V matematike je aritmetická hodnota čísel (alebo jednoducho znamenať) súčtom všetkých čísel v tejto súprave, rozdelenej podľa ich čísla. Toto je najviac všeobecná a rozšírená koncepcia strednej veľkosti. Ako ste už pochopili, aby ste našli priemernú hodnotu, musíte zhrnúť všetky údaje pre vás a výsledok je rozdelený na počet komponentov.
Aký je aritmetický priemer?
Pozname príklad.
Príklad 1.. Existujú čísla: 6, 7, 11. Je potrebné nájsť ich priemernú hodnotu.
Rozhodnutie.
Ak chcete začať, nájdeme množstvo všetkých týchto čísel.
Teraz rozdelíme výslednú sumu počtom komponentov. Vzhľadom k tomu, že máme termíny tri, rozdelíme sa o tri.
V dôsledku toho je priemerná hodnota čísel 6, 7 a 11 8. Prečo presne 8? Áno, pretože množstvo 6, 7 a 11 bude rovnaké ako tri osem. To je úplne viditeľné na ilustrácii.
Priemerná hodnota niečoho sa podobá "zarovnaniu" viacerých čísel. Ako vidíte, niekoľko ceruziek sa stalo jednou úrovňou.
Zvážte ďalší príklad na konsolidáciu získaných poznatkov.
Príklad 2. Existujú čísla: 3, 7, 5, 13, 20, 23, 39, 23, 40, 23, 14, 12, 56, 23, 29. Je potrebné nájsť svoj aritmetický význam.
Rozhodnutie.
Nájdeme sumu.
3 + 7 + 5 + 13 + 20 + 23 + 39 + 23 + 40 + 23 + 14 + 12 + 56 + 23 + 29 = 330
Rozdeľujeme počet komponentov (v tomto prípade - 15).
V dôsledku toho je priemerná hodnota tohto počtu čísel 22.
Teraz zvážte záporné čísla. Pripomeňme, ako ich zhrnúť. Máte napríklad dve čísla 1 a -4. Nachádzame ich sumu.
1 + (-4) = 1 – 4 = -3
Vedieť, zvážte ďalší príklad.
Príklad 3. Nájdite priemernú hodnotu niekoľkých čísel: 3, -7, 5, 13, -2.
Rozhodnutie.
Nájdeme sumu čísel.
3 + (-7) + 5 + 13 + (-2) = 12
Od podmienok 5, rozdelíme výslednú sumu o 5.
V dôsledku toho je priemerná aritmetická hodnota čísel 3, -7, 5, 13, -2 2,4.
 V súčasnosti je technologický pokrok oveľa pohodlnejší na používanie počítačových programov na nájdenie priemernej hodnoty. Microsoft Office Excel je jedným z nich. Hľadať v priemere v programe Excel rýchlo a jednoduchý. Okrem toho tento program vstupuje do balíka softvéru spoločnosti Microsoft Office. Zvážte krátku inštrukciu Ako nájsť priemernú aritmetickú hodnotu pomocou tohto programu.
V súčasnosti je technologický pokrok oveľa pohodlnejší na používanie počítačových programov na nájdenie priemernej hodnoty. Microsoft Office Excel je jedným z nich. Hľadať v priemere v programe Excel rýchlo a jednoduchý. Okrem toho tento program vstupuje do balíka softvéru spoločnosti Microsoft Office. Zvážte krátku inštrukciu Ako nájsť priemernú aritmetickú hodnotu pomocou tohto programu.
Aby ste mohli vypočítať priemerný počet čísel, musíte použiť priemernú funkciu. Syntax pre túto funkciu:
\u003d Priemer (argument1, argument2, ... Argument255)
Tam, kde argument1, argumenty2, ... Argument255 je buď čísla alebo odkazy na bunky (pod implicitnými rozsahmi buniek).
Aby bolo jasnejšie, vyskúšajte si získané vedomosti.


- Zadajte čísla 11, 12, 13, 14, 15, 16 v bunke C1 - C6.
- Zvýraznite C7 bunku kliknutím naň. V tejto bunke budeme mať priemernú hodnotu.
- Kliknite na kartu Formula.
- Vyberte viac funkcií\u003e Štatistické na otvorenie rozbaľovacieho zoznamu.
- Vyberte priemer. Potom by sa malo otvoriť dialógové okno.
- Zvýraznite a presuňte C1-C6 bunku, ak chcete nastaviť rozsah v dialógovom okne.
- Potvrďte svoje akcie pomocou tlačidla "OK".
- Ak ste všetci hotoví správne, v C7 bunke by ste mali mať odpoveď - 13.7. Keď kliknete na C7 bunkovú funkciu (\u003d priemer (C1: C6)) sa zobrazí vo vnútri vzorca.
Je veľmi vhodné používať túto funkciu pre udržanie účtovníctva, faktúr, alebo keď potrebujete nájsť priemernú hodnotu z veľmi dlhého počtu čísel. Preto sa často používa v kanceláriách a veľkých spoločnostiach. To vám umožní udržiavať objednávku v záznamoch a umožňuje rýchlo vypočítať čokoľvek (napríklad priemerný príjem za mesiac). Tiež pomocou programu Excel nájdete priemernú hodnotu funkcie.
Priemeru
Tento termín má iné hodnoty, pozri priemernú hodnotu.Priemeru (v matematike a štatistike) mnohých čísel - súčet všetkých čísel rozdelených podľa ich čísla. Je to jedna z najbežnejších opatrení centrálneho trendu.
Navrhuje sa (spolu s priemerným geometrickým a stredným harmonickým) stále s Pythagoreanmi.
Najmä prípady stredne veľkosti aritmetiky sú priemerný (všeobecný agregát) a selektívny priemer (odber vzoriek).
Úvod
Označujú veľa údajov X. = (x. 1 , x. 2 , …, x. n.), potom je selektívny priemer zvyčajne označený horizontálnou čiarou nad premennou (x ¯ (Displaystyle (bar (x))), vyslovené " x. s funkciou ").
Určiť priemernú aritmetickú kombináciu gréckeho písmena μ. Pre náhodnú premennú, pre ktorú je definovaná priemerná hodnota, μ je pravdepodobnostný priemer alebo matematické očakávania náhodnej premennej. Ak je nastavená X. je kombináciou náhodných čísel s pravdepodobnostným priemerom μ, potom pre akúkoľvek vzorku x. i. Z tejto Community μ \u003d e ( x. i. ) Existuje matematické očakávania tejto vzorky.
V praxi je rozdiel medzi μ a x ¯ (Displaystyle (bar (x))) je, že μ je typická premenná, pretože je možné vidieť vzorku skôr, a nie celú všeobecnú celkovú úplnosť. Preto, ak je vzorka náhodne reprezentovaná (z hľadiska teórie pravdepodobnosti), potom x ¯ (Displaystyle (bar (x))) (ale nie μ) sa môže interpretovať ako náhodná premenná, ktorá má pravdepodobnosť distribúcie na vzorke (pravdepodobnostný Distribúcia strednej časti).
Obe tieto hodnoty sa vypočítajú rovnakým spôsobom:
X ¯ \u003d 1 n σ i \u003d 1 n x i \u003d 1 n (x 1 + ⋯ + x n). (Displaystyle (bar (x)) \u003d (\\ frac (1) (n)) súčet _ (i \u003d 1) ^ (n) x_ (i) \u003d (frac (1) (n)) (x_ (1) + cdots + x_ (n)).)
Ak X. - náhodná premenná, potom matematické očakávania X. môžu byť považované za priemerné aritmetické hodnoty v opakujúcich sa meraniach rozsahu X.. Toto je prejav práva veľkého počtu. Preto sa selektívny priemer používa na posúdenie neznáme matematické očakávania.
V základnej algebre sa dokázalo, že priemer n. + 1 Čísla Viac priemeru n. Čísla potom a len vtedy, ak je nové číslo väčšie ako starý priemer, menej ako len vtedy, ak je nové číslo menšie ako priemer, a nemení sa, ak a len ak sa nové číslo rovná priemeru. Väčší n.Čím menší je rozdiel medzi novými a starými priemernými hodnotami.
Všimnite si, že existuje niekoľko ďalších "stredných" hodnôt, vrátane priemerného výkonu, sekundárneho Kolmogorova, harmonického priemeru, aritmetika-geometrického priemeru a rôznych stredne vážených hodnôt (napríklad aritmeticky vážených, priemerných geometrických suspendovaných, priemerných harmonických vážených).
Príklady
- Pre tri čísla je potrebné ich pridať a rozdeliť 3:
- Pre štyri čísla je potrebné ich pridať a rozdeliť 4:
Alebo jednoduchšie 5 + 5 \u003d 10, 10: 2. Pretože sme zložené 2 čísla, čo znamená, koľko počtov pridávame, toľko a rozdelíme.
Nepretržité náhodné množstvo
Pre nepretržite distribuovanú hodnotu F (x) (Displaystyle F (x)), aritmetický priemer na segmente [A; b] (Displaystyle) je definovaný špecifickým integrálom:
F (x) ¯ [A; b] \u003d 1 B - A ∫ ABF (X) DX (Displaystyle (slnečný (F (X))) _ () \u003d (\\ frac (1) (BA)) int _ (a) ^ (b) f (x) dx)
Niektoré problémy s použitím priemeru
Žiadna robustnosť
Hlavný článok: Robustnosť v štatistikeHoci aritmetický priemer sa často používa ako stredné hodnoty alebo centrálne trendy, táto koncepcia sa nevzťahuje na robustné štatistiky, čo znamená, že aritmetický priemer podlieha silnému vplyvu "veľké odchýlky". Je pozoruhodné, že pre rozdelenie s veľkým koemmetrickým koeficientom nesmie aritmetický priemer nemusí zodpovedať koncepcii "priemerného", a význam robustných štatistík (napríklad medián) môže lepšie opísať centrálny trend.
Klasickým príkladom je výpočet príjmov. Aritmetický priemer môže byť nesprávne interpretovaný ako medián, čo je dôvod, prečo je možné dospieť k záveru, že ľudia s veľkým príjmom viac ako v skutočnosti. "Priemerný" príjem je interpretovaný takým spôsobom, že príjmy väčšiny ľudí sú blízko tohto čísla. Toto "médium" (v zmysle priemerného aritmetického) príjmu je vyšší ako príjem väčšiny ľudí, pretože vysoký príjem s veľkou odchýlkou \u200b\u200bod priemeru robí silnú príhovor priemerného aritmetiky (na rozdiel od toho, priemer Príjem o strednom "odoláva" na takéto skreslenie). Tento "priemerný" príjem však nehovorí o počte ľudí v blízkosti stredného príjmu (a nič o počte ľudí v blízkosti príjmu modálneho). Avšak, ak je ľahké prevzaté na koncepty "priemerného" a "väčšiny ľudí", potom je možné urobiť neúplný záver, že väčšina ľudí má vyšší príjem, ako sú naozaj. Napríklad správa o "priemernom" čistým príjmom v Medine, Washingtone, vypočítaná ako aritmetický priemer všetkých ročných čistých príjmov obyvateľov, bude prekvapivo veľký počet kvôli Bill Gates. Zvážte vzorku (1, 2, 2, 2, 3, 9). Aritmetický priemer je 3.17, ale päť hodnôt šesť pod týmto priemerom.
Komplexné percento
Hlavný článok: Investície do návratuAk čísla násobiť, ale nie skladať, Je potrebné použiť priemerný geometrický a nie aritmetický priemer. Najčastejšie sa tento incident stane pri výpočte návratnosti investícií do financií.
Napríklad, ak akcie klesli o 10% v prvom roku, a v druhom roku sa zvýšili o 30%, potom nesprávne vypočítali "priemerný" zvýšenie v týchto dvoch rokoch ako priemerný aritmetický (-10% + 30%) / 2 \u003d 10%; Správnym priemerom v tomto prípade je celkové ročné miery rastu, podľa ktorého sa ročný rast získava len asi 8,16653826392% ≈ 8,2%.
Dôvodom je, že percentá majú nový východiskový bod zakaždým: 30% je 30% z menšej ako ceny na začiatku prvého roka, číslo: Ak sa akcie na začiatku stojí 30 dolárov a klesli o 10%, na začiatku druhého roka sú 27 USD. Ak sa zásoby zvýšili o 30%, na konci druhého roka sú 35,1 USD. Aritmetický priemer tohto nárastu je 10%, ale pretože zásoby sa zvýšili o viac ako 2 roky len 5 rokov, priemerný nárast o 8,2% dáva konečný výsledok 35,1 USD:
[$ 30 (1 - 0,1) (1 + 0,3) \u003d $ 30 (1 + 0,082) (1 + 0,082) \u003d $ 35.1]. Ak sa používa rovnako ako priemerná aritmetická hodnota 10%, nedostávame skutočnú hodnotu: [$ 30 (1 + 0.1) (1 + 0.1) \u003d $ 36.3].
Komplexné percento na konci 2 roky: 90% * 130% \u003d 117%, to znamená, že celkový nárast o 17% a priemerné ročné komplexné percento 117% ≈ 108,2% (\\ t \\ t )) Cca 108,2%), to znamená priemerný ročný nárast o 8,2%.
Smery
Hlavný článok: Štatistiky smerovPri výpočte priemerných aritmetických hodnôt premennej meniace sa cyklicky (napríklad fáza alebo uhol), by sa mala vykazovať zvláštna opatrnosť. Napríklad priemerné čísla 1 ° a 359 ° bude 1 ∘ + 359 ∘ 2 \u003d (displejstyle (1 ^ (1 circ) +359 ^ (circ)) (2)) \u003d) 180 °. Toto číslo je nesprávne z dvoch dôvodov.
- Po prvé, uhlové opatrenia sú definované len pre rozsah od 0 ° do 360 ° (alebo od 0 do 2π, keď sa merajú v radiánoch). Takže rovnaký pár čísel by mohol byť napísaný ako (1 ° a -1 °) alebo oboje (1 ° a 719 °). Priemerné hodnoty každej z párov budú odlišné: 1 ∘ + (- 1 ∘) 2 \u003d 0 ∘ (Displaystyle (1 ^ (kV) + (- 1 ^ (circ))) (2)) \u003d 0 ^ (circ)), 1 ∘ + 719 ∘ 2 \u003d 360 ∘ (Displaystyle (1 ^ (Circ) +719 ^ (circ)) (2)) \u003d 360 ^ (Circ)).
- Po druhé, v tomto prípade bude hodnota 0 ° (ekvivalentná 360 °) geometricky lepšími priemernými hodnotami, pretože čísla sa líšia od 0 ° menej ako z akejkoľvek inej hodnoty (v hodnote 0 ° najmenšej disperzie). Porovnajte:
- Číslo 1 ° sa deje od 0 ° do 1 °;
- počet 1 ° odchýl od vypočítaného média rovného 180 °, 179 °.
Priemerná hodnota pre cyklickú premennú vypočítanú podľa vyššie uvedeného vzorca bude umelo posunutá vzhľadom na súčasný priemer k stredu číselného rozsahu. Z tohto dôvodu sa priemer vypočíta iným spôsobom, menovite číslo s najmenšou disperziou (stredový bod) je vybraný ako priemerná hodnota. Až namiesto odčítania sa používa modulárna vzdialenosť (to znamená, že vzdialenosť okolo obvodu). Napríklad modulárna vzdialenosť medzi 1 ° a 359 ° je 2 °, a nie 358 ° (na kruhu medzi 359 ° a 360 ° \u003d\u003d 0 ° - jeden stupeň, medzi 0 ° a 1 ° - tiež 1 ° suma - 2 °).
Vážený priemer - Čo je to a ako to vypočítať?
V procese štúdia matematiky sa školáci oboznámili s koncepciou priemerného aritmetiky. V budúcnosti, v štatistikách a niektorých iných vedách, študenti čelia výpočtu iných priemerných hodnôt. Čo môžu byť a čo sa líšia od seba?
Stredné hodnoty: Význam a rozdiely
Nie vždy presné ukazovatele dávajú pochopenie situácie. S cieľom vyhodnotiť toto alebo toto prostredie je niekedy potrebné analyzovať obrovské množstvo čísel. A potom stredné hodnoty prichádzajú na záchranu. Je to oni, ktorí nám umožňujú posúdiť situáciu vo všeobecnosti.
 Zoškodských časov, mnohí dospelí pamätajú existenciu priemernej aritmetiky. Je veľmi ľahko vypočítať - súčet sekvencie z n členov je rozdelený na n. To znamená, že ak potrebujete vypočítať aritmetický priemer v sekvencii hodnôt 27, 22, 34 a 37, je potrebné vyriešiť expresiu (27 + 22 + 34 + 37) / 4, pretože 4 hodnoty sa používajú vo výpočtoch. V tomto prípade sa požadovaná hodnota rovná 30.
Zoškodských časov, mnohí dospelí pamätajú existenciu priemernej aritmetiky. Je veľmi ľahko vypočítať - súčet sekvencie z n členov je rozdelený na n. To znamená, že ak potrebujete vypočítať aritmetický priemer v sekvencii hodnôt 27, 22, 34 a 37, je potrebné vyriešiť expresiu (27 + 22 + 34 + 37) / 4, pretože 4 hodnoty sa používajú vo výpočtoch. V tomto prípade sa požadovaná hodnota rovná 30.
V rámci školského roka sa študuje priemerný geometrický rok. Výpočet tejto hodnoty je založený na extrakcii koreňa stupňa N-neo z produktu N-členov. Ak budete mať rovnaké čísla: 27, 22, 34 a 37, výsledok výpočtov bude rovný 29.4.
Priemerná harmonická na strednej škole zvyčajne nepodlieha štúdiu. Napriek tomu sa používa celkom často. Táto hodnota je inverzná na priemernú aritmetiku a vypočítané ako súkromné \u200b\u200bz N - počet hodnôt a súčtov 1 / A 1 + 1 / A 2 + ... + 1 / A n. Ak opäť budete mať rovnaký počet čísel, aby ste vypočítať, potom bude harmonická 29,6.

Vážený priemer: Vlastnosti
Všetky vyššie uvedené hodnoty však môžu byť použité všade. Napríklad v štatistike pri výpočte niektorých priemerných hodnôt má dôležitú úlohu "hmotnosť" každého čísla použitého vo výpočtoch. Výsledky sú presnejšie a správne, pretože berú do úvahy viac informácií. Táto skupina hodnôt je spoločný názov "vážený priemer". Nie sú držaní v škole, takže by mali byť viac.
Po prvé, stojí za to povedať, čo znamená "hmotnosť" jednej alebo inej hodnoty. Najjednoduchší spôsob, ako to vysvetliť v konkrétnom príklade. Dvakrát denne v nemocnici nastane telesná teplota každého pacienta. Zo 100 pacientov v rôznych oddeleniach nemocnice bude mať 44 normálnu teplotu - 36,6 stupňa. 30 viac sa zvýši - 37,2, na 14 - 38, v 7 - 38.5, v 3 - 39, a v dvoch zostávajúcich - 40. A ak si vezmete aritmetický priemer, táto hodnota bude vo všeobecnosti v nemocnici Viac ako 38 stupňov! Ale takmer polovica pacientov je úplne normálna teplotou. A tu bude správne používať vážený priemer a "hmotnosť" každej hodnoty bude počet ľudí. V tomto prípade bude výsledok výpočtu 37,25 stupňov. Rozdiel je zrejmý.
V prípade vážených priemerných výpočtov pre "hmotnosť", počet zásielok, počet ľudí pracujúcich v konkrétnom dni, vo všeobecnosti, čokoľvek, čo možno merať a ovplyvniť konečný výsledok.


Odrody
Vážený priemer korelovaný s priemerným aritmetickým, diskutovaným na začiatku článku. Avšak prvá veľkosť, ako už bolo spomenuté, zohľadňuje aj hmotnosť každého počtu použitého vo výpočtoch. Okrem toho sú tiež vážené priemerné geometrické a harmonické významy.
Tam je ďalšia zaujímavá odroda používaná v radoch čísel. Hovoríme o pozastavenej strednej hodnote. Je založený na svojich základných trendoch. Okrem samotných hodnôt a ich hmotnosti sa tam používa periodicita. A pri výpočte priemernej hodnoty v určitom čase sa zohľadňujú aj hodnoty pre predchádzajúce časové segmenty.
Výpočet všetkých týchto hodnôt nie je tak komplikovaný, ale v praxi sa zvyčajne používa len zvyčajný vážený priemer.
Metódy výpočtu
Vo veku kuchynského počítača nie je potrebné vypočítať vážený priemer manuálne. Bude však potrebné poznať vzorec výpočtu, takže v prípade potreby môžete skontrolovať a opraviť získané výsledky.
Najjednoduchší spôsob, ako zvážiť výpočet v konkrétnom príklade.
Je potrebné vedieť, aká je priemerná odmena práce v tomto podniku, pričom sa zohľadní počet pracovníkov, ktorí dostávajú jeden alebo iný zárobok.
Výpočet váženej priemernej hodnoty sa teda vykoná s použitím takéhoto vzorca:
x \u003d (A 1 * W 1 + A 2 * W 2 + ... + A N * W N) / (W 1 + W 2 + ... + W N)
Napríklad výpočet bude takáto:
x \u003d (32 * 20 + 33 * 35 + 34 * 14 + 40 * 6) / (20 + 35 + 14 + 6) \u003d (640 + 1155 + 476 + 240) / 75 \u003d 33,48
Samozrejme neexistujú žiadne zvláštne ťažkosti, aby sa manuálne vypočítali vážený priemer. Vzorec pre výpočet tejto hodnoty v jednej z najobľúbenejších aplikácií s vzorcami - Excel vyzerá ako funkcia sumbage (počet čísel; počet váh) / súčet (rozsah hmotnosti).
Ako nájsť priemernú hodnotu v programe Excel?
ako nájsť priemerný aritmetický v programe Excel?
Vladimir09854
Ako ľahko ako koláč. Aby ste našli priemernú hodnotu v programe Excel, budete potrebovať iba 3 bunky. V prvom pilíme jedno číslo, v druhom - druhé. A v tretej bunke strelíme vzorec, ktorý budeme dávať priemernú hodnotu medzi týmito dvoma číslami z prvej a druhej bunky. Ak sa číslo 1 bunky nazýva A1, číslo 2 buniek sa nazýva B1, potom v bunke so vzorcom, ktoré potrebujete na napísanie:
Tento vzorec sa vypočíta aritmetickým priemerom dvoch čísel.
Pre krásu našich krajov môžete vybrať bunky s riadkami, ako tanier.
Stále existuje funkcia určovania priemernej hodnoty vo väčšine Excel, ale používam metódu Dedov a zaviedol vzorca I potreby. Takže som si istý, že Excel považuje presne tak, ako potrebujem, a nebudem myslieť na nejaký druh zaokrúhľovania.
M3sergey.
Je to veľmi jednoduché, ak sú údaje už zadané v bunkách. Ak ste jednoducho zaujímali o číslo, stačí vyzdvihnúť požadovaný rozsah / rozsahy, a v dolnej časti priamo v stavovom riadku sa zobrazí hodnota týchto čísel, ich aritmetický priemer a ich množstvo.
Môžete si vybrať prázdnu bunku, kliknite na trojuholníkové (rozbaľovacie listy) "avosem" a vyberte "Priemerný" Tam, po ktorom bude súhlasiť s navrhovaným rozsahom pre výpočet, alebo si vybrať jeho vlastné.
Nakoniec môžete použiť formulárne vzorce priamo - Kliknite na tlačidlo "Vložiť funkciu" vedľa reťazca vzorca a bunkovú adresu. Funkcia Srvnov je v kategórii "Štatistická", a trvá ako argumenty ako počet a odkazy na bunky, atď. Zdá sa, že si môžete vybrať aj na výber zložitejších možností, napríklad je možné vypočítať priemer pre stav.
Nájsť priemer v programe Excel Je to pomerne jednoduchá úloha. Tu je potrebné pochopiť - či chcete použiť tento priemer v niektorých vzorcoch alebo nie.
Ak potrebujete získať iba hodnotu, stačí vyzdvihnúť potrebný rozsah čísel, potom, čo program Excel automaticky vypočíta priemernú hodnotu - zobrazí sa v stavovom riadku, "Priemerná" hlavička.
V prípade, že chcete použiť výsledok vo vzorcoch, môžete to urobiť:
1) Zhrňte bunky s použitím množstva sumy a rozdeliť toto všetko podľa počtu čísel.

2) Správnejšou možnosťou je použitie špeciálnej funkcie s názvom CRNVOLD. Argumenty tejto funkcie môžu byť číslami uvedené v sérii alebo rozsahu čísel.


Vladimir Tikhonov
riadiť hodnoty, ktoré budú zapojené do výpočtu, kliknite na kartu "Formulára", uvidíte tam na ľavej strane je "Autoemb" a vedľa neho trojuholník nasmerovaný dole. V blízkosti tohto trojuholníka a vyberte "Priemerný". Voila, pripravený) v spodnej časti stĺpca uvidí priemernú hodnotu :)
Ekaterina mulalapova
Začnime sa najprv a v poriadku. Čo znamená priemerný význam?
Priemerná hodnota je hodnota, ktorá je priemernou aritmetickou hodnotou, t.j. Vypočíta sa pridaním množiny čísel s následným rozdelením celého množstva čísel na ich čísle. Napríklad pre čísla 2, 3, 6, 7, 2 bude 4 (množstvo čísel 20 delených ich číslom 5)
V tabuľke Excel, som osobne, najjednoduchší spôsob, ako použiť vzorca \u003d srnvov. Ak chcete vypočítať priemernú hodnotu, musíte zadať údaje v tabuľke, v stĺpci DATA, napíšte funkciu \u003d CPNPH () a v zátvorkách označte rozsah čísel v bunkách, zvýraznite stĺpec s údajmi. Potom stlačte vstup, alebo stačí kliknúť na ľavé tlačidlo myši na ľubovoľnej bunke. Výsledok sa zobrazí v bunke pod stĺpcom. Zdá sa, že nie je jasné, ale v skutočnosti - minulý prípad.
Dobrodružstvo Finder 2000.
Ecxelový program je rôznorodý, preto existuje niekoľko možností, ktoré vám umožnia nájsť priemernú hodnotu:
Prvá možnosť. Jednoducho sumarizujte všetky bunky a rozdeľte ich;
Druhá možnosť. Využite špeciálny tím, napíšte požadovaný bunkový vzorec "\u003d srvna (a tu špecifikuje rozsah buniek)";
Tretia možnosť. Ak vyberiete požadovaný rozsah, uviedli, že priemerná hodnota v týchto bunkách sa zobrazí aj na stránke na dne.
Spôsoby, ako nájsť priemernú hodnotu, je teda veľmi, stačí si vybrať to najlepšie pre vás a používať ho neustále.
V programe Excel sa môže vypočítať aritmetická jednoduchosť pomocou funkcie SRVNAF. Ak to chcete urobiť, musíte riadiť množstvo hodnôt. Stlačte tlačidlo rovnaké a vyberte v štatistickej kategórii, medzi ktorými si vyberte funkciu CPN



Aj s pomocou štatistických vzorcov je možné vypočítať aritmeticky vážené aritmetikum, ktoré sa považujú za presnejšie. Ak chcete vypočítať, potrebujeme hodnoty indikátora a frekvencie.
Ako nájsť priemernú hodnotu v programe Excel?
Táto situácia. Existuje nasledujúca tabuľka:
V stĺpcoch namaľovaných v červenej farbe obsahuje numerické hodnoty odhadov na subjekty. V stĺpci stredného skóre musíte vypočítať ich priemernú hodnotu.
Problém je tento: Všetky položky 60-70 a niektoré z nich na inom liste.
Pozrel som sa do iného dokumentu, ktorý už vypočítaný priemer a v bunke sa nachádza typ vzorca
\u003d "Názov zoznamu"! | E12
Ale to urobil nejaký programátor, ktorý bol vyhodený.
Povedz mi, prosím, kto to chápe.
Herecko
V rade FCCS vložte z navrhovaných funkcií "SRVNAK" a vyberte si, kde by sa mali vypočítať (B6: N6) pre Ivanov. Neviem o susedných listoch, ale určite je obsiahnutý v štandardnom certifikáte systému Windows
Povedzte mi, ako vypočítať priemernú hodnotu v Slove
Prosím, povedzte mi, ako vypočítať priemernú hodnotu v Slove. Priemerná hodnota odhadov, a nie počet ľudí, ktorí dostali odhady. 
Julia Pavlova
Slovo môže veľa s makrámi. Kliknite na ALT + F11 a napíšte makro program ..
Okrem toho, objekt vložka ... vám umožní používať iné programy, aspoň excel, vytvoriť hárok s tabuľkou v dokumente programu Word.
Ale v tomto prípade musíte zaznamenať svoje čísla do stĺpca tabuľky av dolnej bunke toho istého stĺpca, aby ste vložili priemer, správne?
Ak to chcete urobiť, vložte pole na dno bunky.
Vkladacie pole ... -formula
Obsah poľa
[\u003d Priemer (vyššie)]
Vydáva priemer sumy nad ležiacich buniek.
Ak je pole zvýraznené a stlačte pravé tlačidlo myši, môže byť aktualizované, ak sa čísla zmenili,
Zobrazenie kódu alebo hodnoty poľa, zmeňte kód priamo do poľa.
Ak sa niečo zhoršuje, odstráňte celé pole v bunke a vytvorte znova.
Priemerné prostriedky priemer, vyššie, to znamená, že číslo nad ležiacich buniek.
To všetko som nepoznal sám seba, ale bolo to ľahké nájsť v pomoci, samozrejme, trochu myslenia.
Pamätajte si!
Na nájsť priemerný aritmetický, Je potrebné zložiť všetky čísla a rozdeliť ich sumu na ich číslo.
Nájdite aritmetický priemer 2, 3 a 4.
Označujú aritmetické písmeno "m". Podľa definície nájdeme množstvo všetkých čísel vyššie.
Rozdeľujeme sumu, ktorú dostane počet prijatých číslami. Pod podmienkou tri čísla.
V dôsledku toho sa dostaneme stredný aritmetický vzorec:

Aký je priemerný aritmetický?
Okrem toho sa neustále ponúkne, že ho nájde v lekciách, nájsť priemerný aritmetický je veľmi užitočný av živote.
Napríklad ste sa rozhodli predať futbalové lopty. Ale keďže ste v tejto veci nováčik, je úplne nezrozumiteľná za akú cenu predať lopty.
Potom sa rozhodnete zistiť, akú cenu vo vašej oblasti už predávajte futbalové lopty konkurentov. Učíme sa ceny v obchodoch a vytvoríme tabuľku.
Ceny za loptičky v obchodoch boli úplne iné. Akú cenu za predaj futbalového lopty lepšie vybrať?
Ak si vyberiete najnižšie (290 rubľov), potom budeme predať tovar pre stratu. Ak si vyberiete najvyššiu (360 rubľov), potom kupujúci nezískajú futbalové lopty z nás.
Potrebujeme priemernú cenu. Príde na záchranu priemeru.
Vypočítavame priemerné aritmetické ceny futbalových loptičiek:
priemerná cena =
=
290 + 360 + 310
3
= 320
trieť.960
3
Preto sme dostali priemernú cenu (320 rubľov), podľa ktorého môžeme predať futbalový loptu nie je príliš lacný a nie príliš drahý.
Priemerná rýchlosť
Koncept stredného aritmetického konceptu stredná rýchlosť.
Sledovanie pohybu dopravy v meste, môžete vidieť, že autá, potom urýchliť a ísť vysokou rýchlosťou, potom spomaliť a ísť s malou rýchlosťou.
Existuje mnoho takýchto miest na ceste vozidiel. Preto pre pohodlie výpočtov sa používa koncepcia priemernej rýchlosti pohybu.
Pamätajte si!
Priemerná rýchlosť je celá cesta na rozdelenie pre celý pohyb.

Zvážte celkovú úlohu rýchlosti.
Číslo úloh 1503 z učebnice "Vilenkin Grade 5"
Auto sa pohybovalo 3,2 hodiny po diaľnici rýchlosťou 90 km / h, potom 1,5 hodiny na prašnej ceste rýchlosťou 45 km / h, konečne 0,3 h na hľadanej ceste rýchlosťou 30 km / h. Nájdite priemernú rýchlosť vozidla pre všetko cestu.
Ak chcete vypočítať priemernú rýchlosť pohybu, musíte poznať celú cestu odovzdané autom, a po celú dobu, kedy sa auto presunulo.
S 1 \u003d v 1 t 1S 1 \u003d 90 · 3.2 \u003d 288 (km)
- diaľnica.S2 \u003d v 2 t2
S 2 \u003d 45 · 1,5 \u003d 67,5 (km) - Dirt Road.
S 3 \u003d v 3 t3
S 3 \u003d 30 · 0,3 \u003d 9 (km) - hľadá cestu.
S \u003d S 1 + S 2 + S 3
S \u003d 288 + 67,5 + 9 \u003d 364,5 (km) - celú cestu prešiel autom.
T \u003d t 1 + t 2 + t 3
T \u003d 3,2 + 1,5 + 0,3 \u003d 5 (h) - po celú dobu.
V CP \u003d S: t
V CF \u003d 364,5: 5 \u003d 72,9 (km / h) - priemerná rýchlosť auta.
Odpoveď: v CF \u003d 72,9 (km / h) - priemerná rýchlosť auta.
Aby ste našli priemernú hodnotu v programe Excel (bez numerického, textu, percentuálneho podielu alebo inej hodnoty), existuje mnoho funkcií. A každý z nich má svoje vlastné charakteristiky a výhody. V tejto úlohe môžu byť doručené určité podmienky.
Napríklad priemerné hodnoty počtu počtov v programe Excel sa považujú za štatistické funkcie. Môžete tiež manuálne zadať svoj vlastný vzorec. Zvážte rôzne možnosti.
Ako nájsť priemerné aritmetické čísla?
Ak chcete nájsť aritmetický priemer, je potrebné zložiť všetky čísla v súprave a rozdeliť sumu podľa sumy. Napríklad, školácky odhad na počítačovej vede: 3, 4, 3, 5, 5. Čo ide nad rámec štvrtinu: 4. Zistili sme aritmetický priemer podľa vzorca: \u003d (3 + 4 + 3 + 5 + 5) / 5.
Ako rýchlo využívať funkcie programu Excel? Vezmite si napríklad rad náhodných čísel v reťazci:

Alebo: Robíme aktívnu bunku a jednoducho manuálne zapôsobí na vzorec: \u003d Srvnov (A1: A8).
Pozrime sa teraz, čo je stále schopné fungovať.

Nájdeme aritmetický priemer prvých dvoch a troch posledných čísel. Vzorec: \u003d Srnavov (A1: B1; F1: H1). Výsledok:
Priemerná hodnota podľa stavu
Podmienka na nájdenie priemerného aritmetika môže byť číselné kritérium alebo text. Budeme používať funkciu: \u003d Сростовсилили ().
Nájdite priemerné aritmetické čísla, ktoré sú väčšie alebo rovné 10.
FUNKCIA: \u003d CRPISNESSIBLE (A1: A8; "\u003e \u003d 10")
 Výsledkom je použitie funkcie SRVNABLE pod podmienkou "\u003e \u003d 10":
Výsledkom je použitie funkcie SRVNABLE pod podmienkou "\u003e \u003d 10": Tretí argument je "priemerný rozsah" - vynechaný. Najprv sa to nevyžaduje. Po druhé, program analyzovaný programom obsahuje iba numerické hodnoty. V bunkách uvedených v prvom argumente a vyhľadávanie bude vybrané v druhom argumente.
Pozor! Kritériá vyhľadávania môžu byť uvedené v bunke. A vo vzore, aby sa na ňom urobili odkaz.
Priemerná hodnota čísel nájdeme podľa textových kritérií. Napríklad priemerné predaje tovaru "tabuľky".

Funkcia bude vyzerať takto: \u003d CRPN ($ A $ 2: $ A $ 12; A7; $ B $ 2: $ B $ 12). Rozsah - stĺpec s názvami produktov. Kritériá vyhľadávania - odkaz na bunku so slovom "Tabuľky" (namiesto odkazu A7 môžete vložiť slovo "tabuľky". Priemerný rozsah - tie bunky, z ktorých sa budú považovať za výpočet priemernej hodnoty.
V dôsledku výpočtu funkcie získavame nasledujúcu hodnotu:
Pozor! Pre kritériá textu (podmienky) sa vyžaduje spriemerný rozsah.
Ako vypočítať váženú priemernú cenu v programe Excel?

Ako sme sa naučili váženú priemernú cenu?
Vzorec: \u003d sumpure (C2: C12; B2: B12) / Sums (C2: C12).

S pomocou Sump vzorec sa učíme všeobecné príjmy po predaji celého tovaru. A funkcia množstva - počet tovarov pochopí. Zdieľanie celkových príjmov z predaja tovaru na celkovom počte výrobkov sme našli váženú priemernú cenu. Tento ukazovateľ zohľadňuje "hmotnosť" každej ceny. Jeho podiel na celkovej hmotnosti hodnôt.
Priemerná kvadratická odchýlka: Vzorec v Excel
Existujú štandardné odchýlky na všeobecnej populácii a vzorke. V prvom prípade je to koreň všeobecnej disperzie. V druhej - od selektívnej disperzie.
Na výpočet tohto štatistického indikátora sa vypracuje disperzná vrstva. Koreň sa z nej extrahuje. Ale v programe Excel je dokončená funkcia pre nájdenie štandardnej odchýlky.

Odchýlka RMS má záväznú na stupnicu zdrojových údajov. Pre obrazový pohľad na zmenu analyzovaného rozsahu nestačí. Na získanie relatívnej úrovne rozptylu dát sa vypočíta variačný koeficient:
rMS Odchýlka / priemerná aritmetická hodnota
Vzorec v programe Excel vyzerá takto:
Standotclick (rozsah hodnôt) / srvnow (rozsah hodnôt).
Variant koeficientu sa považuje za percentuálny podiel. Preto v bunke vytvoríme percentuálny formát.
Priemerná plat ... Priemerná dĺžka života ... Takmer každý deň počujeme tieto frázy používané na opis súboru jedným číslom. Ale zvláštne, "priemerný význam" je pomerne mazaný koncept, často zavádzajúci uzavretie obvyklého, neskúseného v matematickej štatistike, osobe.
Aký je problém?
Pod priemernou hodnotou je aritmetický priemer najčastejšie rozumie, ktorý sa veľmi líši pod vplyvom jednotlivých faktov alebo udalostí. A nedostávate skutočnú predstavu o tom, ako sú hodnoty, ktoré študujete.
Poďme sa obrátiť na klasický príklad so stredným platom.
V niektorých abstraktnej spoločnosti pracuje desať zamestnancov. Deväť z nich dostáva platu asi 50 000 rubľov a jeden 1 500 000 rubľov (podivnou náhodou, je generálnym riaditeľom tejto spoločnosti).
Priemerná hodnota v tomto prípade bude 195 150 rubľov, ktorá sa nesprávne dohodne.
Aké spôsoby výpočtu priemeru sú tam?
Prvým spôsobom je výpočet už uvedenej stredný aritmetickýktorý je súčtom všetkých hodnôt vydelených ich číslom.

- x je aritmetický priemer;
- x N. - betónová hodnota;
- n - počet hodnôt.
- Dobre funguje s normálnou distribúciou hodnôt vo vzorke;
- Ľahko vypočítať;
- Intuitívne zrozumiteľné.
- Nedáva reálnu predstavu o rozdelení hodnôt;
- Nestabilná veľkosť ľahko emisií (ako v prípade CEO).
Druhým spôsobom je výpočet módaTo znamená, že najbežnejší význam.
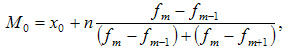
- M 0 - móda;
- x 0. - spodnú hranicu intervalu, ktorý obsahuje módu;
- n - veľkosť intervalu;
- f M - frekvencia (koľkokrát v rade sa nachádza alebo iná);
- f M-1 - frekvencia intervalu predchádzajúceho modálneho;
- f M + 1 - Frekvencia intervalu po modálnom.
- Dokonale vhodné na prípravu verejnej mienky;
- Dobre vhodné pre nečíselné údaje (farby sezóny, predajné hity, ratingy);
- Ľahko porozumieť.
- Móda jednoducho nie je (bez opakovania);
- MOD môže byť trochu (multimodálna distribúcia).
Tretím spôsobom je výpočet mediány, to znamená, že hodnoty, ktoré rozdeľujú objednanú vzorku na dve polovice a nachádzajú sa medzi nimi. A ak nie je takáto hodnota, potom sa medián prijíma aritmetický priemer medzi hranicami polovice vzorky.

- M e - medián;
- x 0. - spodnú hranicu intervalu, ktorý obsahuje medián;
- h - veľkosť intervalu;
- f I - Frekvencia (koľkokrát v rade sa nachádza alebo iná);
- S M-1 - súčet frekvencií intervalov predchádzajúceho mediánu;
- f M je počet hodnôt v strednom intervale (jeho frekvencia).
- Poskytuje najrealistickejšie a reprezentatívne hodnotenie;
- Odolné voči emisiám.
- Je ťažšie vypočítať, pretože pred výpočtom vzorky musíte zefektívniť.
Prehodnotili sme základné metódy nájdenia priemery opatrenia ústrednej tendencie(V skutočnosti sú viac, ale tieto sú najobľúbenejšie).
A teraz sa vráťte do nášho príkladu a zvážte všetky tri varianty priemeru pomocou špeciálnych funkcií programu Excel:
- (NUMBER1; [NUMBER2]; ...) - Funkcia na určenie priemerného aritmetika;
- Fashion.one (Number1; [Number2]; ...) - Fashion Funkcia (v starších verziách programu Excel, MOD (Number1; [Number2]; ...));
- Medián (číslo1; [Number2]; ...) - Funkcia pre vyhľadávanie Mediánov.
A aké hodnoty sme dostali:

V tomto prípade je móda a medián oveľa lepšie charakterizovaná priemernou platovou v spoločnosti.
Ale čo robiť, keď vo vzorke nie 10 hodnôt, ako je napríklad v príklade a milióny? V programe Excel to nepočítate, ale v databáze, kde sú vaše údaje uložené bez problémov.
Vypočítajte aritmetický priemer na SQL
Všetko je dosť jednoduché, pretože SQL poskytuje špeciálnu AVG agregovanú funkciu.
A použiť ho dosť na to, aby ste túto požiadavku napísali:
Vypočítajte módu na SQL
V SQL neexistuje samostatná funkcia nájsť módu, ale môže to byť ľahko a rýchlo nezávisle. Aby sme to urobili, musíme vedieť, ktorý plat je najčastejšie opakovaný a výber najobľúbenejšie.
Píšeme žiadosť:
/ * S väzbami je potrebné pridať do top (), ak mnoho multimodálnych, t.j. množstvo viacerých mod * / vyberte TOP (1) s platovou platovou ako "módne mzdy" od skupiny zamestnancov podľa platu objednávky podľa počtu (*)
Vypočítajte medián na SQL
Rovnako ako v prípade módy, v SQL neexistuje vstavaná funkcia na výpočet mediánu, ale je tu univerzálna funkcia pre výpočet percentile_cont percentil.
Vyzerá to takto:
/ * V tomto prípade v tomto prípade percentil 0.5 a bude medián * / vyberte TOP (1) percentIle_cont (0,5) v rámci skupiny (objednávka podľa platu) nad () ako "stredný plat" od zamestnancov
Prečítajte si viac o prevádzke funkcie percentIle_cont je lepšie prečítať v Microsoft a Google Bigquery Pomocník.
Aká metóda stále používa?
Z vyššie uvedeného vyplýva, že medián je najlepší spôsob, ako vypočítať priemernú hodnotu.
Ale nie vždy to tak. Ak pracujete s priemerom, dajte si pozor na multimodálnu distribúciu:

Graf ukazuje bimodálnu distribúciu s dvoma vrcholmi. Takáto situácia môže nastať napríklad pri hlasovaní vo voľbách.
V tomto prípade je aritmetický a medián významy, ktoré sú niekde uprostred a nepovedia nič o tom, čo sa naozaj deje a lepšie uznať, že sa zaoberáte bimodálnou distribúciou, hovorí dva mody.
Je ešte lepšie rozdeliť vzorku do dvoch skupín a zbierať štatistické údaje pre každú.
Výkon:
Pri výbere spôsobu nájdenia priemeru musíte zohľadniť dostupnosť emisií, ako aj normálnosť distribúcie hodnôt vo vzorke.
Konečná voľba centrálnych opatrení trendu vždy leží analytik.
Vo väčšine prípadov sa údaje sústreďujú okolo určitého centrálneho bodu. Ak chcete opísať akýkoľvek súbor údajov, stačí špecifikovať priemernú hodnotu. Zvážte postupne tri číselné charakteristiky, ktoré sa používajú na odhad priemernej hodnoty distribúcie: aritmetický, stredný a módny.
Priemeru
Aritmetický priemer (často nazývaný jednoducho médium) je najčastejšie hodnotenie priemernej distribučnej hodnoty. Je to výsledok rozdelenia súčtu všetkých pozorovaných numerických hodnôt na ich číslo. Pre odber vzoriek pozostávajúce z čísel X 1, X 2, ..., X N., selektívny priemer (označený symbol ) Rovnocenné \u003d (X 1 + x 2 + ... + x N.) / n., alebo
kde - selektívny priemer n. - veľkosť vzorky, X. I. - I-TH prvok vzorky.
Stiahnite si poznámku vo formáte alebo príklady vo formáte
Zvážte výpočet priemernej aritmetickej hodnoty päťročnej ziskovosti 15 podielových fondov s veľmi vysokou úrovňou rizika (obr. 1).

Obr. 1. Priemerná ročná ziskovosť 15 podielových fondov s veľmi vysokou úrovňou rizika
Selektívny priemer sa vypočíta takto:

Toto je dobrý príjem, najmä v porovnaní s 3-4% príjmu, ktorý získal bankových vkladateľov alebo družstvá v rovnakom časovom období. Ak zjednodušujete hodnoty ziskovosti, je ľahké všimnúť si, že osem fondov má výnos, a sedem je pod priemerom. Aritmetický priemer zohráva úlohu rovnováhy, takže fondy s nízkymi príjmami sa bilancia s vysokými príjmami. Pri výpočte priemeru sú zahrnuté všetky prvky vzorky. Žiadny z iných odhadov priemernej distribučnej hodnoty nemá túto vlastnosť.
Keď by sa mali vypočítať aritmetické priemery.Pretože aritmetický priemer závisí od všetkých prvkov vzorky, prítomnosť extrémnych hodnôt významne ovplyvňuje výsledok. V takýchto situáciách môže priemerná aritmetika narušiť význam numerických údajov. Preto popisuje sadu údajov obsahujúcich extrémne hodnoty, musíte špecifikovať medián alebo aritmetický a medián. Napríklad, ak odstránite zo vzorky, výťažok RS vznikajúceho rastového založenia, selektívna priemerná ziskovosť 14 fondov sa zníži o takmer 1% a bude 5,19%.
Medián
Medián je stredná hodnota objednaného radu čísel. Ak pole neobsahuje opakujúce sa čísla, potom polovica jej prvkov bude menej a pol - viac mediánov. Ak vzorka obsahuje extrémne hodnoty, odhadnúť priemernú hodnotu, je lepšie použiť nie je priemerný aritmetický, ale medián. Ak chcete vypočítať medián vzorky, musíte najprv zefektívniť.
Tento vzorec je nejednoznačný. Jeho výsledok závisí od parity alebo podivnosti čísla n.:
- Ak vzorka obsahuje nepárny počet prvkov, medián je rovnaký (n + 1) / 2- Element.
- Ak vzorka obsahuje párny počet prvkov, medián leží medzi dvoma priemernými prvkami vzorky a je rovnaký ako priemerný aritmetický, vypočítaný na týchto dvoch položkách.
S cieľom vypočítať medián vzorky obsahujúcej údaje o výnose 15 podielových fondov s veľmi vysokou úrovňou rizika, musíte najprv zefektívniť zdrojové údaje (obr. 2). Potom bude medián oproti číslu stredného prvku vzorky; V našom príklade číslo 8. V programe Excel je tu špeciálna funkcia \u003d medián (), ktorý funguje aj s neusporiadanými poliami.

Obr. 2. Medián 15 fondy
Medián je teda rovný 6,5. To znamená, že výnos jednej polovice fondov s veľmi vysokou úrovňou rizika nepresahuje 6.5 a výnos druhej polovice - presahuje. Upozorňujeme, že medián rovný 6,5, o niečo väčšiu hodnotu rovnú 6,08.
Ak odstránite výnos rozvíjajúcej fondu rastu RS zo vzorky, potom sa medián zostávajúcich 14 finančných prostriedkov zníži na 6,2%, to znamená, že nie je toľko ako aritmetický priemer (obr. 3).

Obr. 3. Medián 14 fondy
Móda
Termín bol prvýkrát predstavený Pearsonom v roku 1894. Móda je číslo, ktoré sa častejšie nachádzajú vo vzorke (najviac módne). Móda dobre opisuje napríklad typickú reakciu vodiča na signál premávkového svetla. Klasickým príkladom použitia módy je výber veľkosti bravnej dávky alebo farby tapety. Ak má distribúcia niekoľko režimov, hovoria, že je multimodálne alebo multimodálne (má dva alebo viac "píku"). Distribúcia multimodality poskytuje dôležitými informáciami o povahe premennej podľa štúdia. Napríklad v sociologických prieskumoch, ak je premenná preferencia alebo vzťah k niečomu, multimodalita môže znamenať, že existuje niekoľko určitých rôznych názorov. Multimodalita tiež slúži ako indikátor, že vzorka nie je homogénna a pozorovanie, prípadne vytvorená dvoma alebo viacerými "superponovanými" distribúciami. Na rozdiel od priemerného aritmetika, emisie neovplyvňujú. Pre nepretržite distribuované náhodné premenné, napríklad pre ukazovatele priemernej ročnej ziskovosti podielových fondov, móda niekedy neexistuje vôbec (alebo nedáva zmysel). Keďže tieto ukazovatele môžu mať rôzne hodnoty, opakujúce sa hodnoty sú veľmi zriedkavé.
Štvrťrok
Maloobchod sú ukazovatele, ktoré sa najčastejšie používajú na posúdenie distribúcie údajov pri opise vlastností veľkých číselných vzoriek. Zatiaľ čo medián zdieľa objednané pole na polovicu (50% prvkov poľa menej medián a 50% - viac), štvrtina preliate objednané údaje nastavené na štyri časti. Hodnoty Q1, mediánu a q 3 sú 25., 50. a 75. percencou. Prvý kvartil Q1 je číslo oddeľujúce vzorku do dvoch častí: 25% prvkov je menej, a 75% je viac ako prvé štvrťročné.
Tretí kvartil Q 3 je číslo oddeľujúca vzorku aj do dvoch častí: 75% prvkov menších a 25% je viac ako tretie štvrťroky.
Na výpočet štvrtí v Excel verziách do roku 2007 bola použitá funkcia \u003d štvrťrok (pole; časť). Vychádzajúc z verzie Excel2010 sa používajú dve funkcie:
- \u003d Kvartil. Slepý (pole; časť)
- \u003d Kvartil. Harmonogram (pole; časť)
Tieto dve funkcie poskytujú niektoré rôzne hodnoty (obr. 4). Napríklad pri výpočte štvrťroku vzorky obsahujúcej údaje o priemernom ročnom výstupe 15 podielových fondov s veľmi vysokou úrovňou rizika Q1 \u003d 1,8 alebo -0,7 pre kvartil. A štvrťroky. Harmonogram, resp. Mimochodom, použité kvartil, ktoré sa používa skôr zodpovedá modernej funkcii kvartilu. Ak chcete vypočítať štvrtiny v programe Excel pomocou vyššie uvedeného vzorca, nie je možné objednať pole údajov.

Obr. 4. Výpočet štvrtiny v Excel
Znova zdôrazňujeme. Excel môže počítať štvrťroky pre jednorozmerné diskrétny riadokobsahujúce náhodné premenné. Výpočet štvrtiny pre distribúciu na báze frekvencie je uvedený nižšie v sekcii.
Stredný geometrický
Na rozdiel od priemerného aritmetického priemeru, geometrické umožňuje odhadnúť stupeň zmeny v premennej v priebehu času. Priemerný geometrický je koreň n.- stupeň z práce n. Hodnoty (funkcie programu Excel \u003d SRGEOM):
G. \u003d (X 1 * x 2 * ... * x n) 1 / n
Podobný parameter - priemerná geometrická hodnota miery zisku je určená vzorcom:
G \u003d [(1 + R1) * (1 + R2) * ... * (1 + R N)] 1 / N - 1,
kde RI. - miera zisku pre i.-Y čas.
Predpokladajme napríklad, že množstvo investovaných fondov v počiatočnom čase je 100 000 dolárov. Do konca prvého roka klesá na úroveň 50 000 USD, a do konca druhého roka sa obnoví Počiatočná značka vo výške 100 000 USD. Normálny zisk tejto investície pre dvojročné obdobie rovné 0, pretože počiatočné a konečné množstvo finančných prostriedkov sa navzájom rovná. Priemerné aritmetické ročné štandardy zisku sa však rovná \u003d (-0,5 + 1) / 2 \u003d 0,25 alebo 25%, pretože rýchlosť zisku v prvom roku R 1 \u003d (50 000 - 100 000) / 100 000 \u003d - \\ t 0,5 a v druhom R2 \u003d (100 000 - 50 000) / 50 000 \u003d 1. V rovnakej dobe, priemerná geometrická hodnota miery zisku za dva roky je: g \u003d [(1-0,5) * (1 + 1)] 1/2 - 1 \u003d ½ - 1 \u003d 1 - 1 \u003d 0. Priemerný geometrický je presnejší odráža zmenu (presnejšie, absencia zmien) objemu investícií na dvojročné obdobie alebo aritmetický priemer.
Zaujímavosti.Po prvé, priemerná geometrická bude vždy menšia ako priemerná aritmetika rovnakých čísel. S výnimkou prípadu, keď sú všetky prijaté čísla rovnaké. Po druhé, vzhľadom na vlastnosti obdĺžnikového trojuholníka, možno pochopiť, prečo sa priemer nazýva geometrický. Výška obdĺžnikového trojuholníka, znížená na hypotenuse, je priemerná úmerná medzi prognózami katét na hyptootentuse a každá katedrá je priemerná medzi hyptotenuse a jeho projekciou na hypotenuse (obr. 5). To poskytuje geometrickú metódu na výstavbu priemerných geometrických dvoch (dĺžkových) segmentov: je potrebné konštruovať kruh na súčet týchto dvoch segmentov ako v priemere, potom sa výška obnovuje z bodu ich pripojenia k prechodu s Kruh, poskytne prehľadávanú hodnotu:

Obr. 5. Geometrická povaha stredného geometrického (Obrázok z Wikipedia)
Druhá dôležitá vlastnosť numerických údajov je ich variáciacharakterizujúci stupeň disperzie dát. Dve rôzne vzorky sa môžu líšiť podľa priemerných hodnôt a variácií. Ako je však znázornené na obr. 6 a 7, dve vzorky môžu mať rovnaké variácie, ale rôzne stredné hodnoty alebo identické priemery a úplne odlišné variácie. Údaje, ku ktorým polygón zodpovedá na obr. 7 sa líši oveľa menej ako údaje, pre ktoré polygón A.

Obr. 6. Dva symetrické rozdelenie tvaru zvončeka s rovnakou variáciou a rôznymi priemernými hodnotami

Obr. 7. Dve symetrické rozdelenie formulára v tvare zvončeka s rovnakými priemernými hodnotami a rôznym rozptylom
Existuje päť odhadov variácie údajov:
- rozsah
- medzinárodné
- disperzia,
- štandardná odchýlka,
- variácie koeficientu.
Rozsah
Rozsah je rozdiel medzi najväčšími a najmenšími prvkami vzorky: \\ t
Rozsah \u003d H. Max - H. Min.
Odberové rozpätie obsahujúce údaje o priemernej ročnej ziskovosti 15 podielových fondov s veľmi vysokou úrovňou rizika sa môžu vypočítať pomocou objednaného poľa (pozri obr. 4): Rozsah \u003d 18,5 - (-6,1) \u003d 24,6. To znamená, že rozdiel medzi najväčšou a najmenšou priemernou ročnou ziskovosť finančných prostriedkov s veľmi vysokou úrovňou rizika je 24,6%.
Rozsah umožňuje merať celkové variácie údajov. Aj keď je odber vzoriek veľmi jednoduchým odhadom celkového rozpätia údajov, jeho slabosť je, že neberie do úvahy, ako sa distribuujú údaje medzi minimálnymi a maximálnymi prvkami. Tento účinok je dobre sledovaný na obr. 8, ktorý ilustruje vzorky, ktoré majú rovnaký rozsah. Stupnica ukáže, že ak vzorka obsahuje aspoň jednu extrémnu hodnotu, vzorka rozpätie je veľmi nepresný odhad rozptylu dát.

Obr. 8. Porovnanie troch vzoriek s rovnakým rozsahom; Trojuholník symbolizuje podporu váh a jeho umiestnenie zodpovedá priemernej hodnote vzorkovania.
EMERČNÝ ROZSAH
Rozdiel medzi tretím a prvým štvrťrokom vzorky je rozdiel medzi tretím a prvým štvrťrokom vzorky:
Emerquarted rozsah \u003d q 3 - Q 1
Táto hodnota vám umožňuje odhadnúť rozptyl 50% prvkov a neberie do úvahy vplyv extrémnych prvkov. Escarotický rozpätie vzorky obsahujúcej údaje o priemernom ročnom výstupe 15 podielových fondov s veľmi vysokou úrovňou rizika sa môže vypočítať pomocou údajov na obr. 4 (napríklad pre funkciu kvartilu. Sliply): Emerquarted rozsah \u003d 9,8 - (-0,7) \u003d 10,5. Interval obmedzený číslom 9,8 a -0,7 sa často nazýva v polovici polovice.
Treba poznamenať, že hodnoty Q 1 a Q 3, čo znamená, a medzikomunikačný rozsah, nezávisia od prítomnosti emisií, pretože žiadna suma neberie do úvahy, čo by bolo menej ako q 1 alebo Ďalšie q 3. Celkové kvantitatívne charakteristiky, ako sú medián, prvé a tretie štvrťroky, ako aj medzikomunikačný rozsah, ktorým emisie neovplyvňujú, sa nazývajú udržateľné ukazovatele.
Hoci rozsah pôsobnosti a intercomméry môžu vyhodnotiť všeobecné a stredné odber vzoriek, v tomto poradí, žiadne z týchto hodnotení berie do úvahy, ako sú údaje distribuované. Disperzia a štandardná odchýlkatento nedostatok. Tieto ukazovatele vám umožňujú vyhodnotiť stupeň výkyvov údajov okolo priemernej hodnoty. Selektívna disperzia Je to prístup priemernej aritmetiky, vypočítanej na základe štvorcov rozdielov medzi každým prvkom vzorky a selektívneho priemeru. Pre odber vzoriek x 1, x 2, ... x n, selektívna disperzia (symbol S 2 je nastavený nasledujúcim vzorcom:

Vo všeobecnosti je selektívna disperzia súčtom štvorcov rozdielov medzi prvkami vzorky a selektívnym priemerom rozdeleným množstvom rovnajúcou sa veľkosťou vzorky mínus jeden:

kde - aritmetický priemer n. - veľkosť vzorky, X I. - i.Odberový prvok X.. V programe Excel, na verziu 2007, funkcia \u003d displej () sa použila na výpočet selektívnej disperzie, z verzie 2010, funkcie \u003d displeja ().
Najpraktickejší a rozsiahly odhad rozptylu údajov je Štandardná selektívna odchýlka. Tento indikátor je indikovaný symbolom S a je rovný odmocnine od selektívnej disperzie:

V programe Excel, na verziu 2007, funkcia \u003d stanootclone () bola použitá na výpočet štandardnej selektívnej odchýlky, z funkcie verzie 2010 \u003d standotclonal.v (). Na výpočet týchto funkcií môže byť dátové pole neusporiadané.
Ani selektívna disperzia ani štandardná selektívna odchýlka nesmie byť negatívna. Jediná situácia, v ktorej ukazovatele S 2 a S môžu byť nula - ak sú všetky prvky vzorky rovnaké. V tomto úplne neuveriteľnom prípade sú rozsah a medzikomunikačný rozsah tiež nulový.
Číselné údaje podľa premennej prírody. Akákoľvek premenná môže trvať mnoho rôznych hodnôt. Napríklad rôzne podielové fondy majú rôzne ukazovatele ziskovosti a strát. Vzhľadom na variabilitu numerických údajov je veľmi dôležité študovať nielen odhady priemernej hodnoty, ktoré sú celkovo, ale aj vyhodnotenie disperzie charakterizujúceho variáciu údajov.
Disperzia a štandardná odchýlka vám umožňujú odhadnúť variácie údajov okolo priemernej hodnoty, inými slovami, určujú, koľko vzorkovacích prvkov je menej ako priemer, a koľko viac. Disperzia má niektoré cenné matematické vlastnosti. Jeho hodnota je však štvorcový merací jednotka - štvorcové percento, štvorcový dolár, štvorcový palec a podobne. Prirodzeným hodnotením disperzie je preto štandardná odchýlka, ktorá je vyjadrená v obvyklých jednotkách meraní - percento príjmov, dolárov alebo palcov.
Štandardná odchýlka umožňuje odhadnúť hodnotu oscilácie vzorových prvkov okolo priemernej hodnoty. V takmer všetkých situáciách leží hlavná suma pozorovaných hodnôt v intervale plus-mínus jedna štandardná odchýlka od priemernej hodnoty. V dôsledku toho, poznanie priemerných aritmetických prvkov vzorky a štandardnej selektívnej odchýlky, môžete definovať interval, na ktorý patrí hlavná hmotnosť údajov.
Štandardná odchýlka výnosu 15 podielových fondov s veľmi vysokou úrovňou rizika je 6.6 (obr. 9). To znamená, že ziskovosť väčšiny finančných prostriedkov sa líši od priemernej hodnoty najviac 6,6% (t.j. zaváha v rozsahu od - S. \u003d 6.2 - 6.6 \u003d -0,4 + S. \u003d 12,8). V skutočnosti tento interval leží päťročný priemerný ročný výnos 53,3% (8 z 15) fondov.

Obr. 9. Štandardná selektívna odchýlka
Všimnite si, že v procese sčítania štvorcov rozdielov, prvky vzorky, ležiace z priemernej hodnoty, získavajú väčšiu hmotnosť ako prvky ležiace bližšie. Táto vlastnosť je hlavným dôvodom odhadovania priemernej distribučnej hodnoty, najčastejšie sa používa priemerná aritmetická hodnota.
Variácie koeficientu
Na rozdiel od predchádzajúcich odhadov rozptylu je variačný koeficient relatívne hodnotenie. Vždy sa merajú ako percento, a nie v jednotkách merania zdrojových údajov. Koeficient variácie označenej symbolmi CV meria disperziu údajov v porovnaní s priemernou hodnotou. Variant koeficientu sa rovná štandardnej odchýlke rozdelenej aritmetickým priemerom a vynásobený 100%:

kde S. - štandardná selektívna odchýlka, - selektívny priemer.
Koeficient variácie vám umožňuje porovnať dve vzorky, ktorých prvky sú vyjadrené v rôznych meracích jednotkách. Služba dodania riadiacej služby napríklad v úmysle aktualizuje kamiónový park. Pri nakladaní paketov by sa mali zohľadniť dva typy obmedzení: hmotnosť (v librách) a objem (v kubických nohách) každého balenia. Predpokladajme, že vo vzorke obsahujúcom 200 paketov je priemerná hmotnosť 26,0 libier, štandardná hmotnosť odchýlky 3,9 libier, priemerný objem balenia je 8,8 kubických stôp a štandardná odchýlka objemu 2,2 kubických stôp. Ako porovnať rozptyl hmotnosti a balíkov?
Pretože jednotky merania hmotnosti a objem sa od seba navzájom líšia, musí sa riadiť porovnať relatívny rozptyl týchto hodnôt. Koeficient variácie hmotnosti je CV W \u003d 3,9 / 26,0 * 100% \u003d 15%, a variačný koeficient objemu objemu CV V \u003d 2,2 / 8,8 * 100% \u003d 25%. Relatívny rozptyl objem balenia je teda oveľa viac relatívnej rozptylosti ich hmotnosti.
Distribučný formulár
Tretia dôležitá vlastnosť vzorky je formou jeho distribúcie. Táto distribúcia môže byť symetrická alebo asymetrická. Ak chcete opísať distribučný formulár, je potrebné vypočítať jeho priemernú hodnotu a medián. Ak sa tieto dva ukazovatele zhodujú, premenná sa považuje za symetricky rozloženú. Ak je priemerná hodnota premennej väčšia ako medián, jeho distribúcia má pozitívnu asymetriu (obr. 10). Ak je medián väčší ako priemerná hodnota, premenlivá distribúcia má negatívnu asymetriu. Pozitívna asymetria sa vyskytuje, keď sa priemerná hodnota zvyšuje na nezvyčajne vysoké hodnoty. Negatívna asymetria sa vyskytuje, keď priemerná hodnota klesá na nezvyčajne malé hodnoty. Premenná je symetricky distribuovaná, ak neberie žiadne extrémne hodnoty v žiadnom z nás, aby sa vzájomné a malé hodnoty variabilnej rovnováhy navzájom.

Obr. 10. Tri typy distribúcií
Údaje uvedené na stupnici A má negatívnu asymetriu. Na tomto obrázku je viditeľný dlhý chvost a skosenie vľavo, spôsobené prítomnosťou nezvyčajne malých hodnôt. Tieto extrémne malé hodnoty posúvajú strednú hodnotu doľava a stáva sa menej medián. Údaje uvedené na stupnici B sú distribuované symetricky. Ľavá a pravá polovica distribúcie sú ich zrkadlové odrazy. Veľké a malé hodnoty sa rovnováhu navzájom a priemerná hodnota a medián sú rovnaké. Údaje zobrazené na stupnici B majú pozitívnu asymetriu. Na tomto obrázku dlhý chvost a šikmo vpravo, spôsobené prítomnosťou neobvykle vysokých hodnôt. Tieto príliš veľké hodnoty posunuli priemernú hodnotu doprava a stáva sa viac medián.
V programe Excel možno popisné štatistiky získať doplnkom Analýza. Prejdite cez menu Dáta → Analýza dát, V okne, ktoré sa otvorí, vyberte reťazec Deskriptívna štatistika a kliknite Ok.. V okne Deskriptívna štatistika Určite zadajte Vstupný interval(Obr. 11). Ak chcete vidieť popisné štatistiky na tom istom hárku ako zdrojové údaje, vyberte položku Spínača Výstupný interval A špecifikujte bunku, kde by mal byť umiestnený ľavý uhol štatistiky výstupu (v našom príklade $ c $ 1). Ak chcete zobraziť údaje do nového listu alebo v novej knihe, stačí vybrať príslušný spínač. Umiestnite začiatok Záverečná štatistika. Voliteľne si môžete vybrať Obtiažnosť,k-th najmenší ak-Th veľký.
Ak je v zálohe Dáta v oblasti Analýza Nezobrazujete piktogram Analýza dát, musíte predinštalovať doplnok Analýza (Pozri napríklad).

Obr. 11. Popisná štatistika päťročnej priemernej ročnej ziskovosti finančných prostriedkov s veľmi vysokou úrovňou rizika vypočítaných doplnkami. Analýza dátprogramy programu Excel
Excel vypočíta množstvo štatistík, o ktorých sa diskutovalo vyššie: sekundárna, stredná, móda, štandardná odchýlka, disperzia, rozsah ( interval), minimálne, maximálne a odber vzoriek ( skóre). Okrem toho Excel vypočíta niektoré nové štatistiky pre nás: Štandardná chyba, prebytok a asymetria. Štandardná chyba Je rovná štandardnej odchýlke rozdelenej na druhú odmocninu objemu vzorky. Asymetrický Charakterizuje odchýlku od symetrie distribúcie a je funkcia závisí od rozdielu kocky medzi prvkami vzorky a priemernou hodnotou. Prebytok je mierou relatívnej koncentrácie dát okolo priemernej hodnoty v porovnaní s distribučnými chvostu a závisí od rozdielov medzi prvkami vzorky a priemerná hodnota zvýšená do štvrtého stupňa.
Výpočet opisných štatistík pre všeobecnú populáciu
Priemerná hodnota, rozptyl a distribučný formulár vyššie sú charakteristiky definované vzorkou. Ak však súbor údajov obsahuje číselné merania celej všeobecnej populácie, môžete vypočítať svoje parametre. Takéto parametre zahŕňajú matematické očakávania, disperziu a štandardnú odchýlku všeobecnej populácie.
Očakávaná hodnota rovná súčtu všetkých hodnôt všeobecnej populácie rozdelenej do výšky všeobecnej populácie:

kde µ - očakávaná hodnota, X. I.- i.- pozorovanie premennej X., N. - objem všeobecnej populácie. V programe Excel sa rovnaká funkcia používa na výpočet matematického očakávania, pokiaľ ide o priemerný aritmetický: \u003d CPNPH ().
Disperzia všeobecného agregátu rovná súčtu štvorcov rozdielov medzi prvkami všeobecnej populácie a podložkou. Očakávania vydelené objemom všeobecnej populácie:

kde Σ 2. - Disperzia všeobecnej populácie. V programe Excel, na verziu 2007, funkcia \u003d DYPPR (), počnúc verziou 2010, sa používa na výpočet výčnelku všeobecnej populácie.
Štandardná odchýlka všeobecnej populácie Rovnako, štvorcový koreň extrahovaný z disperzie všeobecného agregátu:

V programe Excel, na verziu 2007, funkcia \u003d STANDOTCLICK () sa používa na výpočet štandardnej odchýlky všeobecnej populácie (), počnúc verzii 2010 \u003d standotclonal.g (). Všimnite si, že vzorce pre rozptýlenie a štandardnú odchýlku všeobecnej populácie sa líšia od vzorec pre výpočet selektívnej disperzie a štandardnej odchýlky. Pri výpočte štatistiky vzorky S 2. a S. Dennominátor Fraci sa rovná n - 1., ale pri výpočte parametrov Σ 2. a σ - objem všeobecnej populácie N..
Empirické pravidlo
Vo väčšine situácií je veľký podiel pozorovania sústredený okolo mediánu, ktorý tvorí klastra. V dátových súpravách, ktoré majú pozitívnu asymetriu, tento klaster sa nachádza vľavo (tj nižšie) matematického očakávania a v množinách, ktoré majú negatívnu asymetriu, tento klaster je správny (t.j. nad) matematického očakávania. V symetrických údajoch sa matematické očakávania a medián zhoduje a pozorovania sú sústredené okolo matematického očakávania, ktoré tvoria zvonovú distribúciu. Ak distribúcia nemá výraznú asymetriu, a údaje sa sústreďujú okolo určitého ťažiska, je možné aplikovať empirické pravidlo na posúdenie variability, ktorú majú údaje o zvončeku, potom približne 68% pozorovania Bude mimo matematického očakávania, že nie viac ako jedna štandardná odchýlka, približne 95% pozorovaní bude podliehať matematickému očakávaniu najviac dvoch štandardných odchýlok a 99,7% z pozorovania je hodných matematické očakávania najviac troch štandardných odchýlok.
Štandardná odchýlka, ktorá je odhadom priemerného oscilácie okolo matematického očakávania, pomáha pochopiť, ako sú pripomienky distribuované a identifikovať emisie. Z empirického pravidla vyplýva, že pre distribúcie v tvare zvonov, len jedna hodnota dvadsiatich sa líši od matematického očakávania je väčšia ako dve štandardné odchýlky. V dôsledku toho hodnoty ležiace mimo intervalu μ ± 2σ.môžu byť považované za emisie. Okrem toho len tri z 1000 pozorovania sa líšia od matematického očakávania viac ako troch štandardných odchýlok. Tak, hodnoty ležiace mimo intervalu μ ± 3σ. Takmer vždy emisie. Pre distribúcie, ktoré majú silnú asymetriu alebo mať zvonovú formu, môže sa použiť empirické pravidlo biedame-chebyshev.
Viac ako pred sto rokmi, matematika Biename a Chebyshev nezávisle od seba otvorili užitočnú vlastnosť štandardnej odchýlky. Zistili, že pre akýkoľvek súbor údajov bez ohľadu na distribučný formulár, percento pozorovania ležiacich na diaľku nepresahujúcu k. štandardné odchýlky od matematického očakávania, nie menej (1 – 1/ k 2) * 100%.
Napríklad, ak k. \u003d 2, pravidlo Bianame-Chebyshev uvádza, že v intervale by malo ležať aspoň 1 - (1/2) 2) x 100% \u003d 75% pozorovaní μ ± 2σ.. Toto pravidlo je spravodlivé pre akékoľvek k.Prekročenie jedného. Pravidlo Biename-Chebyshev je veľmi časté a je spravodlivé pre všetky druhy. Označuje minimálny počet pozorovaní, vzdialenosť, z ktorej nepresahuje špecifikovanú hodnotu pred matematické očakávania. Ak však distribúcia má formulár tvarovanú formu, empirické pravidlo presnejšie odhaduje koncentráciu údajov okolo matematického očakávania.
Výpočet opisných štatistík pre frekvenčnú distribúciu
Ak nie sú k dispozícii zdrojové údaje, distribúcia frekvencie sa stáva jediným zdrojom informácií. V takýchto situáciách je možné vypočítať približné hodnoty kvantitatívnych distribučných ukazovateľov, ako je aritmetická, štandardná odchýlka, kvartil.
Ak sú vzorové údaje prezentované vo forme frekvenčnej distribúcie, môže sa vypočítať približná hodnota priemerného aritmetika, za predpokladu, že všetky hodnoty v každej triede sú sústredené v strednom bode triedy:

kde - selektívny priemer n. - počet pozorovaní alebo odber vzoriek, \\ t z - počet tried vo frekvenčnej distribúcii, \\ t m. J. - Priemerný bod j.-Krácna trieda, f. J. - Frekvencia zodpovedajúca j.- Trieda.
Na výpočet štandardnej odchýlky podľa frekvenčnej distribúcie sa predpokladá, že všetky hodnoty v každej triede sú sústredené v strednom mieste triedy.

Ak chcete pochopiť, ako sa určia kvarty viacerých frekvencií, zvážte výpočet dolných štvrťrokov na základe údajov za rok 2013 o distribúcii obyvateľstva Ruska najväčšieho peňažného príjmu na obyvateľa (Obr. 12).

Obr. 12. Podiel obyvateľov Ruska s priemerom hotovosti na obyvateľa za mesiac, rubľov
Ak chcete vypočítať prvý quarte čísla intervalu, môžete použiť vzorca:

tam, kde Q1 je veľkosť prvého kvartilu, XQ1 je dolná hranica intervalu obsahujúceho prvý kvartil (interval je určený nahromadenou frekvenciou, najprv viac ako 25%); I - veľkosť intervalu; Σf - súčet frekvencií celej vzorky; Pravdepodobne vždy rovné 100%; SQ1-1 - Akumulovaná frekvencia intervalu predchádzajúceho intervalu obsahujúceho dolný kvartil; FQ1 - frekvencia intervalu obsahujúceho dolný kvartil. Vzorec pre tretí byt sa vyznačuje skutočnosťou, že na všetkých miestach namiesto Q1 musíte použiť Q3, a namiesto ¼ náhradu ¾.
V našom príklade (obr. 12), dolný kvartil je v rozsahu 7000.1 - 10 000, ktorého akumulovaná frekvencia je 26,4%. Dolná hranica tohto intervalu je 7000 rubľov, veľkosť intervalu je 3000 rubľov, akumulovaná frekvencia intervalu predchádzajúceho intervalu obsahujúceho dolný kvartil - 13,4%, frekvencia intervalu obsahujúceho dolný kvartil je 13,0%. Teda: Q1 \u003d 7000 + 3000 * (¼ * 100 - 13,4) / 13 \u003d 9677 rubľov.
Pasce spojené s opisnou štatistikou
V tomto článku sme sa pozreli na to, ako opísať súbor údajov pomocou rôznych štatistík, ktoré hodnotia jeho priemernú hodnotu, šírenie a typ distribúcie. Ďalším krokom je analýza a interpretácia údajov. Zatiaľ sme študovali objektívne vlastnosti údajov a teraz sa obrátime na ich subjektívny výklad. Výskumníci stúpajú dve chyby: nesprávne vybraný predmet analýzy a nesprávny výklad výsledkov.
Analýza výnosu 15 podielových fondov s veľmi vysokou úrovňou rizika je dosť nestranná. To viedlo k úplne objektívnym záverom: Všetky podielové fondy majú rôzne výnosy, rozptyl finančných prostriedkov sa líši od -6,1 do 18,5 a priemerný výnos sa rovná 6,08. Objektivita analýzy údajov je zabezpečená správnou voľbou celkových kvantitatívnych distribučných ukazovateľov. Uvažuje sa o niekoľko spôsobov posudzovania priemernej hodnoty a variácie údajov, sú uvedené ich výhody a nevýhody. Ako si vybrať správne štatistiky poskytujúce objektívnu a nestrannú analýzu? Ak má distribúcia dát malú asymetriu, mali by si vybrať medián, nie aritmetický priemer? Aký ukazovateľ presnejšie charakterizuje šírenie údajov: štandardná odchýlka alebo rozsah? Mám špecifikovať pozitívnu asymetriu distribúcie?
Na druhej strane je interpretácia údajov subjektívnym procesom. Rôzni ľudia prichádzajú do rôznych záverov, interpretujú rovnaké výsledky. Každý má svoj vlastný názor. Niekto sa domnieva, že celkové ukazovatele priemernej ročnej ziskovosti 15 fondov s veľmi vysokou úrovňou rizika sú dobré a úplne spokojní s prijatým príjmom. Zdá sa, že tieto fondy majú príliš nízky výnos. Podstativosť by teda mala byť kompenzovaná čestnosťou, neutralitou a jasnosťou záverov.
Etické problémy
Analýza dát je neoddeliteľne spojená s etickými otázkami. Mal by byť kriticky odkazovať na informácie distribuované novinami, rozhlasu, televíziou a internetom. Postupom času sa naučíte skepticky odkazovať nielen na výsledky, ale aj na ciele, predmet a objektivitu výskumu. Slávny britský politik Benjamin Dizraeli povedal najlepšie o tom: "Tam sú tri druhy lží: lož, trasing lži a štatistiky."
Ako je uvedené v poznámke, etické problémy sa vyskytujú, keď by mali byť vybrané výsledky, ktoré by mali byť uvedené v správe. Malo by sa uverejniť pozitívne aj negatívne výsledky. Okrem toho, vykonanie správy alebo písomnej správy, výsledky musia byť úprimne uvedené, neutrálne a objektívne. Mali by sa rozlíšiť neúspešná a nečestná prezentácia. Na to je potrebné určiť, aké boli zámery spravodajcu. Niekedy chýba dôležitá informácia spravodajcu podľa nevedomosti, a niekedy úmyselne (napríklad, ak uplatňuje aritmetický priemer, aby sa odhadli priemerná hodnota explicitne asymetrických údajov, aby sa dosiahol požadovaný výsledok). Je tiež nečestní na umlčanie výsledkov, ktoré nezodpovedajú pohľadu výskumníka.
Materiály knihy Levin et al. Štatistiky pre manažérov. - M.: Williams, 2004. - S. 178-209
Plochá funkcia zosúladila s predchádzajúcimi verziami programu Excel

