie się w przedziałach innych typów: , i . Co więcej, dzięki twierdzeniu o przedłużeniu miary możemy jednoznacznie rozszerzyć miarę na wszystkie zbiory borelowskie osi liczbowej. Aby zastosować to twierdzenie, należy wykazać, że tak zdefiniowana miara na przedziałach jest na nich sumowana sigma; dowodząc tego, wykorzystuje się dokładnie właściwości 1-4 (w szczególności właściwość lewej ciągłości 4, więc nie można jej odrzucić).
Generowanie zmiennej losowej o zadanym rozkładzie
Rozważmy zmienną losową, która ma funkcję rozkładu. Udawajmy, że tak ciągły. Rozważ zmienną losową
.Łatwo pokazać, że wówczas będzie miał rozkład równomierny na odcinku.
Definicja funkcji zmiennych losowych. Funkcja dyskretnego argumentu losowego i jej charakterystyki liczbowe. Funkcja ciągłego argumentu losowego i jej charakterystyki liczbowe. Funkcje dwóch losowych argumentów. Wyznaczanie funkcji rozkładu prawdopodobieństwa i gęstości dla funkcji dwóch losowych argumentów.
Prawo rozkładu prawdopodobieństwa funkcji jednej zmiennej losowej
Przy rozwiązywaniu problemów związanych z oceną dokładności działania różnych układów automatyki, dokładności wykonania poszczególnych elementów układów itp. często konieczne jest uwzględnienie funkcji jednej lub większej liczby zmiennych losowych. Funkcje takie są również zmiennymi losowymi. Dlatego przy rozwiązywaniu problemów konieczna jest znajomość praw rozkładu zmiennych losowych występujących w zadaniu. W tym przypadku zwykle znane jest prawo rozkładu układu argumentów losowych i zależność funkcjonalna.
Powstaje zatem problem, który można sformułować następująco.
Biorąc pod uwagę system zmiennych losowych (X_1,X_2,\ldots,X_n), którego prawo podziału jest znane. Pewna zmienna losowa Y jest uważana za funkcję tych zmiennych losowych:
Y=\varphi(X_1,X_2,\ldots,X_n).
Należy wyznaczyć prawo rozkładu zmiennej losowej Y, znając postać funkcji (6.1) i prawo łącznego rozkładu jej argumentów.
Rozważmy problem prawa dystrybucji funkcji jednego losowego argumentu
Y=\varphi(X).
\begin(array)(|c|c|c|c|c|)\hline(X)&x_1&x_2&\cdots&x_n\\\hline(P)&p_1&p_2&\cdots&p_n\\\hline\end(array)
Wtedy Y=\varphi(X) jest również dyskretną zmienną losową o możliwych wartościach. Jeśli wszystkie wartości y_1, y_2,\ldots,y_n są różne, to dla każdego k=1,2,\ldots,n zdarzenia \(X=x_k\) i \(Y=y_k=\varphi(x_k)\) są identyczne. Stąd,
P\(Y=y_k\)=P\(X=x_k\)=p_k
a wymagany szereg dystrybucyjny ma postać
\begin(array)(|c|c|c|c|c|)\hline(Y)&y_1=\varphi(x_1)&y_2=\varphi(x_2)&\cdots&y_n=\varphi(x_n)\\\hline (P)&p_1&p_2&\cdots&p_n\\\hline\end(tablica)
Jeśli wśród liczb y_1=\varphi(x_1),y_2=\varphi(x_2),\ldots,y_n=\varphi(x_n) są identyczne, to każdej grupie identycznych wartości y_k=\varphi(x_k) należy przydzielić jedną kolumnę w tabeli i zsumować odpowiednie prawdopodobieństwa.
Dla ciągłych zmiennych losowych problem postawiono następująco: znając gęstość rozkładu f(x) zmiennej losowej X, znajdź gęstość rozkładu g(y) zmiennej losowej Y=\varphi(X). Rozwiązując problem, rozważamy dwa przypadki.
Załóżmy najpierw, że funkcja y=\varphi(x) jest monotonicznie rosnąca, ciągła i różniczkowalna na przedziale (a;b), na którym wszystkie możliwa wartość Wartości X. Wówczas istnieje funkcja odwrotna x=\psi(y), która jednocześnie jest monotonicznie rosnąca, ciągła i różniczkowalna. W tym przypadku otrzymujemy
G(y)=f\bigl(\psi(y)\bigr)\cdot |\psi"(y)|.
Przykład 1. Zmienna losowa X o rozkładzie gęstości
F(x)=\frac(1)(\sqrt(2\pi))e^(-x^2/2)
Znajdź prawo rozkładu zmiennej losowej Y powiązanej z wartością X z zależności Y=X^3.
Rozwiązanie. Ponieważ funkcja y=x^3 jest monotoniczna na przedziale (-\infty;+\infty), możemy zastosować wzór (6.2). Funkcja odwrotna w odniesieniu do funkcji \varphi(x)=x^3 istnieje \psi(y)=\sqrt(y) , jej pochodna \psi"(y)=\frac(1)(3\sqrt(y^2)). Stąd,
G(y)=\frac(1)(3\sqrt(2\pi))e^(-\sqrt(y^2)/2)\frac(1)(\sqrt(y^2))
Rozważmy przypadek funkcji niemonotonicznej. Niech funkcja y=\varphi(x) będzie taka, że funkcja odwrotna x=\psi(y) będzie niejednoznaczna, czyli jednej wartości y odpowiada kilka wartości argumentu x, które oznaczamy x_1=\psi_1(y),x_2=\psi_2(y),\ldots,x_n=\psi_n(y), gdzie n jest liczbą odcinków, w których funkcja y=\varphi(x) zmienia się monotonicznie. Następnie
G(y)=\sum\limits_(k=1)^(n)f\bigl(\psi_k(y)\bigr)\cdot |\psi"_k(y)|.
Przykład 2. W warunkach z przykładu 1 znajdź rozkład zmiennej losowej Y=X^2.
Rozwiązanie. Funkcja odwrotna x=\psi(y) jest niejednoznaczna. Jedna wartość argumentu y odpowiada dwóm wartościom funkcji x
Stosując wzór (6.3) otrzymujemy:
\begin(zebrane)g(y)=f(\psi_1(y))|\psi"_1(y)|+f(\psi_2(y))|\psi"_2(y)|=\\\\ =\frac(1)(\sqrt(2\pi))\,e^(-\left(-\sqrt(y^2)\right)^2/2)\!\left|-\frac(1 )(2\sqrt(y))\right|+\frac(1)(\sqrt(2\pi))\,e^(-\left(\sqrt(y^2)\right)^2/2 )\!\left|\frac(1)(2\sqrt(y))\right|=\frac(1)(\sqrt(2\pi(y)))\,e^(-y/2) .\end(zebrane)
Prawo rozkładu funkcji dwóch zmiennych losowych
Niech zmienna losowa Y będzie funkcją dwóch zmiennych losowych tworzących układ (X_1;X_2), tj. Y=\varphi(X_1;X_2). Zadanie polega na znalezieniu rozkładu zmiennej losowej Y korzystając ze znanego rozkładu układu (X_1;X_2).
Niech f(x_1;x_2) będzie gęstością rozkładu układu zmiennych losowych (X_1;X_2) . Wprowadźmy pod uwagę nową wielkość Y_1 równą X_1 i rozważmy układ równań
Założymy, że ten układ jest jednoznacznie rozwiązywalny ze względu na x_1,x_2
i spełnia warunki różniczkowalności.
Gęstość rozkładu zmiennej losowej Y
G_1(y)=\int\limits_(-\infty)^(+\infty)f(x_1;\psi(y;x_1))\!\left|\frac(\partial\psi(y;x_1)) (\częściowe(y))\right|dx_1.
Należy zauważyć, że rozumowanie nie ulega zmianie, jeśli wprowadzona nowa wartość Y_1 zostanie ustawiona na wartość X_2.
Matematyczne oczekiwanie funkcji zmiennych losowych
W praktyce często zdarzają się przypadki, gdy nie ma szczególnej potrzeby całkowitego wyznaczania prawa rozkładu funkcji zmiennych losowych, wystarczy jedynie wskazać jej charakterystykę liczbową. Powstaje zatem problem wyznaczenia charakterystyk numerycznych funkcji zmiennych losowych w uzupełnieniu do praw rozkładu tych funkcji.
Niech zmienna losowa Y będzie funkcją losowego argumentu X z danym prawem dystrybucji
Y=\varphi(X).
Wymagane jest, bez znajdowania prawa rozkładu wielkości Y, określenie jej oczekiwań matematycznych
M(Y)=M[\varphi(X)].
Niech X będzie dyskretną zmienną losową mającą szereg dystrybucyjny
\begin(array)(|c|c|c|c|c|)\hline(x_i)&x_1&x_2&\cdots&x_n\\\hline(p_i)&p_1&p_2&\cdots&p_n\\\hline\end(array)
Zróbmy tabelę wartości wartości Y i prawdopodobieństw tych wartości:
\begin(array)(|c|c|c|c|c|)\hline(y_i=\varphi(x_i))&y_1=\varphi(x_1)&y_2=\varphi(x_2)&\cdots&y_n=\varphi( x_n)\\\hline(p_i)&p_1&p_2&\cdots&p_n\\\hline\end(tablica)
Ta tabela nie jest serią rozkładów zmiennej losowej Y, ponieważ w ogólnym przypadku niektóre wartości mogą się ze sobą pokrywać, a wartości w górnym wierszu niekoniecznie są w porządku rosnącym. Jednakże matematyczne oczekiwanie zmiennej losowej Y można określić za pomocą wzoru
M[\varphi(X)]=\sum\limits_(i=1)^(n)\varphi(x_i)p_i,
ponieważ wartość określona wzorem (6.4) nie może się zmienić, ponieważ pod znakiem sumy niektóre wyrazy zostaną z góry połączone i zmieni się kolejność wyrazów.
Wzór (6.4) nie zawiera jawnie prawa dystrybucji samej funkcji \varphi(X), lecz zawiera jedynie prawo dystrybucji argumentu X. Zatem, aby wyznaczyć matematyczne oczekiwanie funkcji Y=\varphi(X), wcale nie jest konieczna znajomość prawa rozkładu funkcji \varphi(X), lecz znajomość prawa rozkładu argumentu X.
W przypadku ciągłej zmiennej losowej oczekiwanie matematyczne oblicza się za pomocą wzoru
M[\varphi(X)]=\int\limits_(-\infty)^(+\infty)\varphi(x)f(x)\,dx,
gdzie f(x) jest gęstością rozkładu prawdopodobieństwa zmiennej losowej X.
Rozważmy przypadki, gdy do znalezienia matematycznego oczekiwania funkcji losowych argumentów nie jest wymagana znajomość nawet praw rozkładu argumentów, a wystarczy znać tylko niektóre ich charakterystyki liczbowe. Sformułujmy te przypadki w formie twierdzeń.
Twierdzenie 6.1. Oczekiwanie matematyczne sumy dwóch zmiennych losowych zależnych i niezależnych jest równe sumie oczekiwań matematycznych tych zmiennych:
M(X+Y)=M(X)+M(Y).
Twierdzenie 6.2. Oczekiwanie matematyczne iloczynu dwóch zmiennych losowych jest równe iloczynowi ich oczekiwań matematycznych plus moment korelacji:
M(XY)=M(X)M(Y)+\mu_(xy).
Wniosek 6.1. Oczekiwanie matematyczne iloczynu dwóch nieskorelowanych zmiennych losowych jest równe iloczynowi ich oczekiwań matematycznych.
Wniosek 6.2. Oczekiwanie matematyczne iloczynu dwóch niezależnych zmiennych losowych jest równe iloczynowi ich oczekiwań matematycznych.
Wariancja funkcji zmiennych losowych
Z definicji dyspersji mamy D[Y]=M[(Y-M(Y))^2].. Stąd,
D[\varphi(x)]=M[(\varphi(x)-M(\varphi(x)))^2], Gdzie .
Podajemy wzory obliczeniowe tylko dla przypadku ciągłych argumentów losowych. Dla funkcji jednego losowego argumentu Y=\varphi(X) wariancję wyraża się wzorem
D[\varphi(x)]=\int\limits_(-\infty)^(+\infty)(\varphi(x)-M(\varphi(x)))^2f(x)\,dx,
Gdzie M(\varphi(x))=M[\varphi(X)]- matematyczne oczekiwanie funkcji \varphi(X) ; f(x) - gęstość rozkładu wartości X.
Wzór (6.5) można zastąpić następującym:
D[\varphi(x)]=\int\limits_(-\infty)^(+\infty)\varphi^2(x)f(x)\,dx-M^2(X)
Rozważmy twierdzenia o dyspersji, które odgrywają ważną rolę w teorii prawdopodobieństwa i jej zastosowaniach.
Twierdzenie 6.3. Wariancja sumy zmiennych losowych jest równa sumie wariancji tych wielkości plus podwojona suma momentów korelacji każdej z sum ze wszystkimi kolejnymi:
D\!\left[\sum\limits_(i=1)^(n)X_i\right]=\sum\limits_(i=1)^(n)D+2\sum\limits_(i Wniosek 6.3. Wariancja sumy nieskorelowanych zmiennych losowych jest równa sumie wariancji wyrazów: D\!\left[\sum\limits_(i=1)^(n)X_i\right]=\sum\limits_(i=1)^(n)D\mu_(y_1y_2)= M(Y_1Y_2)-M(Y_1)M(Y_2). \mu_(y_1y_2)=M(\varphi_1(X)\varphi_2(X))-M(\varphi_1(X))M(\varphi_2(X)). Spójrzmy na główne właściwości momentu korelacji i współczynnika korelacji. Właściwość 1. Dodanie stałych do zmiennych losowych nie powoduje zmiany momentu korelacji i współczynnika korelacji. Własność 2. Dla dowolnych zmiennych losowych X i Y wartość bezwzględna momentu korelacji nie przekracza średniej geometrycznej wariancji tych wartości: |\mu_(xy)|\leqslant\sqrt(D[X]\cdot D[Y])=\sigma_x\cdot \sigma_y, Zmienna losowa
jest zmienną, która może przyjmować określone wartości w zależności od różnych okoliczności, oraz zmienna losowa nazywana jest ciągłą
, jeśli może przyjąć dowolną wartość z dowolnego ograniczonego lub nieograniczonego przedziału. W przypadku ciągłej zmiennej losowej nie da się wskazać wszystkich możliwych wartości, dlatego wyznaczamy przedziały tych wartości, które są powiązane z określonymi prawdopodobieństwami. Przykładami ciągłych zmiennych losowych są: średnica części szlifowanej do zadanego rozmiaru, wzrost człowieka, zasięg lotu pocisku itp. Ponieważ dla ciągłych zmiennych losowych funkcja F(X), W odróżnieniu dyskretne zmienne losowe, nie ma nigdzie skoków, to prawdopodobieństwo dowolnej indywidualnej wartości ciągłej zmiennej losowej wynosi zero. Oznacza to, że w przypadku ciągłej zmiennej losowej nie ma sensu mówić o rozkładzie prawdopodobieństwa pomiędzy jej wartościami: każda z nich ma prawdopodobieństwo zerowe. Jednak w pewnym sensie wśród wartości ciągłej zmiennej losowej są „bardziej i mniej prawdopodobne”. Przykładowo mało kto miałby wątpliwości, że wartość zmiennej losowej – wzrost losowo napotkanej osoby – 170 cm – jest bardziej prawdopodobna niż 220 cm, choć w praktyce obie wartości mogą wystąpić. Jako prawo dystrybucji, które ma sens tylko dla ciągłych zmiennych losowych, wprowadzono pojęcie gęstości rozkładu lub gęstości prawdopodobieństwa. Podejdźmy do tego porównując znaczenie funkcji rozkładu dla ciągłej zmiennej losowej i dla dyskretnej zmiennej losowej. Zatem funkcja rozkładu zmiennej losowej (zarówno dyskretnej, jak i ciągłej) lub funkcja integralna nazywa się funkcją określającą prawdopodobieństwo przyjęcia wartości zmiennej losowej X mniejsza lub równa wartości granicznej X. Dla dyskretnej zmiennej losowej w punktach jej wartości X1
, X 2
, ..., X I,... masy prawdopodobieństw są skoncentrowane P1
, P 2
, ..., P I,..., a suma wszystkich mas jest równa 1. Przenieśmy tę interpretację na przypadek ciągłej zmiennej losowej. Wyobraźmy sobie, że masa równa 1 nie jest skupiona w poszczególnych punktach, ale jest w sposób ciągły „rozmazana” wzdłuż osi odciętych Oh z pewną nierówną gęstością. Prawdopodobieństwo, że zmienna losowa wpadnie do dowolnego obszaru Δ X będzie interpretowana jako masa przypadająca na przekrój, a średnia gęstość na tym przekroju jako stosunek masy do długości. Właśnie wprowadziliśmy ważne pojęcie w teorii prawdopodobieństwa: gęstość rozkładu. Gęstości prawdopodobieństwa F(X) ciągłej zmiennej losowej jest pochodną jej funkcji rozkładu: Znając funkcję gęstości, można wyznaczyć prawdopodobieństwo, że wartość ciągłej zmiennej losowej należy do przedziału domkniętego [ A; B]: prawdopodobieństwo, że ciągła zmienna losowa X przyjmie dowolną wartość z przedziału [ A; B], jest równa pewnej całce z gęstości prawdopodobieństwa w zakresie od A zanim B: W tym przypadku ogólny wzór funkcji F(X) rozkład prawdopodobieństwa ciągłej zmiennej losowej, który można wykorzystać, jeśli znana jest funkcja gęstości F(X)
: Wykres gęstości prawdopodobieństwa ciągłej zmiennej losowej nazywany jest jej krzywą rozkładu (rysunek poniżej). Obszar figury (zacieniony na rysunku) ograniczony krzywą, liniami prostymi narysowanymi z punktów A I B prostopadle do osi x i osi Oh, graficznie przedstawia prawdopodobieństwo, że wartość ciągłej zmiennej losowej X jest w zasięgu A zanim B. 1. Prawdopodobieństwo, że zmienna losowa przyjmie dowolną wartość z przedziału (oraz obszar figury ograniczony wykresem funkcji F(X) i oś Oh) jest równe jeden: 2. Funkcja gęstości prawdopodobieństwa nie może przyjmować wartości ujemnych: a poza istnieniem rozkładu jego wartość wynosi zero Gęstość dystrybucji F(X), a także funkcję dystrybucji F(X), jest jedną z form prawa dystrybucji, ale w przeciwieństwie do funkcji dystrybucji nie jest uniwersalna: gęstość rozkładu istnieje tylko dla ciągłych zmiennych losowych. Wspomnijmy o dwóch najważniejszych w praktyce typach rozkładu ciągłej zmiennej losowej. Jeśli funkcja gęstości rozkładu F(X) ciągła zmienna losowa w pewnym skończonym przedziale [ A; B] przyjmuje wartość stałą C, a poza przedziałem przyjmuje wartość równą zero, to to rozkład nazywa się równomiernym . Jeżeli wykres funkcji gęstości rozkładu jest symetryczny względem środka, wartości średnie skupiają się w pobliżu środka, a oddalając się od środka zbierane są te, które bardziej odbiegają od średniej (wykres funkcji przypomina wycinek dzwonek), potem to rozkład nazywa się normalnym . Przykład 1. Znana jest funkcja rozkładu prawdopodobieństwa ciągłej zmiennej losowej: Znajdź funkcję F(X) gęstość prawdopodobieństwa ciągłej zmiennej losowej. Utwórz wykresy obu funkcji. Znajdź prawdopodobieństwo, że ciągła zmienna losowa przyjmie dowolną wartość z przedziału od 4 do 8: . Rozwiązanie. Funkcję gęstości prawdopodobieństwa uzyskujemy znajdując pochodną funkcji rozkładu prawdopodobieństwa: Wykres funkcji F(X) - parabola: Wykres funkcji F(X) - prosty: Znajdźmy prawdopodobieństwo, że ciągła zmienna losowa przyjmie dowolną wartość z zakresu od 4 do 8: Przykład 2. Funkcję gęstości prawdopodobieństwa ciągłej zmiennej losowej podaje się jako: Oblicz współczynnik C. Znajdź funkcję F(X) rozkład prawdopodobieństwa ciągłej zmiennej losowej. Utwórz wykresy obu funkcji. Znajdź prawdopodobieństwo, że ciągła zmienna losowa przyjmie dowolną wartość z zakresu od 0 do 5: . Rozwiązanie. Współczynnik C korzystając z właściwości 1 funkcji gęstości prawdopodobieństwa znajdujemy: Zatem funkcja gęstości prawdopodobieństwa ciągłej zmiennej losowej wynosi: Całkując znajdujemy funkcję F(X) rozkłady prawdopodobieństwa. Jeśli X < 0
, то
F(X) = 0 . Jeśli 0< X < 10
, то X> 10, więc F(X) = 1
. Zatem, pełny zapis funkcje rozkładu prawdopodobieństwa: Wykres funkcji F(X)
: Wykres funkcji F(X)
: Znajdźmy prawdopodobieństwo, że ciągła zmienna losowa przyjmie dowolną wartość z zakresu od 0 do 5: Przykład 3. Gęstość prawdopodobieństwa ciągłej zmiennej losowej X jest dana przez równość i . Znajdź współczynnik A, prawdopodobieństwo, że ciągła zmienna losowa X przyjmie dowolną wartość z przedziału ]0, 5[, czyli rozkładu ciągłej zmiennej losowej X. Rozwiązanie. Pod warunkiem dochodzimy do równości Dlatego, skąd. Więc, Teraz znajdujemy prawdopodobieństwo, że ciągła zmienna losowa X przyjmie dowolną wartość z przedziału ]0, 5[: Teraz otrzymujemy funkcję rozkładu tej zmiennej losowej: Przykład 4. Znajdź gęstość prawdopodobieństwa ciągłej zmiennej losowej X, która przyjmuje tylko wartości nieujemne, i jej dystrybuantę
to znaczy moment korelacji dwóch funkcji zmiennych losowych jest równy matematycznemu oczekiwaniu iloczynu tych funkcji minus iloczyn oczekiwań matematycznych. Funkcja rozkładu ciągłej zmiennej losowej i gęstość prawdopodobieństwa
![]() .
.
![]()
![]() .
.![]() .
.
Własności funkcji gęstości prawdopodobieństwa ciągłej zmiennej losowej





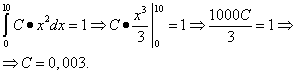
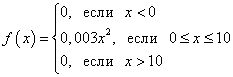
![]() .
.


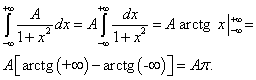
![]() .
.

![]() .
.

