Tema #11
V praksi za nastavitev naključnih spremenljivk splošni pogled običajno se uporablja distribucijska funkcija.
Verjetnost, da naključna vrednost X bo sprejel določeno vrednost x 0, izraženo s porazdelitveno funkcijo po formuli
R (X = x 0) \u003d F (x 0 +0) - F (x 0).(3)
Zlasti, če je v točki x = x 0 funkcija F(x) zvezna, potem
R (X = x 0) \u003d 0.
Naključna vrednost X z distribucijo p(A) se imenuje diskretna, če obstaja končna ali štetna množica W na realni premici, tako da R(W,) = 1.
Naj bo W = ( x 1, x 2,…) in pi= str({x i}) = str(x = x i), jaz= 1,2,... Potem za katero koli Borelovo množico A verjetnost p(A) je enolično določen s formulo
Vstavljanje te formule A = (x i / x i< x}, x Î R , dobimo formulo za porazdelitveno funkcijo F(x) diskretna naključna spremenljivka X:
F(x) = str(x < x) =. (5)
Funkcijski graf F(x) je stopničasta linija. Funkcijske konjske dirke F(x) na točkah x \u003d x 1, x 2 ... (x 1
Primer 1. Poiščite distribucijsko funkcijo
diskretna naključna spremenljivka x iz primera 1 § 13.
S pomočjo distribucijske funkcije izračunaj
verjetnosti dogodkov: x< 3, 1 £ x < 4, 1 £ x £ 3.

|
|
pridobljeno v § 13 in formuli (5), dobimo
porazdelitvena funkcija:

Po formuli (1) P(x< 3) = F(3) = 0,1808; по формуле (2)
p(1 £ x< 4) = F (4) – F(1) = 0,5904 – 0,0016 = 0,5888;
p (1 £ x 3 £) = p (1 £ x<3) + p(x = 3) = F(3) – F(1) + F(3+0) – F(3) =
F(3+0) - F(1) = 0,5904 - 0,0016 = 0,5888.
Primer 2. Dana funkcija

Ali je funkcija F(x) porazdelitvena funkcija neke naključne spremenljivke? Če da, poiščite ![]() . Narišite funkcijo F(x).
. Narišite funkcijo F(x).
rešitev. Da bi bila vnaprej določena funkcija F(x) porazdelitvena funkcija neke naključne spremenljivke x, je nujno in zadostno, da so izpolnjeni naslednji pogoji (značilne lastnosti porazdelitvene funkcije):
1.  F(x) je nepadajoča funkcija.
F(x) je nepadajoča funkcija.
3. Za vsak x О R F( x– 0) = F( x).
Za dano funkcijo F(x) je izvedba
ti pogoji so jasni. pomeni,
F(x) je porazdelitvena funkcija.
Verjetnost  izračunaj po
izračunaj po
formula (2):
Graf funkcije F( x) je prikazano na sliki 13.
Primer 3. Naj bo F 1 ( x) in F 2 ( x) so porazdelitvene funkcije naključnih spremenljivk X 1 in X 2 oziroma, A 1 in A 2 so nenegativna števila, katerih vsota je 1.
Dokaži, da je F( x) = a 1 F 1 ( x) + a 2 F 2 ( x) je porazdelitvena funkcija neke naključne spremenljivke X.
rešitev. 1) Ker je F 1 ( x) in F 2 ( x) sta nepadajoči funkciji in A 1 ³ 0, A 2 ³ 0 torej a 1 F 1 ( x) In a 2 F 2 ( x) ne padajo, zato je njihova vsota F( x) tudi ne pada.
3) Za vsak x О R F( x - 0) = a 1 F 1 ( x - 0) + a 2 F 2 ( x - 0)= a 1 F 1 ( x) + a 2 F 2 ( x) = F( x).
Primer 4. Dana funkcija

Ali je F(x) porazdelitvena funkcija naključne spremenljivke?
rešitev. Preprosto je videti, da je F(1) = 0,2 > 0,11 = F(1,1). Zato je F( x) ni nepadajoča, kar pomeni, da ni porazdelitvena funkcija naključne spremenljivke. Upoštevajte, da sta drugi dve lastnosti veljavni za to funkcijo.
Kontrolna naloga št. 11
1. Diskretna naključna spremenljivka X
x) in z njim poiščite verjetnosti dogodkov: a) –2 £ X < 1; б) ½X£½ 2. Narišite porazdelitveno funkcijo.
3. Diskretna naključna spremenljivka X podana z distribucijsko tabelo:
| x i | |||||
| pi | 0,05 | 0,2 | 0,3 | 0,35 | 0,1 |
Poiščite porazdelitveno funkcijo F( x) in poiščite verjetnosti naslednjih dogodkov: a) x < 2; б) 1 £ X < 4; в) 1 £ X£4; d) 1< x£4; e) X = 2,5.
4. Poiščite porazdelitveno funkcijo diskretne naključne spremenljivke X, enako številu točk, ki so padle pri enem metu kocke. Poiščite verjetnost, da bo kotaljenje vsaj 5 z uporabo porazdelitvene funkcije.
5. Izvajajo se zaporedni testi zanesljivosti 5 naprav. Vsaka naslednja naprava se testira le, če se je prejšnja izkazala za zanesljivo. Naredite distribucijsko tabelo in poiščite distribucijsko funkcijo naključnega števila testov naprav, če je verjetnost, da bo test uspešno opravljen za vsako napravo 0,9.
6. Podana je porazdelitvena funkcija diskretne naključne spremenljivke X:

a) Poiščite verjetnost dogodka £1 X 3 £.
b) Poiščite porazdelitveno tabelo naključne spremenljivke X.
7. Podana je porazdelitvena funkcija diskretne naključne spremenljivke X:

Naredite distribucijsko tabelo za to naključno spremenljivko.
8. Vržen je kovanec n enkrat. Naredi razdelilno tabelo in poišči porazdelitveno funkcijo za število pojavitev grba. Narišite distribucijsko funkcijo za n = 5.
9. Kovanec se meče, dokler ne izpade grb. Naredi razdelilno tabelo in poišči porazdelitveno funkcijo za število pojavitev števke.
10. Ostrostrelec strelja na tarčo do prvega zadetka. Verjetnost zgrešitve z enim strelom je enaka R. Poiščite porazdelitveno funkcijo za število zgrešenih rezultatov.
1.2.4. Naključne spremenljivke in njihove porazdelitve
Porazdelitve naključnih spremenljivk in porazdelitvene funkcije. Porazdelitev numerične naključne spremenljivke je funkcija, ki enolično določa verjetnost, da naključna spremenljivka zavzame dano vrednost ali pripada nekemu danemu intervalu.
Prvi je, če naključna spremenljivka zavzame končno število vrednosti. Potem je porazdelitev podana s funkcijo P(X = x), podajo vsako možno vrednost X naključna spremenljivka X verjetnost, da X = x.
Drugi je, če naključna spremenljivka zavzame neskončno veliko vrednosti. To je mogoče le, če je verjetnostni prostor, na katerem je definirana naključna spremenljivka, sestavljen iz neskončnega števila elementarnih dogodkov. Nato je porazdelitev podana z množico verjetnosti P(a <
X
P(a <
X
Ta odnos kaže, da tako kot je distribucijo mogoče izračunati iz distribucijske funkcije, tako je, nasprotno, distribucijsko funkcijo mogoče izračunati iz distribucije.
Uporablja se v verjetnosti statistične metode odločanje in drugo uporabne raziskave porazdelitvene funkcije so diskretne ali zvezne ali kombinacije obeh.
Diskretne porazdelitvene funkcije ustrezajo diskretnim naključnim spremenljivkam, ki prevzamejo končno število vrednosti ali vrednosti iz niza, katerega elemente je mogoče preštevilčiti z naravnimi števili (takšni nizi se v matematiki imenujejo števni). Njihov graf je videti kot stopničasta lestev (slika 1).
Primer 1številka X artiklov z napako v paketu zavzame vrednost 0 z verjetnostjo 0,3, vrednost 1 z verjetnostjo 0,4, vrednost 2 z verjetnostjo 0,2 in vrednost 3 z verjetnostjo 0,1. Graf porazdelitvene funkcije naključne spremenljivke X prikazano na sliki 1.
Slika 1. Graf porazdelitvene funkcije števila izdelkov z napako.
Zvezne porazdelitvene funkcije nimajo skokov. Monotono naraščajo, ko se argument povečuje, od 0 za do 1 za . Naključne spremenljivke z zveznimi porazdelitvenimi funkcijami imenujemo zvezne.
Zvezne porazdelitvene funkcije, ki se uporabljajo v verjetnostno-statističnih metodah odločanja, imajo izvedenke. Prva izpeljanka f(x) distribucijske funkcije F(x) se imenuje gostota verjetnosti,
Porazdelitveno funkcijo lahko določimo iz gostote verjetnosti:
![]()
Za katero koli distribucijsko funkcijo
Naštete lastnosti porazdelitvenih funkcij se nenehno uporabljajo v verjetnostno-statističnih metodah odločanja. Zlasti zadnja enakost implicira specifično obliko konstant v formulah za spodaj obravnavane gostote verjetnosti.
Primer 2 Pogosto se uporablja naslednja distribucijska funkcija:
 (1)
(1)
Kje a in b- nekaj številk a . Poiščimo gostoto verjetnosti te porazdelitvene funkcije:

(na točkah x = a in x = b izpeljanka funkcije F(x) ne obstaja).
Naključna spremenljivka s porazdelitveno funkcijo (1) se imenuje "enakomerno porazdeljena na intervalu [ a; b]».
Mešane porazdelitvene funkcije se pojavijo zlasti takrat, ko se opazovanja na neki točki ustavijo. Na primer pri analizi statističnih podatkov, pridobljenih z uporabo načrtov za testiranje zanesljivosti, ki predvidevajo prekinitev testov po določenem času. Ali pri analizi podatkov o tehničnih izdelkih, ki so zahtevali garancijsko popravilo.
Primer 3 Naj bo na primer življenjska doba električne žarnice naključna spremenljivka s porazdelitveno funkcijo F(t), in test se izvaja, dokler žarnica ne odpove, če se to zgodi manj kot 100 ur od začetka testa, ali do trenutka, ko t0= 100 ur. Pustiti G(t)- funkcija porazdelitve časa delovanja žarnice v dobrem stanju v tem preskusu. Potem

funkcija G(t) ima skok na točki t0, saj ustrezna naključna spremenljivka prevzame vrednost t0 z verjetnostjo 1- F(t0)> 0.
Značilnosti naključnih spremenljivk. V verjetnostno-statističnih metodah odločanja se uporabljajo številne značilnosti naključnih spremenljivk, izražene preko porazdelitvenih funkcij in gostote verjetnosti.
Pri opisovanju diferenciacije dohodka, pri iskanju meja zaupanja za parametre porazdelitev naključnih spremenljivk in v mnogih drugih primerih se uporablja koncept "kvantila reda". R«, kjer je 0< str < 1 (обозначается x str). Kvantil naročila R je vrednost naključne spremenljivke, za katero ima vrednost distribucijska funkcija R ali pride do "skoka" z vrednosti manjše od R do višje vrednosti R(slika 2). Lahko se zgodi, da je ta pogoj izpolnjen za vse vrednosti x, ki pripadajo temu intervalu (tj. porazdelitvena funkcija je na tem intervalu konstantna in je enaka R). Potem se vsaka taka vrednost imenuje "kvantil reda". R". Za zvezne porazdelitvene funkcije praviloma obstaja en sam kvantil x str naročilo R(slika 2) in
F(x p) = p. (2)

Slika 2. Opredelitev kvantila x str naročilo R.
Primer 4 Poiščimo kvantil x str naročilo R za distribucijsko funkcijo F(x) od (1).
Pri 0< str < 1 квантиль x str se najde iz enačbe
tiste. x str = a + p(b – a) = a( 1- p)+bp. pri str= 0 katerikoli x < a je kvantil reda str= 0. Kvantil reda str= 1 je poljubno število x > b.
Za diskretne porazdelitve praviloma ni x str ki izpolnjuje enačbo (2). Natančneje, če je porazdelitev slučajne spremenljivke podana v tabeli 1, kjer x 1< x 2 < … < x k , potem enakost (2), obravnavana kot enačba glede na x str, ima rešitve samo za k vrednote str, in sicer
p \u003d p 1,
p \u003d p 1 + p 2,
p \u003d p 1 + p 2 + p 3,
p \u003d p 1 + p 2 + ...+ popoldne, 3 < m < k,
str = str 1 + str 2 + … + p k.
Tabela 1.
Porazdelitev diskretne naključne spremenljivke
Za naštete k vrednosti verjetnosti str rešitev x str enačba (2) ni edinstvena, namreč
F(x) = p 1 + p 2 + ... + p m
za vse X tako da x m< x < xm+1. Tisti. x p - katero koli število iz obsega (x m ; x m+1 ]. Za vse ostale R iz intervala (0;1), ki ni vključen v seznam (3), pride do "skoka" z vrednosti, manjše od R do višje vrednosti R. Če namreč
p 1 + p 2 + … + p m
to x p \u003d x m + 1.
Upoštevana lastnost diskretnih porazdelitev povzroča znatne težave pri tabeliranju in uporabi takšnih porazdelitev, saj je nemogoče natančno vzdrževati tipične numerične vrednosti značilnosti porazdelitve. Še posebej to velja za kritične vrednosti in ravni pomembnosti neparametričnih statističnih testov (glej spodaj), saj so porazdelitve statistike teh testov diskretne.
Kvantil vrstnega reda je v statistiki zelo pomemben. R= ½. Imenuje se mediana (naključna spremenljivka X ali njegovo distribucijsko funkcijo F(x)) in označeno Jaz (X). V geometriji obstaja koncept "mediana" - ravna črta, ki poteka skozi vrh trikotnika in deli njegovo nasprotno stran na polovico. V matematični statistiki mediana ne razpolovi stranice trikotnika, temveč porazdelitev naključne spremenljivke: enakost F(x0,5)= 0,5 pomeni, da je verjetnost, da pridete v levo x0,5 in verjetnost, da bo prav x0,5(ali neposredno na x0,5) so med seboj enaki in enaki ½, tj.
p(X < x 0,5) = p(X > x 0,5) = ½.
Mediana označuje "središče" porazdelitve. Z vidika enega od sodobnih konceptov - teorije stabilnih statističnih postopkov - je mediana boljša značilnost naključne spremenljivke kot pričakovana vrednost. Pri obdelavi merilnih rezultatov v ordinalni lestvici (glej poglavje o teoriji merjenja) lahko uporabimo mediano, matematičnega pričakovanja pa ne.
Takšna značilnost naključne spremenljivke, kot je način, ima jasen pomen - vrednost (ali vrednosti) naključne spremenljivke, ki ustreza lokalnemu maksimumu gostote verjetnosti za zvezno naključno spremenljivko ali lokalnemu maksimumu verjetnosti za diskretno naključno spremenljivka.
če x0 je način naključne spremenljivke z gostoto f(x), potem, kot je znano iz diferencialnega računa, .
Naključna spremenljivka ima lahko veliko načinov. Torej, za enakomerno porazdelitev (1) vsaka točka X tako da a< x < b , je moda. Vendar je to izjema. Večina naključnih spremenljivk, ki se uporabljajo v verjetnostno-statističnih metodah odločanja in drugih uporabnih raziskavah, ima en način. Naključne spremenljivke, gostote, porazdelitve, ki imajo en način, imenujemo unimodalne.
Matematično pričakovanje za diskretne naključne spremenljivke s končnim številom vrednosti je obravnavano v poglavju "Dogodki in verjetnosti". Za zvezno naključno spremenljivko X pričakovana vrednost M(X) zadošča enakosti
![]()
ki je analog formule (5) iz izjave 2 poglavja "Dogodki in verjetnosti".
Primer 5 Matematično pričakovanje za enakomerno porazdeljeno naključno spremenljivko X enako
Za naključne spremenljivke, obravnavane v tem poglavju, veljajo vse tiste lastnosti matematičnih pričakovanj in varianc, ki so bile prej obravnavane za diskretne naključne spremenljivke s končnim številom vrednosti. Vendar pa ne dokazujemo teh lastnosti, saj zahtevajo poglabljanje v matematične tankosti, kar ni potrebno za razumevanje in kvalificirano uporabo verjetnostno-statističnih metod odločanja.
Komentiraj. V tem učbeniku se namenoma izogibamo matematičnim tankostim, ki so povezane zlasti s pojmi merljivih množic in merljivih funkcij, -algebra dogodkov itd. Tisti, ki želijo obvladati te koncepte, naj se obrnejo na specializirano literaturo, zlasti na enciklopedijo.
Vsaka od treh značilnosti – matematično pričakovanje, mediana, način – opisuje »središče« porazdelitve verjetnosti. Koncept "središča" je mogoče definirati na različne načine - od tod tudi tri različne značilnosti. Vendar pa za pomemben razred porazdelitev - simetrične unimodalne - vse tri značilnosti sovpadajo.
Gostota porazdelitve f(x) je gostota simetrične porazdelitve, če obstaja število x 0 tako da
![]() . (3)
. (3)
Enačba (3) pomeni, da je graf funkcije y = f(x) simetrična glede na navpičnico, ki poteka skozi središče simetrije X = X 0 . Iz (3) sledi, da simetrična porazdelitvena funkcija zadosti razmerju
![]() (4)
(4)
Za simetrično porazdelitev z enim načinom so povprečje, mediana in način enaki in enaki x 0.
Najpomembnejši primer je simetrija glede na 0, tj. x 0= 0. Potem (3) in (4) postaneta enačbi
![]() (6)
(6)
oz. Zgornje relacije kažejo, da ni potrebe po preglednici simetričnih porazdelitev za vse X, zadostuje, da imamo mize za x > x0.
Opozorimo še na eno lastnost simetričnih porazdelitev, ki se nenehno uporablja v verjetnostno-statističnih metodah odločanja in drugih aplikativnih raziskavah. Za zvezno distribucijsko funkcijo
P(|X| < a) = P(-a < X < a) = F(a) – F(-a),
Kje F je porazdelitvena funkcija naključne spremenljivke X. Če distribucijska funkcija F je simetrična glede na 0, tj. potem zanjo velja formula (6).
P(|X| < a) = 2F(a) – 1.
Pogosto se uporablja druga formulacija obravnavane izjave: če
![]() .
.
Če sta in kvantila reda oziroma (glej (2)) porazdelitvene funkcije simetrične glede na 0, potem iz (6) sledi, da
Od značilnosti položaja - matematično pričakovanje, mediana, način - pojdimo na značilnosti širjenja naključne spremenljivke X: varianca, standardni odklon in koeficient variacije v. Opredelitev in lastnosti variance za diskretne naključne spremenljivke smo obravnavali v prejšnjem poglavju. Za zvezne naključne spremenljivke
Standardni odklon je nenegativna vrednost kvadratnega korena variance:
Koeficient variacije je razmerje med standardnim odklonom in matematičnim pričakovanjem:
Koeficient variacije se uporabi, ko M(X)> 0. Meri širjenje v relativnih enotah, standardni odklon pa v absolutnih enotah.
Primer 6 Za enakomerno porazdeljeno naključno spremenljivko X poiščite varianco, standardni odklon in koeficient variacije. Disperzija je:

Zamenjava spremenljivke omogoča zapis:
Kje c = (b – a)/ 2. Zato je standardna deviacija enaka in koeficient variacije je:
Za vsako naključno spremenljivko X določi še tri količine – centrirano Y, normalizirano V in dano U. Centrirana naključna spremenljivka Y je razlika med dano naključno spremenljivko X in njegovo matematično pričakovanje M(X), tiste. Y = X - M(X). Matematično pričakovanje centrirane naključne spremenljivke Y je enaka 0, varianca pa je varianca dane naključne spremenljivke: M(Y) = 0, D(Y) = D(X). distribucijska funkcija F Y(x) centrirana naključna spremenljivka Y povezana z distribucijsko funkcijo F(x) začetna naključna spremenljivka X razmerje:
F Y(x) = F(x + M(X)).
Za gostote teh naključnih spremenljivk velja enakost
f Y(x) = f(x + M(X)).
Normalizirana naključna spremenljivka V je razmerje te naključne spremenljivke X njegovemu standardnemu odklonu, tj. . Matematično pričakovanje in varianca normalizirane naključne spremenljivke V izraženo skozi lastnosti X Torej:
![]() ,
,
Kje v je koeficient variacije izvirne naključne spremenljivke X. Za distribucijsko funkcijo F V(x) in gostoto f V(x) normalizirana naključna spremenljivka V imamo:
Kje F(x) je porazdelitvena funkcija izvirne naključne spremenljivke X, A f(x) je njegova gostota verjetnosti.
Zmanjšana naključna spremenljivka U je centrirana in normalizirana naključna spremenljivka:
![]() .
.
Za zmanjšano naključno spremenljivko
Normalizirane, centrirane in reducirane naključne spremenljivke se nenehno uporabljajo tako v teoretičnih raziskavah kot v algoritmih, programskih izdelkih, regulativni in tehnični ter instruktivni in metodološki dokumentaciji. Še posebej zato, ker enakosti ![]() omogočajo poenostavitev utemeljitve metod, formulacij izrekov in formul za izračun.
omogočajo poenostavitev utemeljitve metod, formulacij izrekov in formul za izračun.
Uporabljene so transformacije naključnih spremenljivk in splošnejši načrt. Torej če Y = aX + b, Kje a in b je nekaj številk, torej
Primer 7Če, potem Y je reducirana naključna spremenljivka, formule (8) pa pretvorimo v formule (7).
Z vsako naključno spremenljivko X lahko povežete veliko naključnih spremenljivk Y podana s formulo Y = aX + b pri različnih a> 0 in b. Ta niz se imenuje družina pomika lestvice, ki ga ustvari naključna spremenljivka X. Distribucijske funkcije F Y(x) sestavljajo družino porazdelitev po lestvici, ki jih ustvari distribucijska funkcija F(x). Namesto Y = aX + b pogosto uporabljen zapis
![]()
številka z se imenuje parameter premika in število d- parameter lestvice. Formula (9) to pokaže X- rezultat merjenja določene količine - gre v pri- rezultat meritve enake vrednosti, če se začetek meritve premakne na točko z in nato uporabite novo mersko enoto, in d krat večji od starega.
Za družino lestvice (9) se porazdelitev X imenuje standardna. V verjetnostno-statističnih metodah odločanja in drugih uporabnih raziskavah se uporabljajo standardna normalna porazdelitev, standardna Weibull-Gnedenkova porazdelitev, standardna gama porazdelitev itd. (glej spodaj).
Uporabljajo se tudi druge transformacije naključnih spremenljivk. Na primer za pozitivno naključno spremenljivko X upoštevati Y= dnevnik X, kjer je lg X je decimalni logaritem števila X. Veriga enakosti
F Y (x) = P( lg X< x) = P(X < 10x) = F( 10x)
povezuje distribucijske funkcije X in Y.
Pri obdelavi podatkov se uporabljajo takšne značilnosti naključne spremenljivke X kot trenutki reda q, tj. matematična pričakovanja naključne spremenljivke X q, q= 1, 2, … Tako je samo matematično pričakovanje trenutek reda 1. Za diskretno naključno spremenljivko je trenutek reda q se lahko izračuna kot
![]()
Za zvezno naključno spremenljivko
![]()
Trenutki reda q imenovani tudi začetni trenutki reda q, v nasprotju s sorodnimi značilnostmi - osrednjimi momenti reda q, podana s formulo
Tako je disperzija osrednji moment reda 2.
Normalna porazdelitev in centralni limitni izrek. Pri verjetnostno-statističnih metodah odločanja pogosto govorimo o normalni porazdelitvi. Včasih ga poskušajo uporabiti za modeliranje porazdelitve začetnih podatkov (ti poskusi niso vedno upravičeni - glej spodaj). Še pomembneje pa je, da številne metode obdelave podatkov temeljijo na dejstvu, da imajo izračunane vrednosti porazdelitve, ki so blizu normalnim.
Pustiti X 1 , X 2 ,…, X n M(X i) = m in disperzije D(X i) = , jaz = 1, 2,…, n,… Kot izhaja iz rezultatov prejšnjega poglavja,
Upoštevajte zmanjšano naključno spremenljivko U n za znesek ![]() , in sicer
, in sicer
![]()
Kot sledi iz formul (7), M(U n) = 0, D(U n) = 1.
(za enako porazdeljene izraze). Pustiti X 1 , X 2 ,…, X n, … so neodvisne enako porazdeljene naključne spremenljivke z matematičnimi pričakovanji M(X i) = m in disperzije D(X i) = , jaz = 1, 2,…, n,… Potem za vsak x obstaja meja
![]()
Kje F(x) je standardna funkcija normalne porazdelitve.
Več o funkciji F(x) - spodaj (se glasi "fi iz x", ker F- velika grška črka "phi").
Centralni mejni izrek (CLT) je dobil ime po dejstvu, da je osrednji, najpogosteje uporabljen matematični rezultat teorije verjetnosti in matematične statistike. Zgodovina CLT traja približno 200 let - od leta 1730, ko je angleški matematik A. De Moivre (1667-1754) objavil prvi rezultat, povezan s CLT (glej spodaj o Moivre-Laplaceovem izreku), do dvajsetih in tridesetih let prejšnjega stoletja. dvajsetega stoletja, ko je Finn J.W. Lindeberg, Francoz Paul Levy (1886-1971), Jugoslovan V. Feller (1906-1970), Rus A.Ya. Khinchin (1894-1959) in drugi znanstveniki so dobili potrebne in zadostne pogoje za veljavnost klasičnega centralnega mejnega izreka.
Razvoj obravnavane teme se tu sploh ni ustavil - preučevali so naključne spremenljivke, ki nimajo disperzije, tj. tiste, za katere
![]()
(akademik B.V. Gnedenko in drugi), situacija, ko se seštejejo naključne spremenljivke (natančneje, naključni elementi) bolj kompleksne narave kot števila (akademiki Yu.V. Prohorov, A.A. Borovkov in njihovi sodelavci) itd. .d.
distribucijska funkcija F(x) je podana z enakostjo
![]() ,
,
kjer je gostota standardne normalne porazdelitve, ki ima precej zapleten izraz:
![]() .
.
Tukaj \u003d 3,1415925 ... je število, znano v geometriji, enako razmerju med obodom in premerom, e \u003d 2,718281828 ... - osnova naravnih logaritmov (če si želite zapomniti to številko, upoštevajte, da je 1828 leto rojstva pisatelja Leva Tolstoja). Kot je znano iz matematične analize,
![]()
Pri obdelavi rezultatov opazovanj se funkcija normalne porazdelitve ne izračuna po zgornjih formulah, ampak se najde s pomočjo posebnih tabel ali računalniških programov. Najboljše v ruščini »Tabele matematične statistike« so sestavili dopisni člani Akademije znanosti ZSSR L.N. Bolshev in N.V. Smirnov.
Oblika gostote standardne normalne porazdelitve izhaja iz matematične teorije, ki je tukaj ne moremo upoštevati, kot tudi dokaz CLT.
Za ilustracijo predstavljamo majhne tabele porazdelitvene funkcije F(x)(tabela 2) in njegove kvantile (tabela 3). funkcija F(x) je simetričen glede na 0, kar se odraža v tabelah 2-3.
Tabela 2.
Funkcija standardne normalne porazdelitve.
Če je naključna spremenljivka X ima distribucijsko funkcijo F(x), to M(X) = 0, D(X) = 1. Ta trditev je dokazana v teoriji verjetnosti na podlagi oblike gostote verjetnosti . Strinja se s podobno izjavo za značilnosti zmanjšane naključne spremenljivke U n, kar je povsem naravno, saj CLT pravi, da z neskončnim povečanjem števila členov porazdelitvena funkcija U n teži k standardni funkciji normalne porazdelitve F(x), in za katerokoli X.
Tabela 3
Kvantili standardne normalne porazdelitve.
Kvantil naročila R |
Kvantil naročila R |
||
Uvedimo koncept družine normalnih porazdelitev. Po definiciji je normalna porazdelitev porazdelitev naključne spremenljivke X, za katero je porazdelitev reducirane naključne spremenljivke F(x). Kot izhaja iz splošnih lastnosti družin porazdelitev s premikom po lestvici (glej zgoraj), je normalna porazdelitev porazdelitev naključne spremenljivke
Kje X je naključna spremenljivka s porazdelitvijo F(X), in m = M(Y), = D(Y). Normalna porazdelitev s parametri premika m in merilo je običajno označeno n(m, ) (včasih zapis n(m, ) ).
Kot sledi iz (8), gostota verjetnosti normalne porazdelitve n(m, ) Tukaj je

Normalne porazdelitve tvorijo družino zamika na lestvici. V tem primeru je parameter lestvice d= 1/ in parameter premika c = - m/ .
Za središčne momente tretjega in četrtega reda normalne porazdelitve veljajo enakosti
![]()
Te enakosti so podlaga za klasične metode preverjanja, ali rezultati opazovanj sledijo normalni porazdelitvi. Trenutno se običajno priporoča preverjanje normalnosti s kriterijem W Shapiro - Wilka. Problem preverjanja normalnosti je obravnavan spodaj.
Če naključne spremenljivke X 1 in X 2 imajo distribucijske funkcije n(m 1
, 1)
in n(m 2
, 2)
oziroma torej X 1+ X 2 ima distribucijo ![]() Torej, če naključne spremenljivke X 1
,
X 2
,…,
X n n(m, )
, potem njihova aritmetična sredina
Torej, če naključne spremenljivke X 1
,
X 2
,…,
X n n(m, )
, potem njihova aritmetična sredina
![]()
ima distribucijo n(m, ) . Te lastnosti normalne porazdelitve se nenehno uporabljajo v različnih verjetnostno-statističnih metodah odločanja, predvsem pri statističnem nadzoru tehnoloških procesov in pri statističnem nadzoru sprejemljivosti s kvantitativnim atributom.
Normalna porazdelitev definira tri porazdelitve, ki se danes običajno uporabljajo pri statistični obdelavi podatkov.
Porazdelitev (hi - kvadrat) - porazdelitev naključne spremenljivke
kjer so naključne spremenljivke X 1 , X 2 ,…, X n so neodvisni in imajo enako porazdelitev n(0,1). V tem primeru je število terminov, tj. n, se imenuje "število prostostnih stopinj" porazdelitve hi-kvadrat.
Distribucija t Student je porazdelitev naključne spremenljivke
kjer so naključne spremenljivke U in X neodvisen, U ima standardno normalno porazdelitev n(0,1) in X– porazdelitev chi – kvadrat s n stopnje svobode. pri čemer n se imenuje "število prostostnih stopinj" Studentove porazdelitve. To porazdelitev je leta 1908 uvedel angleški statistik W. Gosset, ki je delal v tovarni piva. V tej tovarni so za sprejemanje ekonomskih in tehničnih odločitev uporabljali verjetnostno-statistične metode, zato je njeno vodstvo V. Gossetu prepovedalo objavljanje znanstvenih člankov pod svojim imenom. Na ta način je bila zaščitena poslovna skrivnost, »know-how« v obliki verjetnostno-statističnih metod, ki jih je razvil W. Gosset. Lahko pa je objavljal pod psevdonimom Študent. Zgodovina podjetja Gosset - Student kaže, da je bila britanskim menedžerjem še sto let očitna velika ekonomska učinkovitost verjetnostno-statističnih metod odločanja.
Fisherjeva porazdelitev je porazdelitev naključne spremenljivke
kjer so naključne spremenljivke X 1 in X 2 so neodvisne in imajo chi porazdelitve – kvadrat s številom prostostnih stopenj k 1 in k 2 oz. Hkrati pa par (k 1 , k 2 ) je par "števil prostostnih stopenj" Fisherjeve porazdelitve, in sicer k 1 je število prostostnih stopenj števca in k 2 je število prostostnih stopenj imenovalca. Porazdelitev naključne spremenljivke F je dobila ime po velikem angleškem statistiku R. Fisherju (1890-1962), ki jo je aktivno uporabljal pri svojem delu.
Izraze za porazdelitvene funkcije hi-kvadrata, Studenta in Fisherja, njihove gostote in značilnosti ter tabele najdete v posebni literaturi (glej na primer).
Kot smo že omenili, se normalne porazdelitve trenutno pogosto uporabljajo v verjetnostnih modelih na različnih uporabnih področjih. Zakaj je ta družina distribucij z dvema parametroma tako razširjena? To pojasnjuje naslednji izrek.
Centralni mejni izrek(za različno porazdeljene izraze). Pustiti X 1 , X 2 ,…, X n,… so neodvisne naključne spremenljivke z matematičnimi pričakovanji M(X 1 ), M(X 2 ),…, M(X n), … in disperzije D(X 1 ), D(X 2 ),…, D(X n), … oz. Pustiti
Nato pod veljavnostjo določenih pogojev, ki zagotavljajo majhnost prispevka katerega koli od pogojev k U n,
![]()
za kogarkoli X.
Zadevni pogoji tukaj ne bodo oblikovani. Najdete jih v specializirani literaturi (glej na primer). "Razjasnitev pogojev, pod katerimi deluje CPT, je zasluga izjemnih ruskih znanstvenikov A. A. Markova (1857-1922) in zlasti A. M. Ljapunova (1857-1918)" .
Osrednji mejni izrek kaže, da v primeru, ko je rezultat meritve (opazovanje) oblikovan pod vplivom številnih razlogov, vsak od njih prispeva le majhen prispevek, kumulativni rezultat pa je določen z aditivno, tj. z dodatkom, potem je porazdelitev rezultata meritve (opazovanja) blizu normalne.
Včasih se verjame, da je za normalno porazdelitev dovolj, da rezultat meritve (opazovanja) X nastal pod vplivom številnih vzrokov, od katerih ima vsak majhen učinek. To je narobe. Pomembno je, kako ti vzroki delujejo. Če je dodatek, potem X ima približno normalno porazdelitev. če multiplikativno(to pomeni, da se dejanja posameznih vzrokov množijo, ne seštevajo), nato porazdelitev X ne blizu normalnega, ampak t.i. logaritemsko normalno, tj. ne X, in lg X ima približno normalno porazdelitev. Če ni razlogov za domnevo, da deluje eden od teh dveh mehanizmov za oblikovanje končnega rezultata (ali kakšen drug natančno definiran mehanizem), potem o distribuciji X nič določnega se ne da reči.
Iz povedanega izhaja, da v konkretnem aplikativnem problemu normalnosti rezultatov meritev (opazovanja) praviloma ni mogoče ugotoviti iz splošnih premislekov, temveč jo je treba preveriti s statističnimi merili. Ali pa uporabite neparametrične statistične metode, ki ne temeljijo na predpostavkah o porazdelitvenih funkcijah rezultatov meritev (opazovanj), ki pripadajo eni ali drugi parametrični družini.
Zvezne porazdelitve, ki se uporabljajo v verjetnostno-statističnih metodah odločanja. Poleg družine normalnih porazdelitev s premikom po lestvici se široko uporabljajo številne druge družine porazdelitev - logaritemsko normalne, eksponentne, Weibull-Gnedenkove porazdelitve, gama porazdelitve. Oglejmo si te družine.
Naključna vrednost X ima log-normalno porazdelitev, če je naključna spremenljivka Y= dnevnik X ima normalno porazdelitev. Potem Z=ln X = 2,3026…Y ima tudi normalno porazdelitev n(a 1 ,σ 1), kjer ln X- naravni logaritem X. Gostota log-normalne porazdelitve je:

Iz osrednjega limitnega izreka sledi, da produkt X = X 1 X 2 … X n neodvisne pozitivne naključne spremenljivke X i, jaz = 1, 2,…, n, na prostosti n se lahko približa z logaritmično normalno porazdelitvijo. Predvsem multiplikativni model oblikovanja plač oziroma dohodkov vodi do priporočila, da se porazdelitve plač in dohodkov približajo z logaritemsko normalnimi zakoni. Za Rusijo se je to priporočilo izkazalo za upravičeno - statistika to potrjuje.
Obstajajo še drugi verjetnostni modeli, ki vodijo do log-normalnega zakona. Klasičen primer takega modela je A.N. kroglični mlini imajo logaritemsko normalno porazdelitev.
Pojdimo k drugi družini porazdelitev, ki se pogosto uporablja v različnih verjetnostno-statističnih metodah odločanja in drugih uporabnih raziskavah, družini eksponentnih porazdelitev. Začnimo z verjetnostnim modelom, ki vodi do takih porazdelitev. Če želite to narediti, upoštevajte "tok dogodkov", tj. zaporedje dogodkov, ki se zgodijo eden za drugim v nekem trenutku. Primeri so: pretok klicev na telefonski centrali; tok okvar opreme v tehnološki verigi; potek napak izdelka med preskušanjem izdelka; pretok zahtev strank do bančne poslovalnice; tok kupcev, ki zaprosijo za blago in storitve itd. V teoriji tokov dogodkov velja izrek, podoben centralnemu mejnemu izreku, ki pa ne obravnava seštevanja slučajnih spremenljivk, temveč seštevanje tokov dogodkov. Obravnavamo skupni tok, sestavljen iz velikega števila neodvisnih tokov, od katerih nobeden nima prevladujočega vpliva na skupni pretok. Na primer, tok klicev, ki prihajajo na telefonsko centralo, je sestavljen iz velikega števila neodvisnih tokov klicev, ki izvirajo od posameznih naročnikov. Dokazano je, da v primeru, ko karakteristike tokov niso odvisne od časa, celoten tok v celoti opisuje ena številka - intenziteta toka. Za skupni tok upoštevajte naključno spremenljivko X- dolžina časovnega intervala med zaporednimi dogodki. Njegova distribucijska funkcija ima obliko
 (10)
(10)
Ta porazdelitev se imenuje eksponentna porazdelitev, ker formula (10) vključuje eksponentno funkcijo e -λ x. Vrednost 1/λ je parameter lestvice. Včasih je uveden tudi parameter prestavljanja z, eksponentna je porazdelitev naključne spremenljivke X + c, kjer je distribucija X je podana s formulo (10).
Eksponentne porazdelitve so poseben primer t.i. Weibullova - Gnedenkova porazdelitev. Imenujejo se po inženirju W. Weibullu, ki je te porazdelitve uvedel v prakso analize rezultatov testov utrujenosti, in matematiku B. V. Gnedenku (1912-1995), ki je takšne porazdelitve prejel kot mejne pri preučevanju maksimuma testa rezultate. Pustiti X- naključna spremenljivka, ki označuje trajanje delovanja izdelka, kompleksnega sistema, elementa (tj. vir, čas delovanja do mejnega stanja itd.), trajanje delovanja podjetja ali življenja živega bitja, itd. Stopnja napak igra pomembno vlogo
![]() (11)
(11)
Kje F(x) in f(x) - porazdelitvena funkcija in gostota naključne spremenljivke X.
Opišimo tipično obnašanje stopnje napak. Celoten časovni interval lahko razdelimo na tri obdobja. Na prvem izmed njih je funkcija λ(x) ima visoke vrednosti in jasno tendenco zmanjšanja (najpogosteje se monotono zmanjšuje). To je mogoče razložiti s prisotnostjo proizvodnih enot v obravnavani seriji z očitnimi in skritimi napakami, kar vodi do razmeroma hitre okvare teh proizvodnih enot. Prvo obdobje se imenuje "vlomno" (ali "vlomno") obdobje. To je običajno pokrito z garancijskim obdobjem.
Nato nastopi obdobje normalnega delovanja, za katerega je značilna približno konstantna in relativno nizka stopnja napak. Narava okvar v tem obdobju je nenadna (nesreče, napake obratovalnega osebja itd.) In ni odvisna od trajanja delovanja proizvodne enote.
Končno je zadnje obdobje delovanja obdobje staranja in obrabe. Narava okvar v tem obdobju je v ireverzibilnih fizikalnih, mehanskih in kemičnih spremembah materialov, ki vodijo do progresivnega poslabšanja kakovosti proizvodne enote in njene končne okvare.
Vsako obdobje ima svojo vrsto funkcije λ(x). Razmislite o razredu odvisnosti moči
λ(х) = λ0bxb -1 , (12)
Kje λ 0 > 0 in b> 0 - nekateri številski parametri. Vrednote b < 1, b= 0 in b> 1 ustreza vrsti stopnje napak v obdobjih utekanja, normalnega delovanja in staranja.
Relacija (11) za dano stopnjo napak λ(x)- diferencialna enačba glede na funkcijo F(x). Iz teorije diferencialne enačbe temu sledi
 (13)
(13)
Če nadomestimo (12) v (13), dobimo to
 (14)
(14)
Porazdelitev, podana s formulo (14), se imenuje Weibullova - Gnedenkova porazdelitev. Zaradi
potem iz formule (14) sledi, da je količina A, podana s formulo (15), je skalirni parameter. Včasih je uveden tudi parameter premika, tj. Weibull-Gnedenkove porazdelitvene funkcije se imenujejo F(x - c), Kje F(x) je podana s formulo (14) za nekaj λ 0 in b.
Gostota Weibull-Gnedenkove porazdelitve ima obliko
 (16)
(16)
Kje a> 0 - parameter lestvice, b> 0 - parameter obrazca, z- parameter premika. V tem primeru parameter A iz formule (16) je povezan s parametrom λ 0 iz formule (14) z razmerjem, navedenim v formuli (15).
Eksponentna porazdelitev je zelo poseben primer Weibull-Gnedenkove porazdelitve, ki ustreza vrednosti parametra oblike b = 1.
Weibullova - Gnedenkova porazdelitev se uporablja tudi pri izdelavi verjetnostnih modelov situacij, v katerih obnašanje objekta določa "najšibkejši člen". Navedena je analogija z verigo, katere varnost je določena s členom, ki ima najmanjšo moč. Z drugimi besedami, naj X 1 , X 2 ,…, X n so neodvisne enako porazdeljene naključne spremenljivke,
X (1)=min( X 1, X 2,…, X n), X(n)=max( X 1, X 2,…, X n).
Pri številnih uporabnih problemih igra pomembno vlogo X(1) in X(n) , zlasti pri preučevanju največjih možnih vrednosti ("zapisov") določenih vrednosti, na primer zavarovalnih plačil ali izgub zaradi komercialnih tveganj, pri preučevanju meja elastičnosti in vzdržljivosti jekla, številnih značilnosti zanesljivosti, itd. Dokazano je, da za velike n porazdelitve X(1) in X(n) , praviloma dobro opisujejo Weibull-Gnedenkove porazdelitve. Temeljni prispevki k študiju porazdelitev X(1) in X(n) uvedel sovjetski matematik B. V. Gnedenko. Dela V. Weibulla, E. Gumbela, V.B. Nevzorova, E.M. Kudlaev in mnogi drugi strokovnjaki.
Pojdimo k družini gama porazdelitev. Široko se uporabljajo v ekonomiji in managementu, teoriji in praksi zanesljivosti in testiranja, na različnih področjih tehnologije, meteorologije itd. Zlasti v mnogih primerih je porazdelitev gama odvisna od takšnih količin, kot so skupna življenjska doba izdelka, dolžina verige prevodnih prašnih delcev, čas, ki ga potrebuje izdelek, da doseže mejno stanje med korozijo, delovanje čas do k zavrnitev, k= 1, 2, … itd. Pričakovana življenjska doba bolnikov kronične bolezni, čas za doseganje določenega učinka pri zdravljenju ima v nekaterih primerih gama porazdelitev. Ta porazdelitev je najprimernejša za opis povpraševanja v ekonomsko-matematičnih modelih upravljanja zalog (logistike).
Gostota porazdelitve gama ima obliko
 (17)
(17)
Gostoto verjetnosti v formuli (17) določajo trije parametri a, b, c, Kje a>0, b>0. pri čemer a je parameter obrazca, b- parameter lestvice in z- parameter premika. Faktor 1/Γ(a) je normalizacija, uvedena je zato, da bi
![]()
Tukaj Γ(a)- tisti, ki se uporablja v matematiki posebne funkcije, tako imenovana "funkcija gama", po kateri se imenuje tudi porazdelitev, podana s formulo (17),

Pri fiksnem A formula (17) definira družino porazdelitev po lestvici, ki jih ustvari porazdelitev z gostoto
 (18)
(18)
Porazdelitev oblike (18) imenujemo standardna gama porazdelitev. Dobi se iz formule (17) z b= 1 in z= 0.
Poseben primer gama porazdelitev pri A= 1 so eksponentne porazdelitve (z λ = 1/b). Z naravnimi A in z=0 gama porazdelitve imenujemo Erlangove porazdelitve. Iz del danskega znanstvenika K. A. Erlanga (1878-1929), uslužbenca kopenhagenskega telefonskega podjetja, ki je študiral v letih 1908-1922. delovanja telefonskih omrežij se je začel razvoj teorije čakalne vrste. Ta teorija se ukvarja z verjetnostno-statističnim modeliranjem sistemov, v katerih se tok zahtev servisira z namenom sprejemanja optimalnih odločitev. Erlangove porazdelitve se uporabljajo na istih področjih uporabe kot eksponentne porazdelitve. To temelji na naslednjem matematičnem dejstvu: vsota k neodvisnih naključnih spremenljivk, eksponentno porazdeljenih z istimi parametri λ in z, ima gama porazdelitev s parametrom oblike a =k, parameter lestvice b= 1/λ in parameter premika kc. pri z= 0 dobimo Erlangovo porazdelitev.
Če je naključna spremenljivka X ima gama porazdelitev s parametrom oblike A tako da d = 2 a- celo število, b= 1 in z= 0, nato 2 X ima hi-kvadrat porazdelitev z d stopnje svobode.
Naključna vrednost X z gvmma-distribucijo ima naslednje značilnosti:
Pričakovana vrednost M(X) =ab + c,
disperzija D(X) = σ 2 = ab 2 ,
Koeficient variacije
asimetrija ![]()
Presežek ![]()
Normalna porazdelitev je skrajni primer gama porazdelitve. Natančneje, naj bo Z naključna spremenljivka s standardno porazdelitvijo gama, podano s formulo (18). Potem
![]()
za poljubno realno število X, Kje F(x)- standardna funkcija normalne porazdelitve n(0,1).
V aplikativnih raziskavah se uporabljajo tudi druge parametrične družine porazdelitev, med katerimi so najbolj znane Pearsonov sistem krivulj, Edgeworthova in Charlierjeva serija. Tu se ne upoštevajo.
Diskretno porazdelitve, ki se uporabljajo v verjetnostno-statističnih metodah odločanja. Najpogosteje se uporabljajo tri družine diskretnih porazdelitev - binomska, hipergeometrična in Poissonova ter nekatere druge družine - geometrijska, negativna binomska, multinomska, negativna hipergeometrična itd.
Kot že omenjeno, binomska porazdelitev poteka v neodvisnih poskusih, v vsakem od njih z verjetnostjo R pojavi dogodek A. če skupno število testi n podano, nato pa število poskusov Y, v katerem se je dogodek pojavil A, ima binomsko porazdelitev. Za binomsko porazdelitev je verjetnost, da bo sprejeta kot naključna spremenljivka Y vrednote l se določi s formulo
![]()
Število kombinacij od n elementi po l znano iz kombinatorike. Za vse l, razen 0, 1, 2, …, n, imamo p(Y= l)= 0. Binomska porazdelitev s fiksno velikostjo vzorca n se nastavi s parametrom str, tj. binomske porazdelitve tvorijo družino z enim parametrom. Uporabljajo se pri analizi vzorčnih raziskovalnih podatkov, zlasti pri preučevanju preferenc potrošnikov, selektivnem nadzoru kakovosti izdelkov po načrtih enostopenjskega nadzora, pri testiranju populacij posameznikov v demografiji, sociologiji, medicini, biologiji itd.
če Y 1 in Y 2 - neodvisne binomske naključne spremenljivke z enakim parametrom str 0 določeno z vzorci z volumni n 1 in n 2 oziroma torej Y 1 + Y 2 - binomska naključna spremenljivka s porazdelitvijo (19) z R = str 0 in n = n 1 + n 2 . Ta opomba razširja uporabnost binomske porazdelitve in vam omogoča združevanje rezultatov več skupin testov, kadar obstaja razlog za domnevo, da isti parameter ustreza vsem tem skupinam.
Značilnosti binomske porazdelitve so bile izračunane prej:
M(Y) = np, D(Y) = np( 1- str).
V razdelku "Dogodki in verjetnosti" za binomsko naključno spremenljivko je dokazan zakon velikih števil:
![]()
za kogarkoli. S pomočjo osrednjega mejnega izreka je mogoče zakon velikih števil izboljšati tako, da pokažemo, kako Y/ n razlikuje od R.
De Moivre-Laplaceov izrek. Za poljubna števila a in b, a< b, imamo

Kje F(X) je standardna funkcija normalne porazdelitve s povprečjem 0 in varianco 1.
Da bi to dokazali, zadostuje uporaba reprezentacije Y kot vsota neodvisnih naključnih spremenljivk, ki ustrezajo rezultatom posameznih poskusov, formule za M(Y) in D(Y) in osrednji mejni izrek.
Ta izrek je za ta primer R= ½ je leta 1730 dokazal angleški matematik A. Moivre (1667-1754). V zgornji formulaciji jo je leta 1810 dokazal francoski matematik Pierre Simon Laplace (1749-1827).
Hipergeometrična porazdelitev poteka med selektivnim nadzorom končne množice objektov prostornine N glede na alternativno značilnost. Vsak nadzorovani predmet je razvrščen tako, da ima atribut A, ali da nima te funkcije. Hipergeometrična porazdelitev ima naključno spremenljivko Y, enako številu predmeti, ki imajo atribut A v naključnem vzorcu količine n, Kje n< n. Na primer številka Y enote izdelkov z napako v naključnem vzorcu količine n iz volumna serije n ima hipergeometrično porazdelitev, če n< n. Drug primer je loterija. Naj znak A vstopnica je znak "dobitka". Naj vse vstopnice n, in neka oseba je pridobila n izmed njih. Nato ima število zmagovalnih listkov za to osebo hipergeometrično porazdelitev.
Za hipergeometrično porazdelitev ima verjetnost, da naključna spremenljivka Y prevzame vrednost y, obliko
 (20)
(20)
Kje D je število predmetov, ki imajo atribut A, v obravnavanem nizu obsega n. pri čemer l prevzame vrednosti od max(0, n - (n - D)) do min( n, D), z drugimi l verjetnost v formuli (20) je enaka 0. Tako je hipergeometrična porazdelitev določena s tremi parametri - prostornino prebivalstvo n, število predmetov D v njem, ki ima obravnavano lastnost A in velikost vzorca n.
Preprosto naključno vzorčenje n od celotne prostornine n se imenuje vzorec, dobljen kot rezultat naključne izbire, v katerem je kateri koli od nizov iz n predmetov ima enako verjetnost, da bo izbran. Metode naključnega izbora vzorcev respondentov (intervjuvancev) ali enot kosovnih izdelkov so obravnavane v instruktivno-metodičnih in normativno-tehničnih dokumentih. Eden od načinov izbire je naslednji: predmeti se izbirajo drug od drugega in na vsakem koraku ima vsak od preostalih predmetov v nizu enako možnost, da bo izbran. V literaturi se za vrsto obravnavanih vzorcev uporabljajo tudi izrazi »naključni vzorec«, »naključni vzorec brez zamenjave«.
Ker obseg splošne populacije (loti) n in vzorci n so splošno znani, potem je parameter hipergeometrične porazdelitve, ki ga je treba oceniti D. V statističnih metodah upravljanja kakovosti izdelkov D- običajno število okvarjenih enot v seriji. Zanimiva je tudi značilnost porazdelitve D/ n- stopnja napake.
Za hipergeometrično porazdelitev
Zadnji faktor v izrazu variance je blizu 1, če n>10 n. Če hkrati izvedemo zamenjavo str = D/ n, potem se bodo izrazi za matematično pričakovanje in varianco hipergeometrične porazdelitve spremenili v izraze za matematično pričakovanje in varianco binomske porazdelitve. To ni naključje. Lahko se pokaže, da

pri n>10 n, Kje str = D/ n. Mejno razmerje velja
in to omejevalno razmerje je mogoče uporabiti za n>10 n.
Tretja pogosto uporabljena diskretna porazdelitev je Poissonova porazdelitev. Naključna spremenljivka Y ima Poissonovo porazdelitev, če
![]() ,
,
kjer je λ parameter Poissonove porazdelitve in p(Y= l)= 0 za vse ostale l(pri y=0 je označeno 0!=1). Za Poissonovo porazdelitev
M(Y) = λ, D(Y) = λ.
Ta porazdelitev je dobila ime po francoskem matematiku C. D. Poissonu (1781-1840), ki jo je prvi izpeljal leta 1837. Poissonova porazdelitev je skrajni primer binomske porazdelitve, kjer je verjetnost R izvedba dogodka je majhna, a število poskusov n super, in np= λ. Natančneje, mejno razmerje
Zato se Poissonova porazdelitev (v stari terminologiji "distribucijski zakon") pogosto imenuje tudi "zakon redkih dogodkov".
Poissonova porazdelitev se pojavi v teoriji tokov dogodkov (glej zgoraj). Dokazano je, da je za najenostavnejši tok s konstantno intenzivnostjo Λ število dogodkov (klicev), ki so se zgodili v času t, ima Poissonovo porazdelitev s parametrom λ = Λ t. Zato je verjetnost, da v času t ne bo prišlo do nobenega dogodka e - Λ t, tj. porazdelitvena funkcija dolžine intervala med dogodki je eksponentna.
Poissonova porazdelitev se uporablja pri analizi rezultatov selektivnih tržnih raziskav potrošnikov, izračunu operativnih značilnosti načrtov nadzora statistične sprejemljivosti v primeru majhnih vrednosti stopnje sprejemljivosti pomanjkljivosti, za opis števila okvar. statistično nadzorovanega tehnološkega procesa na časovno enoto, število "zahtev za storitev", ki prispejo na časovno enoto v sistem čakalne vrste, statistične zakonitosti nesreč in redke bolezni itd.
Opis drugih parametričnih družin diskretnih porazdelitev in njihovih možnosti praktično uporabo upoštevana v literaturi.
V nekaterih primerih, na primer pri proučevanju cen, obsega proizvodnje ali skupnega časa med napakami pri težavah z zanesljivostjo, so porazdelitvene funkcije konstantne v določenih intervalih, v katerih vrednosti preučevanih naključnih spremenljivk ne morejo pasti.
| Prejšnja |
3. Distribucijska funkcija je nepadajoča: če, potem
4. Porazdelitvena funkcija levo neprekinjeno: za vsakogar.
Opomba. Zadnja lastnost označuje, katere vrednosti ima distribucijska funkcija na prelomnih točkah. Včasih je definicija porazdelitvene funkcije oblikovana z uporabo nestroge neenakosti: . V tem primeru se zveznost na levi nadomesti z zveznostjo na desni: za . V tem primeru se ne spremenijo nobene vsebinske lastnosti porazdelitvene funkcije, zato je to vprašanje le terminološko.
Lastnosti 1-4 so značilne, tj. vsaka funkcija, ki izpolnjuje te lastnosti, je porazdelitvena funkcija neke naključne spremenljivke.
Porazdelitvena funkcija enolično definira porazdelitev verjetnosti naključne spremenljivke. Pravzaprav je to najbolj univerzalen in najbolj ilustrativen način za opis te porazdelitve.
Čim močneje raste distribucijska funkcija na danem intervalu numerične osi, tem večja je verjetnost, da bo naključna spremenljivka padla v ta interval. Če je verjetnost padca v interval enaka nič, potem je porazdelitvena funkcija na njem konstantna.
Zlasti je verjetnost, da bo naključna spremenljivka prevzela dano vrednost, enaka skoku porazdelitvene funkcije na dani točki:
.Če je distribucijska funkcija zvezna v točki , potem je verjetnost, da vzamemo to vrednost za naključno spremenljivko, enaka nič. Zlasti, če je porazdelitvena funkcija zvezna na celotni realni osi (v tem primeru imenujemo tudi ustrezno porazdelitev neprekinjeno), potem je verjetnost sprejema katere koli dane vrednosti enaka nič.
Iz definicije porazdelitvene funkcije sledi, da je verjetnost, da naključna spremenljivka pade v levo zaprt in desno odprt interval enaka:
Z uporabo te formule in zgornje metode za iskanje verjetnosti zadetka katere koli dane točke se zlahka določijo verjetnosti zadetka naključne spremenljivke v intervalih drugih vrst: , in . Nadalje lahko z izrekom o razširitvi mere enolično razširimo mero na vse Borelove množice realne premice. Za uporabo tega izreka je treba pokazati, da je tako definirana mera na intervalih sigma-aditivna na intervalih; lastnosti 1-4 so uporabljene točno v dokazu tega (zlasti lastnost kontinuitete na levi je 4, zato je ni mogoče opustiti).
Generiranje naključne spremenljivke z dano porazdelitvijo
Razmislite o naključni spremenljivki s porazdelitveno funkcijo. Pretvarjajmo se, da neprekinjeno. Razmislite o naključni spremenljivki
.Zlahka je pokazati, da bo imela enakomerno porazdelitev na intervalu.
Definicija funkcije naključnih spremenljivk. Funkcija diskretnega naključnega argumenta in njegove numerične značilnosti. Funkcija zveznega naključnega argumenta in njegove numerične značilnosti. Funkcije dveh naključnih argumentov. Določanje funkcije porazdelitve verjetnosti in gostote za funkcijo dveh naključnih argumentov.
Zakon porazdelitve verjetnosti za funkcijo ene naključne spremenljivke
Pri reševanju problemov, povezanih z ocenjevanjem natančnosti delovanja različnih avtomatskih sistemov, natančnosti izdelave posameznih elementov sistemov itd., je pogosto treba upoštevati funkcije ene ali več slučajnih spremenljivk. Takšne funkcije so tudi naključne spremenljivke. Zato je pri reševanju problemov potrebno poznati zakone porazdelitve naključnih spremenljivk, ki se pojavljajo v problemu. V tem primeru sta običajno znana zakon porazdelitve sistema naključnih argumentov in funkcionalna odvisnost.
Tako se pojavi problem, ki ga lahko formuliramo na naslednji način.
Podan je sistem naključnih spremenljivk (X_1,X_2,\lpike,X_n), katerega distribucijski zakon je znan. Neka naključna spremenljivka Y se obravnava kot funkcija teh naključnih spremenljivk:
Y=\varphi(X_1,X_2,\ldots,X_n).
Določiti je treba zakon porazdelitve naključne spremenljivke Y ob poznavanju oblike funkcij (6.1) in zakona skupne porazdelitve njenih argumentov.
Razmislite o problemu porazdelitvenega zakona funkcije enega naključnega argumenta
Y=\varphi(X).
\begin(matrika)(|c|c|c|c|c|)\hline(X)&x_1&x_2&\cdots&x_n\\\hline(P)&p_1&p_2&\cdots&p_n\\\hline\end(matrika)
Potem je Y=\varphi(X) tudi diskretna naključna spremenljivka z možnimi vrednostmi. Če vse vrednosti y_1,y_2,\lpike,y_n so različni, potem za vsak k=1,2,\ldots,n dogodki \(X=x_k\) in \(Y=y_k=\varphi(x_k)\) so enaki. torej
P\(Y=y_k\)=P\(X=x_k\)=p_k
in želena porazdelitvena serija ima obliko
\begin(matrika)(|c|c|c|c|c|)\hline(Y)&y_1=\varphi(x_1)&y_2=\varphi(x_2)&\cdots&y_n=\varphi(x_n)\\\hline (P)&p_1&p_2&\cdots&p_n\\\hline\end(matrika)
Če med številkami y_1=\varphi(x_1),y_2=\varphi(x_2),\ldots,y_n=\varphi(x_n) so enake, potem je treba vsaki skupini enakih vrednosti y_k=\varphi(x_k) dodeliti en stolpec v tabeli in dodati ustrezne verjetnosti.
Za zvezne naključne spremenljivke je problem formuliran takole: ob poznavanju gostote porazdelitve f(x) naključne spremenljivke X poiščite gostoto porazdelitve g(y) naključne spremenljivke Y=\varphi(X) . Pri reševanju problema upoštevamo dva primera.
Najprej predpostavimo, da je funkcija y=\varphi(x) monotono naraščajoča, zvezna in diferenciabilna na intervalu (a;b), ki vsebuje vse možne vrednosti vrednosti X. Potem inverzna funkcija x=\psi(y) obstaja in je tudi monotono naraščajoča, zvezna in diferencibilna. V tem primeru dobimo
G(y)=f\bigl(\psi(y)\bigr)\cdot |\psi"(y)|.
Primer 1. Naključna spremenljivka X je porazdeljena z gostoto
F(x)=\frac(1)(\sqrt(2\pi))e^(-x^2/2)
Poiščite porazdelitveni zakon naključne spremenljivke Y, povezane z vrednostjo X z odvisnostjo Y=X^3 .
rešitev. Ker je funkcija y=x^3 monotona na intervalu (-\infty;+\infty) , lahko uporabimo formulo (6.2). Inverzna funkcija glede na funkcijo \varphi(x)=x^3 je \psi(y)=\sqrt(y) , njena izpeljanka \psi"(y)=\frac(1)(3\sqrt(y^2)). torej
G(y)=\frac(1)(3\sqrt(2\pi))e^(-\sqrt(y^2)/2)\frac(1)(\sqrt(y^2))
Razmislite o primeru nemonotone funkcije. Naj bo funkcija y=\varphi(x) taka, da je inverzna funkcija x=\psi(y) dvoumna, tj. ena vrednost y ustreza več vrednostim argumenta x , ki jih označimo x_1=\psi_1(y),x_2=\psi_2(y),\ldots,x_n=\psi_n(y), kjer je n število segmentov, kjer se funkcija y=\varphi(x) monotono spreminja. Potem
G(y)=\sum\limits_(k=1)^(n)f\bigl(\psi_k(y)\bigr)\cdot |\psi"_k(y)|.
Primer 2. Pod pogoji iz primera 1 poiščite porazdelitev naključne spremenljivke Y=X^2 .
rešitev. Inverzna funkcija x=\psi(y) je dvoumna. Ena vrednost argumenta y ustreza dvema vrednostima funkcije x
Z uporabo formule (6.3) dobimo:
\begin(gathered)g(y)=f(\psi_1(y))|\psi"_1(y)|+f(\psi_2(y))|\psi"_2(y)|=\\\\ =\frac(1)(\sqrt(2\pi))\,e^(-\left(-\sqrt(y^2)\desno)^2/2)\!\levo|-\frac(1 )(2\sqrt(y))\desno|+\frac(1)(\sqrt(2\pi))\,e^(-\levo(\sqrt(y^2)\desno)^2/2 )\!\levo|\frac(1)(2\sqrt(y))\desno|=\frac(1)(\sqrt(2\pi(y)))\,e^(-y/2) .\konec(zbrano)
Porazdelitveni zakon funkcije dveh naključnih spremenljivk
Naj bo naključna spremenljivka Y funkcija dveh naključnih spremenljivk, ki tvorita sistem (X_1;X_2), tj. Y=\varphi(X_1;X_2). Naloga je najti porazdelitev naključne spremenljivke Y iz znane porazdelitve sistema (X_1;X_2).
Naj bo f(x_1;x_2) gostota porazdelitve sistema naključnih spremenljivk (X_1;X_2). Vstavimo novo vrednost Y_1, ki je enaka X_1, in razmislimo o sistemu enačb
Predpostavili bomo, da je ta sistem enolično rešljiv glede na x_1,x_2
in izpolnjuje pogoje diferenciabilnosti.
Gostota porazdelitve naključne spremenljivke Y
G_1(y)=\int\limits_(-\infty)^(+\infty)f(x_1;\psi(y;x_1))\!\levo|\frac(\partial\psi(y;x_1)) (\delno(y))\desno|dx_1.
Upoštevajte, da se sklepanje ne spremeni, če je uvedena nova vrednost Y_1 enaka X_2.
Matematično pričakovanje funkcije slučajnih spremenljivk
V praksi pogosto obstajajo primeri, ko ni posebne potrebe po popolni določitvi distribucijskega zakona funkcije naključnih spremenljivk, ampak je dovolj le navesti njene numerične značilnosti. Tako se pojavi problem določanja numeričnih značilnosti funkcij slučajnih spremenljivk poleg zakonov porazdelitve teh funkcij.
Naj bo naključna spremenljivka Y funkcija naključnega argumenta X z danim porazdelitvenim zakonom
Y=\varphi(X).
Brez iskanja zakona porazdelitve količine Y je potrebno določiti njeno matematično pričakovanje
M(Y)=M[\varphi(X)].
Naj bo X diskretna naključna spremenljivka s porazdelitvenim nizom
\begin(array)(|c|c|c|c|c|)\hline(x_i)&x_1&x_2&\cdots&x_n\\\hline(p_i)&p_1&p_2&\cdots&p_n\\\hline\end(array)
Naredimo tabelo vrednosti Y in verjetnosti teh vrednosti:
\begin(matrika)(|c|c|c|c|c|)\hline(y_i=\varphi(x_i))&y_1=\varphi(x_1)&y_2=\varphi(x_2)&\cdots&y_n=\varphi( x_n)\\\hline(p_i)&p_1&p_2&\cdots&p_n\\\hline\end(matrika)
Ta tabela ni serija porazdelitve naključne spremenljivke Y, saj lahko v splošnem primeru nekatere vrednosti sovpadajo med seboj in vrednosti v zgornji vrstici ne gredo nujno v naraščajočem vrstnem redu. Vendar pa je matematično pričakovanje naključne spremenljivke Y mogoče določiti s formulo
M[\varphi(X)]=\sum\limits_(i=1)^(n)\varphi(x_i)p_i,
saj se vrednost, določena s formulo (6.4), ne more spremeniti zaradi dejstva, da so pod znakom vsote nekateri členi vnaprej združeni in se spremeni vrstni red členov.
Formula (6.4) ne vsebuje eksplicitno porazdelitvenega zakona same funkcije \varphi(X), ampak vsebuje le porazdelitveni zakon argumenta X . Tako za določitev matematičnega pričakovanja funkcije Y=\varphi(X) sploh ni potrebno poznati porazdelitveni zakon funkcije \varphi(X), ampak je dovolj poznati porazdelitveni zakon argumenta X .
Za zvezno naključno spremenljivko se matematično pričakovanje izračuna po formuli
M[\varphi(X)]=\int\limits_(-\infty)^(+\infty)\varphi(x)f(x)\,dx,
kjer je f(x) gostota porazdelitve verjetnosti naključne spremenljivke X .
Razmislimo o primerih, ko za iskanje matematičnega pričakovanja funkcije naključnih argumentov ni treba poznati niti zakonov porazdelitve argumentov, ampak je dovolj poznati le nekatere njihove numerične značilnosti. Te primere oblikujmo v obliki izrekov.
Izrek 6.1. Matematično pričakovanje vsote tako odvisnih kot neodvisnih dveh naključnih spremenljivk je enako vsoti matematičnih pričakovanj teh spremenljivk:
M(X+Y)=M(X)+M(Y).
Izrek 6.2. Matematično pričakovanje produkta dveh naključnih spremenljivk je enako produktu njunih matematičnih pričakovanj plus korelacijski moment:
M(XY)=M(X)M(Y)+\mu_(xy).
Posledica 6.1. Matematično pričakovanje produkta dveh nekoreliranih naključnih spremenljivk je enako produktu njunih matematičnih pričakovanj.
Posledica 6.2. Matematično pričakovanje produkta dveh neodvisnih naključnih spremenljivk je enako produktu njunih matematičnih pričakovanj.
Varianca funkcije naključnih spremenljivk
Po definiciji disperzije imamo D[Y]=M[(Y-M(Y))^2].. torej
D[\varphi(x)]=M[(\varphi(x)-M(\varphi(x)))^2], Kje .
Formule za izračun podajamo le za primer zveznih naključnih argumentov. Za funkcijo enega naključnega argumenta Y=\varphi(X) je varianca izražena s formulo
D[\varphi(x)]=\int\limits_(-\infty)^(+\infty)(\varphi(x)-M(\varphi(x)))^2f(x)\,dx,
Kje M(\varphi(x))=M[\varphi(X)]- matematično pričakovanje funkcije \varphi(X) ; f(x) - gostota porazdelitve količine X .
Formulo (6.5) lahko nadomestimo z naslednjim:
D[\varphi(x)]=\int\limits_(-\infty)^(+\infty)\varphi^2(x)f(x)\,dx-M^2(X)
Razmislite disperzijski izreki, ki igrajo pomembno vlogo v teoriji verjetnosti in njenih aplikacijah.
Izrek 6.3. Varianca vsote naključnih spremenljivk je enaka vsoti varianc teh spremenljivk plus dvakratna vsota korelacijskih momentov vsakega od členov z vsemi naslednjimi:
D\!\levo[\sum\limits_(i=1)^(n)X_i\desno]=\sum\limits_(i=1)^(n)D+2\sum\limits_(i Posledica 6.3. Varianca vsote nekoreliranih naključnih spremenljivk je enaka vsoti varianc členov: D\!\levo[\sum\limits_(i=1)^(n)X_i\desno]=\sum\limits_(i=1)^(n)D\mu_(y_1y_2)= M(Y_1Y_2)-M(Y_1)M(Y_2). \mu_(y_1y_2)=M(\varphi_1(X)\varphi_2(X))-M(\varphi_1(X))M(\varphi_2(X)). Razmislite o glavnem lastnosti korelacijskega momenta in korelacijskega koeficienta. Lastnost 1. Od dodajanja konstantnih vrednosti naključnim spremenljivkam se korelacijski moment in korelacijski koeficient ne spremenita. Lastnost 2. Za katero koli naključno spremenljivko X in Y absolutna vrednost korelacijskega momenta ne presega geometrične sredine disperzij teh količin: |\mu_(xy)|\leqslant\sqrt(D[X]\cdot D[Y])=\sigma_x\cdot \sigma_y, Naključna spremenljivka
je spremenljivka, ki lahko zavzame določene vrednosti glede na različne okoliščine in naključno spremenljivko imenujemo zvezna
, če lahko sprejme katero koli vrednost iz nekega omejenega ali neomejenega intervala. Za neprekinjeno naključno spremenljivko je nemogoče določiti vse možne vrednosti, zato so označeni intervali teh vrednosti, ki so povezani z določenimi verjetnostmi. Primeri zveznih naključnih spremenljivk so: premer dela, obrnjenega na določeno velikost, višina osebe, domet izstrelka itd. Ker je za zvezne naključne spremenljivke funkcija F(x), Za razliko od diskretne naključne spremenljivke, nima nikjer nobenih skokov, potem je verjetnost katerekoli posamezne vrednosti zvezne naključne spremenljivke enaka nič. To pomeni, da za zvezno naključno spremenljivko nima smisla govoriti o porazdelitvi verjetnosti med njenimi vrednostmi: vsaka od njih ima ničelno verjetnost. Vendar pa so v določenem smislu med vrednostmi zvezne naključne spremenljivke "bolj in manj verjetne". Na primer, malo verjetno je, da bo kdo dvomil, da je vrednost naključne spremenljivke - višina naključno srečane osebe - 170 cm - verjetnejša od 220 cm, čeprav se ena in druga vrednost lahko pojavita v praksi. Kot porazdelitveni zakon, ki je smiseln samo za zvezne naključne spremenljivke, je uveden pojem porazdelitvene gostote ali verjetnostne gostote. Približajmo se ji tako, da primerjamo pomen porazdelitvene funkcije za zvezno naključno spremenljivko in za diskretno naključno spremenljivko. Torej, porazdelitvena funkcija slučajne spremenljivke (tako diskretne kot zvezne) oz integralna funkcija se imenuje funkcija, ki določa verjetnost, da bo vrednost naključne spremenljivke X manjša ali enaka mejni vrednosti X. Za diskretno naključno spremenljivko v točkah njenih vrednosti x1
, x 2
, ..., x jaz ,... koncentrirane množice verjetnosti str1
, str 2
, ..., str jaz ,..., vsota vseh mas pa je enaka 1. Prenesimo to interpretacijo na primer zvezne naključne spremenljivke. Predstavljajte si, da masa, enaka 1, ni koncentrirana na ločenih točkah, ampak je nenehno "razmazana" vzdolž osi x Ox z nekaj neenakomerne gostote. Verjetnost zadetka naključne spremenljivke na katerem koli mestu Δ x se razlaga kot masa, ki jo je mogoče pripisati temu odseku, in povprečna gostota v tem odseku - kot razmerje med maso in dolžino. Pravkar smo predstavili pomemben koncept v teoriji verjetnosti: gostoto porazdelitve. Gostota verjetnosti f(x) zvezne naključne spremenljivke je odvod njene porazdelitvene funkcije: Če poznamo funkcijo gostote, lahko ugotovimo verjetnost, da vrednost zvezne naključne spremenljivke pripada zaprtemu intervalu [ a; b]: verjetnost, da zvezna naključna spremenljivka X bo vzel poljubno vrednost iz intervala [ a; b], je enak določenemu integralu njegove gostote verjetnosti v območju od a prej b: V tem primeru splošna formula funkcije F(x) verjetnostna porazdelitev zvezne naključne spremenljivke, ki se lahko uporabi, če je znana funkcija gostote f(x)
: Graf gostote verjetnosti zvezne naključne spremenljivke se imenuje njena porazdelitvena krivulja (slika spodaj). Območje figure (osenčeno na sliki), omejeno s krivuljo, ravne črte, narisane iz točk a in b pravokotno na abscisno os, in os Oh, grafično prikaže verjetnost, da bo vrednost zvezne naključne spremenljivke X je v območju a prej b. 1. Verjetnost, da bo naključna spremenljivka prevzela katero koli vrednost iz intervala (in območje slike, ki je omejeno z grafom funkcije f(x) in os Oh) je enako ena: 2. Funkcija gostote verjetnosti ne more imeti negativnih vrednosti: zunaj obstoja porazdelitve pa je njegova vrednost enaka nič Gostota porazdelitve f(x), kot tudi distribucijska funkcija F(x), je ena od oblik porazdelitvenega zakona, vendar za razliko od porazdelitvene funkcije ni univerzalna: gostota porazdelitve obstaja samo za zvezne naključne spremenljivke. Omenimo dva v praksi najpomembnejša tipa porazdelitve zvezne naključne spremenljivke. Če funkcija gostote porazdelitve f(x) zvezna naključna spremenljivka v nekem končnem intervalu [ a; b] ima konstantno vrednost C, zunaj intervala pa dobi vrednost enako nič, potem to porazdelitev imenujemo enakomerna . Če je graf funkcije gostote porazdelitve simetričen glede na središče, so povprečne vrednosti koncentrirane blizu središča, pri odmiku od središča pa se zbere več različnih povprečij (graf funkcije je podoben rezu zvonec), potem to porazdelitev imenujemo normalna . Primer 1 Funkcija porazdelitve verjetnosti zvezne naključne spremenljivke je znana: Poiščite funkcijo f(x) gostota verjetnosti zvezne naključne spremenljivke. Narišite grafa za obe funkciji. Poiščite verjetnost, da bo zvezna naključna spremenljivka sprejela katero koli vrednost v območju od 4 do 8: . rešitev. Funkcijo gostote verjetnosti dobimo tako, da poiščemo odvod funkcije porazdelitve verjetnosti: Funkcijski graf F(x) - parabola: Funkcijski graf f(x) - ravna črta: Poiščimo verjetnost, da bo zvezna naključna spremenljivka prevzela katero koli vrednost v območju od 4 do 8: Primer 2 Funkcija gostote verjetnosti zvezne naključne spremenljivke je podana kot: Izračunaj faktor C. Poiščite funkcijo F(x) verjetnostna porazdelitev zvezne naključne spremenljivke. Narišite grafa za obe funkciji. Poiščite verjetnost, da bo zvezna naključna spremenljivka sprejela katero koli vrednost v območju od 0 do 5: . rešitev. Koeficient C z uporabo lastnosti 1 funkcije gostote verjetnosti najdemo: Tako je funkcija gostote verjetnosti zvezne naključne spremenljivke: Z integracijo najdemo funkcijo F(x) verjetnostne porazdelitve. če x < 0
, то
F(x) = 0 . Če je 0< x < 10
, то x> 10 torej F(x) = 1
. torej popoln zapis funkcije porazdelitve verjetnosti: Funkcijski graf f(x)
: Funkcijski graf F(x)
: Poiščimo verjetnost, da bo zvezna naključna spremenljivka prevzela katero koli vrednost v območju od 0 do 5: Primer 3 Gostota verjetnosti zvezne naključne spremenljivke X je podana z enakostjo , medtem ko . Poiščite koeficient A, verjetnost, da zvezna naključna spremenljivka X prevzame neko vrednost iz intervala ]0, 5[, porazdelitvene funkcije zvezne naključne spremenljivke X. rešitev. Po pogoju pridemo do enakosti Torej, od kod. Torej, Zdaj najdemo verjetnost, da zvezna naključna spremenljivka X bo prevzel katero koli vrednost iz intervala ]0, 5[: Zdaj dobimo porazdelitveno funkcijo te naključne spremenljivke: Primer 4 Poiščite gostoto verjetnosti zvezne naključne spremenljivke X, ki zavzema le nenegativne vrednosti, in njeno distribucijsko funkcijo
tj. korelacijski moment dveh funkcij naključnih spremenljivk je enak matematičnemu pričakovanju produkta teh funkcij minus produkt matematičnih pričakovanj. Porazdelitvena funkcija zvezne naključne spremenljivke in gostota verjetnosti
![]() .
.
![]()
![]() .
.![]() .
.
Lastnosti funkcije gostote verjetnosti zvezne naključne spremenljivke





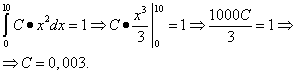
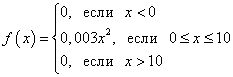
![]() .
.


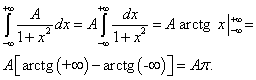
![]() .
.

![]() .
.

