Tema No. 11
En la práctica, para especificar variables aleatorias vista general Generalmente se utiliza la función de distribución.
La probabilidad de que valor aleatorio X tomará un cierto valor x 0, expresado a través de la función de distribución según la fórmula
R (X = x 0) = F(x 0 +0) – F(x 0).(3)
En particular, si en el punto x = x 0 la función F(x) es continua, entonces
R (X = x0) =0.
Valor aleatorio X con distribución Pensilvania) se llama discreto si hay un conjunto finito o contable W en la recta numérica tal que R(W,) = 1.
Sea W = ( x1, x2,…) Y Pi= pag({xyo}) = pag(X = xyo), i= 1,2,….Entonces para cualquier conjunto de Borel A probabilidad Pensilvania) está determinado únicamente por la fórmula
Poniendo esta fórmula A = (x yo / x yo< x}, x Î R , obtenemos la fórmula para la función de distribución. F(x) variable aleatoria discreta X:
F(x) = pag(X < X) =. (5)
Gráfica de una función F(x) es una línea escalonada. Saltos de función F(x) en puntos x = x 1, x 2…(x 1
Ejemplo 1: encontrar la función de distribución
variable aleatoria discreta x del Ejemplo 1§ 13.
Usando la función de distribución, calcule
probabilidad de eventos: x< 3, 1 £ x < 4, 1 £ x £ 3.

|
|
obtenido en el § 13, y la fórmula (5), obtenemos
función de distribución:

Según la fórmula (1) Р(x< 3) = F(3) = 0,1808; по формуле (2)
p(1 £x< 4) = F (4) – F(1) = 0,5904 – 0,0016 = 0,5888;
p (1 £ x £ 3) = p (1 £ x<3) + p(x = 3) = F(3) – F(1) + F(3+0) – F(3) =
F(3+0) – F(1) = 0,5904 – 0,0016 = 0,5888.
Ejemplo 2. Dada una función

¿Es la función F(x) la función de distribución de alguna variable aleatoria? Si la respuesta es sí, encuentre ![]() . Dibuja una gráfica de la función F(x).
. Dibuja una gráfica de la función F(x).
Solución. Para que una función predeterminada F(x) sea una función de distribución de alguna variable aleatoria x, es necesario y suficiente que se cumplan las siguientes condiciones (propiedades características de la función de distribución):
1.  F(x) es una función no decreciente.
F(x) es una función no decreciente.
3. Para cualquier x О R F( X– 0) = F( X).
Para una función dada F(x), ejecución
estas condiciones son obvias. Medio,
F(x) – función de distribución.
Probabilidad  calcular por
calcular por
fórmula (2):
Gráfica de la función F( X) se presenta en la Figura 13.
Ejemplo 3. Sea F 1 ( X) y F 2 ( X) – funciones de distribución de variables aleatorias X 1 y X 2 respectivamente, A 1 y A 2 son números no negativos cuya suma es 1.
Demuestre que F( X) = a 1 F 1 ( X) + a 2 F 2 ( X) es la función de distribución de alguna variable aleatoria X.
Solución. 1) Desde F 1 ( X) y F 2 ( X) son funciones no decrecientes y A 1 ³ 0, A 2 ³ 0, entonces a 1 F 1 ( X) Y a 2 F 2 ( X) no son decrecientes, por lo tanto su suma F( X) tampoco es decreciente.
3) Para cualquier x О R F( X - 0) = a 1 F 1 ( X - 0) + a 2 F 2 ( X - 0)= a 1 F 1 ( X) + a 2 F 2 ( X) = F( X).
Ejemplo 4. Dada una función

¿Es F(x) la función de distribución de una variable aleatoria?
Solución. Es fácil ver que F(1) = 0,2 > 0,11 = F(1,1). Por lo tanto, F( X) no es no decreciente y, por lo tanto, no es una función de distribución de una variable aleatoria. Tenga en cuenta que las dos propiedades restantes son válidas para esta función.
Tarea de prueba número 11
1. Variable aleatoria discreta X
X) y, usándolo, encuentre las probabilidades de eventos: a) –2 £ X < 1; б) ½X½£ 2. Traza una gráfica de la función de distribución.
3. Variable aleatoria discreta X dado por la tabla de distribución:
| xyo | |||||
| Pi | 0,05 | 0,2 | 0,3 | 0,35 | 0,1 |
Encuentre la función de distribución F( X) y encuentre las probabilidades de los siguientes eventos: a) X < 2; б) 1 £ X < 4; в) 1 £ X£4; d) 1< X£4; d) X = 2,5.
4. Encuentre la función de distribución de una variable aleatoria discreta. X, igual al número de puntos obtenidos durante un lanzamiento de dados. Usando la función de distribución, encuentre la probabilidad de obtener al menos 5 puntos.
5. Se llevan a cabo pruebas consecutivas de confiabilidad de 5 dispositivos. Cada dispositivo posterior se prueba solo si el anterior resultó ser confiable. Cree una tabla de distribución y encuentre la función de distribución para el número aleatorio de pruebas de dispositivos si la probabilidad de pasar las pruebas para cada dispositivo es 0,9.
6. Se da la función de distribución de una variable aleatoria discreta. X:

a) Encuentre la probabilidad del evento 1 £ X£3.
b) Encuentre la tabla de distribución de la variable aleatoria. X.
7. Se da la función de distribución de una variable aleatoria discreta. X:

Haz una tabla de la distribución de esta variable aleatoria.
8. Lanzamiento de moneda norte una vez. Cree una tabla de distribución y encuentre la función de distribución para el número de apariciones del escudo de armas. Trazar la función de distribución en norte = 5.
9. Se lanza la moneda hasta que salga el escudo. Cree una tabla de distribución y encuentre la función de distribución para el número de apariciones de un dígito.
10. El francotirador dispara al objetivo hasta el primer impacto. La probabilidad de fallar un solo tiro es igual a R. Encuentre la función de distribución para el número de errores.
1.2.4. Variables aleatorias y sus distribuciones.
Distribuciones de variables aleatorias y funciones de distribución.. La distribución de una variable aleatoria numérica es una función que determina de forma única la probabilidad de que la variable aleatoria tome un valor determinado o pertenezca a un intervalo determinado.
La primera es si la variable aleatoria toma un número finito de valores. Entonces la distribución viene dada por la función P(X = x), asignando a cada valor posible X variable aleatoria X la probabilidad de que X=x.
La segunda es si la variable aleatoria toma infinitos valores. Esto sólo es posible cuando el espacio probabilístico en el que se define la variable aleatoria consta de un número infinito de eventos elementales. Entonces la distribución viene dada por el conjunto de probabilidades. Pensilvania <
X
Pensilvania <
X
Esta relación muestra que tanto la distribución se puede calcular a partir de la función de distribución como, a la inversa, la función de distribución se puede calcular a partir de la distribución.
Utilizado en probabilística métodos de estadística toma de decisiones y otros investigación aplicada Las funciones de distribución son discretas o continuas, o combinaciones de las mismas.
Las funciones de distribución discreta corresponden a variables aleatorias discretas que toman un número finito de valores o valores de un conjunto cuyos elementos pueden numerarse mediante números naturales (tales conjuntos se denominan contables en matemáticas). Su gráfico parece una escalera de mano (Fig. 1).
Ejemplo 1. Número X Los artículos defectuosos en un lote adquieren un valor de 0 con una probabilidad de 0,3, un valor de 1 con una probabilidad de 0,4, un valor de 2 con una probabilidad de 0,2 y un valor de 3 con una probabilidad de 0,1. Gráfica de la función de distribución de una variable aleatoria. X se muestra en la Fig. 1.
Figura 1. Gráfica de la función de distribución del número de productos defectuosos.
Las funciones de distribución continua no tienen saltos. Aumentan monótonamente a medida que aumenta el argumento, de 0 en a 1 en . Las variables aleatorias que tienen funciones de distribución continua se denominan continuas.
Las funciones de distribución continua utilizadas en los métodos de toma de decisiones estadístico-probabilístico tienen derivadas. Primera derivada f(x) funciones de distribución F(x) se llama densidad de probabilidad,
Usando la densidad de probabilidad, puedes determinar la función de distribución:
![]()
Para cualquier función de distribución.
Las propiedades enumeradas de las funciones de distribución se utilizan constantemente en métodos probabilísticos y estadísticos de toma de decisiones. En particular, la última igualdad implica una forma específica de constantes en las fórmulas para densidades de probabilidad que se consideran a continuación.
Ejemplo 2. A menudo se utiliza la siguiente función de distribución:
 (1)
(1)
Dónde a Y b– algunos números, a . Encontremos la densidad de probabilidad de esta función de distribución:

(en puntos x = un Y x = segundo derivada de una función F(x) no existe).
Una variable aleatoria con función de distribución (1) se denomina "distribuida uniformemente en el intervalo [ a; b]».
Las funciones de distribución mixta se producen, en particular, cuando las observaciones se detienen en algún punto. Por ejemplo, al analizar datos estadísticos obtenidos del uso de planes de pruebas de confiabilidad que prevén la finalización de las pruebas después de un cierto período. O al analizar datos sobre productos técnicos que requirieron reparaciones en garantía.
Ejemplo 3. Sea, por ejemplo, la vida útil de una bombilla eléctrica una variable aleatoria con una función de distribución Pie), y la prueba se realiza hasta que falle la bombilla, si esto ocurre en menos de 100 horas desde el inicio de la prueba, o hasta t 0= 100 horas. Dejar G(t)– función de distribución del tiempo de funcionamiento de la bombilla en buen estado durante esta prueba. Entonces

Función G(t) tiene un salto en un punto t 0, ya que la variable aleatoria correspondiente toma el valor t 0 con probabilidad 1- F(t0)> 0.
Características de las variables aleatorias. En los métodos estadístico-probabilísticos de toma de decisiones, se utilizan una serie de características de las variables aleatorias, expresadas mediante funciones de distribución y densidades de probabilidad.
Al describir la diferenciación de ingresos, al encontrar límites de confianza para los parámetros de distribuciones de variables aleatorias y en muchos otros casos, se utiliza un concepto como "cuantil de orden". R", donde 0< pag < 1 (обозначается xp). Orden cuantil R– el valor de una variable aleatoria para la cual la función de distribución toma el valor R o hay un “salto” desde un valor menor R a un valor mayor R(Figura 2). Puede suceder que esta condición se cumpla para todos los valores de x que pertenecen a este intervalo (es decir, la función de distribución es constante en este intervalo y es igual a R). Entonces cada uno de esos valores se denomina "cuantil de orden". R" Para funciones de distribución continua, por regla general, hay un solo cuantil xp orden R(Figura 2), y
F(x p) = p. (2)

Figura 2. Definición de cuantil xp orden R.
Ejemplo 4. Encontremos el cuantil xp orden R para la función de distribución F(x) de 1).
A las 0< pag < 1 квантиль xp se encuentra a partir de la ecuación
aquellos. xp = a + p(b – a) = a( 1- p) +pb. En pag= 0 cualquiera X < a es un cuantil de orden pag= 0. Orden cuantil pag= 1 es cualquier número X > b.
Para distribuciones discretas, por regla general, no hay xp, satisfaciendo la ecuación (2). Más precisamente, si la distribución de una variable aleatoria se da en la Tabla 1, donde x1< x 2 < … < x k , entonces la igualdad (2), considerada como una ecuación con respecto a xp, tiene soluciones sólo para k valores pag, a saber,
p = p 1 ,
pags = pags 1 + pags 2 ,
pags = pags 1 + pags 2 + pags 3 ,
p = p 1 + p 2 + …+ pm, 3 < metro < k,
pag = pag 1 + pag 2 + … + paquete.
Tabla 1.
Distribución de una variable aleatoria discreta.
Para los enumerados k valores de probabilidad pag solución xp la ecuación (2) no es única, es decir,
F(x) = p 1 + p 2 + … + p m
para todos X tal que x m< x < xm+1. Aquellos. xp- cualquier número del intervalo (x m; x m+1 ]. Para todos los demás R desde el intervalo (0;1), no incluido en la lista (3), hay un “salto” desde un valor menor R a un valor mayor R. Es decir, si
p 1 + p 2 + … + p m
Eso xp = xm+1.
La propiedad considerada de las distribuciones discretas crea dificultades importantes al tabular y utilizar dichas distribuciones, ya que es imposible mantener con precisión los valores numéricos típicos de las características de la distribución. En particular, esto es cierto para los valores críticos y niveles de significancia de pruebas estadísticas no paramétricas (ver más abajo), ya que las distribuciones de estadísticas de estas pruebas son discretas.
El orden cuantil es de gran importancia en estadística. R= ½. Se llama mediana (variable aleatoria X o sus funciones de distribución F(x)) y es designado Yo(X). En geometría existe el concepto de "mediana": una línea recta que pasa por el vértice de un triángulo y divide su lado opuesto por la mitad. En estadística matemática, la mediana divide por la mitad no el lado del triángulo, sino la distribución de una variable aleatoria: igualdad F(x 0,5)= 0,5 significa que la probabilidad de llegar a la izquierda x 0,5 y la probabilidad de llegar a la derecha x 0,5(o directamente a x 0,5) son iguales entre sí e iguales a ½, es decir
PAG(X < X 0,5) = PAG(X > X 0,5) = ½.
La mediana indica el "centro" de la distribución. Desde el punto de vista de uno de los conceptos modernos, la teoría de los procedimientos estadísticos estables, la mediana es una mejor característica de una variable aleatoria que valor esperado. Al procesar resultados de mediciones en una escala ordinal (consulte el capítulo sobre teoría de la medición), se puede utilizar la mediana, pero no la expectativa matemática.
Una característica de una variable aleatoria como la moda tiene un significado claro: el valor (o valores) de una variable aleatoria correspondiente al máximo local de la densidad de probabilidad para una variable aleatoria continua o al máximo local de la probabilidad para una variable aleatoria discreta. .
Si x0– moda de una variable aleatoria con densidad f(x), entonces, como se sabe por el cálculo diferencial, .
Una variable aleatoria puede tener muchas modas. Entonces, para una distribución uniforme (1) cada punto X tal que a< x < b , es moda. Sin embargo, esta es una excepción. La mayoría de las variables aleatorias utilizadas en los métodos estadísticos probabilísticos de toma de decisiones y otras investigaciones aplicadas tienen una moda. Las variables aleatorias, densidades y distribuciones que tienen una moda se denominan unimodales.
La expectativa matemática para variables aleatorias discretas con un número finito de valores se analiza en el capítulo "Eventos y probabilidades". Para una variable aleatoria continua X valor esperado M(X) satisface la igualdad
![]()
que es un análogo de la fórmula (5) del enunciado 2 del capítulo "Eventos y probabilidades".
Ejemplo 5. Expectativa de una variable aleatoria distribuida uniformemente X es igual
Para las variables aleatorias consideradas en este capítulo, todas aquellas propiedades de las expectativas y varianzas matemáticas que se consideraron anteriormente para variables aleatorias discretas con un número finito de valores son ciertas. Sin embargo, no proporcionamos pruebas de estas propiedades, ya que requieren profundizar en sutilezas matemáticas, lo cual no es necesario para la comprensión y la aplicación calificada de los métodos estadístico-probabilísticos de toma de decisiones.
Comentario. Este libro de texto evita deliberadamente las sutilezas matemáticas asociadas, en particular, con los conceptos de conjuntos mensurables y funciones mensurables, álgebra de eventos, etc. Quienes deseen dominar estos conceptos deben recurrir a la literatura especializada, en particular a la enciclopedia.
Cada una de las tres características (expectativa matemática, mediana, moda) describe el “centro” de la distribución de probabilidad. El concepto de "centro" se puede definir de diferentes maneras, de ahí tres características diferentes. Sin embargo, para una clase importante de distribuciones (unimodales simétricas) las tres características coinciden.
Densidad de distribución f(x)– densidad de distribución simétrica, si hay un número x0 tal que
![]() . (3)
. (3)
La igualdad (3) significa que la gráfica de la función y = f(x) simétrico con respecto a una línea vertical que pasa por el centro de simetría X = X 0. De (3) se deduce que la función de distribución simétrica satisface la relación
![]() (4)
(4)
Para una distribución simétrica con una moda, la expectativa matemática, la mediana y la moda coinciden y son iguales. x0.
El caso más importante es la simetría alrededor de 0, es decir x0= 0. Entonces (3) y (4) se convierten en igualdades
![]() (6)
(6)
respectivamente. Las relaciones anteriores muestran que no hay necesidad de tabular distribuciones simétricas para todos X, basta con tener mesas en X > x0.
Observemos una propiedad más de las distribuciones simétricas, que se utiliza constantemente en los métodos estadístico-probabilísticos de toma de decisiones y otras investigaciones aplicadas. Para una función de distribución continua
P(|X| < a) = P(-a < X < a) = F(a) – F(-a),
Dónde F– función de distribución de una variable aleatoria X. Si la función de distribución F es simétrico con respecto a 0, es decir la fórmula (6) es válida para ello, entonces
P(|X| < a) = 2F(a) – 1.
A menudo se utiliza otra formulación de la afirmación en cuestión: si
![]() .
.
Si y son cuantiles de orden y, respectivamente (ver (2)) de una función de distribución simétrica con respecto a 0, entonces de (6) se deduce que
De las características de la posición (esperanza matemática, mediana, moda), pasemos a las características de la dispersión de la variable aleatoria. X: varianza, desviación estándar y coeficiente de variación v. La definición y las propiedades de la dispersión de variables aleatorias discretas se analizaron en el capítulo anterior. Para variables aleatorias continuas
La desviación estándar es el valor no negativo de la raíz cuadrada de la varianza:
El coeficiente de variación es la relación entre la desviación estándar y la expectativa matemática:
El coeficiente de variación se aplica cuando M(X)> 0. Mide el diferencial en unidades relativas, mientras que la desviación estándar está en unidades absolutas.
Ejemplo 6. Para una variable aleatoria distribuida uniformemente X Encontremos la dispersión, la desviación estándar y el coeficiente de variación. La varianza es:

Cambiar la variable permite escribir:
Dónde C = (b – a)/ 2. Por tanto, la desviación estándar es igual a y el coeficiente de variación es:
Para cada variable aleatoria X determinar tres cantidades más - centradas Y, normalizado V y dado Ud.. Variable aleatoria centrada Y es la diferencia entre una variable aleatoria dada X y su expectativa matemática M(X), aquellos. Y = X-M(X). Expectativa de una variable aleatoria centrada Y es igual a 0, y la varianza es la varianza de una variable aleatoria dada: METRO(Y) = 0, D(Y) = D(X). Función de distribución FY(X) variable aleatoria centrada Y relacionado con la función de distribución F(X) variable aleatoria original X relación:
FY(X) = F(X + METRO(X)).
Las densidades de estas variables aleatorias satisfacen la igualdad.
f Y(X) = F(X + METRO(X)).
Variable aleatoria normalizada V es la razón de una variable aleatoria dada X a su desviación estándar, es decir . Expectativa y varianza de una variable aleatoria normalizada. V expresado a través de características X Entonces:
![]() ,
,
Dónde v– coeficiente de variación de la variable aleatoria original X. Para la función de distribución FV(X) y densidad f V(X) variable aleatoria normalizada V tenemos:
Dónde F(X) – función de distribución de la variable aleatoria original X, A F(X) – su densidad de probabilidad.
Variable aleatoria reducida Ud. es una variable aleatoria centrada y normalizada:
![]() .
.
Para la variable aleatoria dada
Las variables aleatorias normalizadas, centradas y reducidas se utilizan constantemente tanto en estudios teóricos como en algoritmos, productos de software y documentación reglamentaria, técnica e instructiva. En particular, porque las igualdades ![]() permiten simplificar la justificación de métodos, la formulación de teoremas y fórmulas de cálculo.
permiten simplificar la justificación de métodos, la formulación de teoremas y fórmulas de cálculo.
Se utilizan transformaciones de variables aleatorias y otras más generales. Así que si Y = hacha + b, Dónde a Y b– algunos números, entonces
Ejemplo 7. si entonces Y es la variable aleatoria reducida, y las fórmulas (8) se transforman en fórmulas (7).
Con cada variable aleatoria X puedes asociar muchas variables aleatorias Y, dado por la fórmula Y = hacha + b en diferentes a> 0 y b. Este conjunto se llama familia de cambio de escala, generado por la variable aleatoria X. Funciones de distribución FY(X) constituyen una familia de distribuciones de cambio de escala generadas por la función de distribución F(X). En lugar de Y = hacha + b A menudo uso la grabación.
![]()
Número Con se llama parámetro de desplazamiento y el número d- parámetro de escala. La fórmula (9) muestra que X– el resultado de medir una cierta cantidad – entra en Ud.– el resultado de medir la misma cantidad si el comienzo de la medición se traslada al punto Con y luego use la nueva unidad de medida, en d veces más grande que el anterior.
Para la familia de desplazamiento de escala (9), la distribución de X se denomina estándar. En los métodos estadísticos probabilísticos de toma de decisiones y otras investigaciones aplicadas, se utilizan la distribución normal estándar, la distribución estándar de Weibull-Gnedenko, la distribución gamma estándar, etc. (ver más abajo).
También se utilizan otras transformaciones de variables aleatorias. Por ejemplo, para una variable aleatoria positiva X están considerando Y= iniciar sesión X, donde LG X– logaritmo decimal de un número X. Cadena de igualdades
F Y (x) = P( LG X< x) = P(X < 10x) = F( 10X)
conecta funciones de distribución X Y Y.
Al procesar datos, se utilizan las siguientes características de una variable aleatoria X como momentos de orden q, es decir. expectativas matemáticas de una variable aleatoria xq, q= 1, 2, ... Por tanto, la expectativa matemática en sí es un momento de orden 1. Para una variable aleatoria discreta, el momento de orden q se puede calcular como
![]()
Para una variable aleatoria continua
![]()
Momentos de orden q También llamados momentos iniciales de orden. q, en contraste con las características relacionadas: momentos centrales de orden q, dado por la fórmula
Entonces, la dispersión es un momento central de orden 2.
Distribución normal y teorema del límite central. En los métodos probabilístico-estadísticos de toma de decisiones a menudo hablamos de distribución normal. A veces intentan utilizarlo para modelar la distribución de los datos iniciales (estos intentos no siempre están justificados; ver más abajo). Más importante aún, muchos métodos de procesamiento de datos se basan en el hecho de que los valores calculados tienen distribuciones cercanas a la normal.
Dejar X 1 , X 2 ,…, xn METRO(X yo) = metro y variaciones D(X yo) = , i = 1, 2,…, norte,... Como se desprende de los resultados del capítulo anterior,
Considere la variable aleatoria reducida ONU por la cantidad ![]() , a saber,
, a saber,
![]()
Como se desprende de las fórmulas (7), METRO(ONU) = 0, D(ONU) = 1.
(para términos distribuidos idénticamente). Dejar X 1 , X 2 ,…, xn, … – variables aleatorias independientes distribuidas idénticamente con expectativas matemáticas METRO(X yo) = metro y variaciones D(X yo) = , i = 1, 2,…, norte,... Entonces para cualquier x hay un límite
![]()
Dónde F(x)– función estándar distribución normal.
Más sobre la función F(x) – abajo (lea “fi de x”, porque F- Letra mayúscula griega "phi").
El teorema del límite central (CLT) recibe su nombre porque es el resultado matemático central y más comúnmente utilizado de la teoría de la probabilidad y la estadística matemática. La historia del CLT abarca unos 200 años: desde 1730, cuando el matemático inglés A. Moivre (1667-1754) publicó el primer resultado relacionado con el CLT (ver más abajo sobre el teorema de Moivre-Laplace), hasta los años veinte y treinta del siglo XIX. el siglo XX, cuando el finlandés J.W. Lindeberg, el francés Paul Levy (1886-1971), el yugoslavo V. Feller (1906-1970), el ruso A.Ya. Khinchin (1894-1959) y otros científicos obtuvieron las condiciones necesarias y suficientes para la validez del teorema clásico del límite central.
El desarrollo del tema en consideración no se detuvo ahí: estudiaron variables aleatorias que no tienen dispersión, es decir aquellos para quienes
![]()
(académico B.V. Gnedenko y otros), una situación en la que se suman variables aleatorias (más precisamente, elementos aleatorios) de naturaleza más compleja que los números (académicos Yu.V. Prokhorov, A.A. Borovkov y sus asociados), etc.
Función de distribución F(x) viene dada por la igualdad
![]() ,
,
¿Dónde está la densidad de la distribución normal estándar, que tiene una expresión bastante compleja?
![]() .
.
Aquí =3.1415925… es un número conocido en geometría, igual a la relación entre la circunferencia y el diámetro, mi = 2,718281828... - la base de los logaritmos naturales (para recordar este número, tenga en cuenta que 1828 es el año de nacimiento del escritor L.N. Tolstoi). Como se sabe por el análisis matemático,
![]()
Al procesar los resultados de las observaciones, la función de distribución normal no se calcula utilizando las fórmulas dadas, sino que se encuentra mediante tablas especiales o programas de computadora. Las mejores “Tablas de estadística matemática” en ruso fueron compiladas por los miembros correspondientes de la Academia de Ciencias de la URSS L.N. Bolshev y N.V. Smirnov.
La forma de la densidad de la distribución normal estándar se deriva de la teoría matemática, que no podemos considerar aquí, así como de la prueba del CLT.
A modo ilustrativo, proporcionamos pequeñas tablas de la función de distribución. F(x)(Tabla 2) y sus cuantiles (Tabla 3). Función F(x) simétrico alrededor de 0, lo que se refleja en la Tabla 2-3.
Tabla 2.
Función de distribución normal estándar.
Si la variable aleatoria X tiene una función de distribución F(x), Eso M(X) = 0, D(X) = 1. Esta afirmación está probada en la teoría de la probabilidad basada en el tipo de densidad de probabilidad. Es consistente con una afirmación similar para las características de la variable aleatoria reducida. ONU, lo cual es bastante natural, ya que el CLT establece que con un aumento ilimitado en el número de términos, la función de distribución ONU tiende a la función de distribución normal estándar F(x), y para cualquier X.
Tabla 3.
Cuantiles de la distribución normal estándar.
Orden cuantil R |
Orden cuantil R |
||
Introduzcamos el concepto de familia de distribuciones normales. Por definición, una distribución normal es la distribución de una variable aleatoria X, para lo cual la distribución de la variable aleatoria reducida es F(x). Como se desprende de las propiedades generales de las familias de distribuciones de cambio de escala (ver arriba), una distribución normal es una distribución de una variable aleatoria.
Dónde X– variable aleatoria con distribución F(X), y metro = METRO(Y), = D(Y). Distribución normal con parámetros de cambio. metro y la escala suele estar indicada norte(metro, ) (a veces se utiliza la notación norte(metro, ) ).
Como se desprende de (8), la densidad de probabilidad de la distribución normal norte(metro, ) Hay

Las distribuciones normales forman una familia de cambios de escala. En este caso, el parámetro de escala es d= 1/ , y el parámetro de desplazamiento C = - metro/ .
Para los momentos centrales de tercer y cuarto orden de la distribución normal, son válidas las siguientes igualdades:
![]()
Estas igualdades forman la base de los métodos clásicos para verificar que las observaciones siguen una distribución normal. Hoy en día se suele recomendar probar la normalidad utilizando el criterio W. Shapiro - Wilka. El problema de las pruebas de normalidad se analiza a continuación.
Si las variables aleatorias X1 Y x2 tener funciones de distribución norte(metro 1
, 1)
Y norte(metro 2
, 2)
en consecuencia, entonces X1+ x2 tiene una distribución ![]() Por lo tanto, si las variables aleatorias X 1
,
X 2
,…,
xn norte(metro, )
, entonces su media aritmética
Por lo tanto, si las variables aleatorias X 1
,
X 2
,…,
xn norte(metro, )
, entonces su media aritmética
![]()
tiene una distribución norte(metro, ) . Estas propiedades de la distribución normal se utilizan constantemente en diversos métodos probabilísticos y estadísticos de toma de decisiones, en particular, en la regulación estadística de procesos tecnológicos y en el control de aceptación estadística basado en criterios cuantitativos.
Utilizando la distribución normal, se definen tres distribuciones que ahora se utilizan con frecuencia en el procesamiento de datos estadísticos.
Distribución (chi - cuadrado): distribución de una variable aleatoria
donde estan las variables aleatorias X 1 , X 2 ,…, xn independientes y tienen la misma distribución norte(0,1). En este caso, el número de términos, es decir norte, se denomina "número de grados de libertad" de la distribución chi-cuadrado.
Distribución t La t de Student es la distribución de una variable aleatoria.
donde estan las variables aleatorias Ud. Y X independiente, Ud. tiene una distribución normal estándar norte(0,1), y X– distribución chi – cuadrado c norte grados de libertad. Donde norte se denomina “número de grados de libertad” de la distribución de Student. Esta distribución fue introducida en 1908 por el estadístico inglés W. Gosset, que trabajaba en una fábrica de cerveza. En esta fábrica se utilizaban métodos probabilísticos y estadísticos para tomar decisiones económicas y técnicas, por lo que su dirección prohibió a V. Gosset publicar artículos científicos bajo su propio nombre. De esta manera se protegieron los secretos comerciales y el "know-how" en forma de métodos probabilísticos y estadísticos desarrollados por V. Gosset. Sin embargo, tuvo la oportunidad de publicar bajo el seudónimo de "Estudiante". La historia de Gosset-Student muestra que durante otros cien años los directivos en Gran Bretaña fueron conscientes de la mayor eficiencia económica de los métodos probabilístico-estadísticos de toma de decisiones.
La distribución de Fisher es la distribución de una variable aleatoria.
donde estan las variables aleatorias X1 Y x2 son independientes y tienen distribuciones chi-cuadrado con el número de grados de libertad k 1 Y k 2 respectivamente. Al mismo tiempo, la pareja (k 1 , k 2 ) – un par de “grados de libertad” de la distribución de Fisher, a saber, k 1 es el número de grados de libertad del numerador, y k 2 – número de grados de libertad del denominador. La distribución de la variable aleatoria F lleva el nombre del gran estadístico inglés R. Fisher (1890-1962), quien la utilizó activamente en sus trabajos.
Las expresiones para las funciones de distribución chi-cuadrado, Student y Fisher, sus densidades y características, así como tablas, se pueden encontrar en la literatura especializada (ver, por ejemplo,).
Como ya se señaló, las distribuciones normales se utilizan ahora con frecuencia en modelos probabilísticos en diversas áreas de aplicación. ¿Cuál es la razón por la que esta familia de distribuciones de dos parámetros está tan extendida? Se aclara mediante el siguiente teorema.
Teorema del límite central(para términos distribuidos de manera diferente). Dejar X 1 , X 2 ,…, xn,… - variables aleatorias independientes con expectativas matemáticas METRO(X 1 ), METRO(X 2 ),…, METRO(X n), ... y variaciones D(X 1 ), D(X 2 ),…, D(X n), ... respectivamente. Dejar
Entonces, si se cumplen ciertas condiciones que aseguran la pequeña contribución de cualquiera de los términos en ONU,
![]()
para cualquiera X.
No formularemos aquí las condiciones en cuestión. Se pueden encontrar en literatura especializada (ver, por ejemplo,). "La aclaración de las condiciones en las que opera el CPT es mérito de los destacados científicos rusos A.A. Markov (1857-1922) y, en particular, A.M. Lyapunov (1857-1918)".
El teorema del límite central muestra que en el caso en que el resultado de una medición (observación) se forma bajo la influencia de muchas causas, cada una de las cuales hace sólo una pequeña contribución, y el resultado total se determina aditivamente, es decir. además, entonces la distribución del resultado de la medición (observación) es cercana a la normalidad.
A veces se cree que para que la distribución sea normal basta que el resultado de la medición (observación) X Se forma bajo la influencia de muchas razones, cada una de las cuales tiene un pequeño impacto. Esto está mal. Lo que importa es cómo operan estas causas. Si es aditivo, entonces X tiene una distribución aproximadamente normal. Si multiplicativamente(es decir, las acciones de causas individuales se multiplican y no se suman), entonces la distribución X cerca no de lo normal, sino de lo llamado. logarítmicamente normal, es decir No X y log X tiene una distribución aproximadamente normal. Si no hay razón para creer que uno de estos dos mecanismos para la formación del resultado final está funcionando (o algún otro mecanismo bien definido), entonces sobre la distribución. X No se puede decir nada definitivo.
De lo anterior se deduce que en un problema aplicado específico, la normalidad de los resultados de las mediciones (observaciones), por regla general, no puede establecerse a partir de consideraciones generales, debe verificarse utilizando criterios estadísticos. O utilice métodos estadísticos no paramétricos que no se basen en suposiciones sobre la pertenencia de las funciones de distribución de los resultados de las mediciones (observaciones) a una u otra familia paramétrica.
Distribuciones continuas utilizadas en métodos probabilísticos y estadísticos de toma de decisiones. Además de la familia de distribuciones normales de cambio de escala, se utilizan ampliamente otras familias de distribuciones: distribuciones lognormales, exponenciales, Weibull-Gnedenko y gamma. Miremos a estas familias.
Valor aleatorio X tiene una distribución lognormal si la variable aleatoria Y= iniciar sesión X tiene una distribución normal. Entonces z= iniciar sesión X = 2,3026…Y también tiene una distribución normal norte(a 1 ,σ1), donde en X- logaritmo natural X. La densidad de la distribución lognormal es:

Del teorema del límite central se deduce que el producto X = X 1 X 2 … xn variables aleatorias positivas independientes X yo, i = 1, 2,…, norte, en general norte puede aproximarse mediante una distribución lognormal. En particular, el modelo multiplicativo de formación de salarios o ingresos lleva a recomendar aproximar las distribuciones de salarios e ingresos mediante leyes logarítmicamente normales. Para Rusia, esta recomendación resultó justificada: los datos estadísticos lo confirman.
Existen otros modelos probabilísticos que conducen a la ley lognormal. Un ejemplo clásico de este modelo lo dio A.N. Kolmogorov, quien, a partir de un sistema de postulados basado físicamente, llegó a la conclusión de que el tamaño de las partículas al triturar trozos de mineral, carbón, etc. en los molinos de bolas tienen una distribución lognormal.
Pasemos a otra familia de distribuciones, ampliamente utilizada en diversos métodos estadístico-probabilísticos de toma de decisiones y otras investigaciones aplicadas: la familia de distribuciones exponenciales. Comencemos con un modelo probabilístico que conduzca a tales distribuciones. Para hacer esto, considere el "flujo de eventos", es decir una secuencia de eventos que ocurren uno tras otro en ciertos momentos en el tiempo. Los ejemplos incluyen: flujo de llamadas en una central telefónica; flujo de fallas de equipos en la cadena tecnológica; flujo de fallas del producto durante las pruebas del producto; flujo de solicitudes de clientes a la sucursal bancaria; flujo de compradores que solicitan bienes y servicios, etc. En la teoría de los flujos de eventos, es válido un teorema similar al teorema del límite central, pero no se trata de la suma de variables aleatorias, sino de la suma de los flujos de eventos. Consideramos un flujo total compuesto por un gran número de flujos independientes, ninguno de los cuales tiene una influencia predominante sobre el flujo total. Por ejemplo, un flujo de llamadas que ingresa a una central telefónica se compone de un gran número de flujos de llamadas independientes que se originan en abonados individuales. Se ha demostrado que en el caso en que las características de los flujos no dependen del tiempo, el flujo total se describe completamente mediante un número: la intensidad del flujo. Para el flujo total, considere la variable aleatoria X- la duración del intervalo de tiempo entre eventos sucesivos. Su función de distribución tiene la forma
 (10)
(10)
Esta distribución se llama distribución exponencial porque la fórmula (10) involucra la función exponencial mi -λ X. El valor 1/λ es un parámetro de escala. A veces también se introduce un parámetro de cambio. Con, la distribución de una variable aleatoria se llama exponencial X + s, donde la distribución X viene dada por la fórmula (10).
Las distribuciones exponenciales son un caso especial de las llamadas. Distribuciones Weibull-Gnedenko. Llevan el nombre del ingeniero V. Weibull, quien introdujo estas distribuciones en la práctica de analizar los resultados de las pruebas de fatiga, y del matemático B.V. Gnedenko (1912-1995), que recibió tales distribuciones como límites al estudiar el máximo de los resultados de la prueba. Dejar X- una variable aleatoria que caracteriza la duración de la operación de un producto, sistema complejo, elemento (es decir, recurso, tiempo de operación hasta un estado límite, etc.), duración de la operación de una empresa o la vida de un ser vivo, etc. La intensidad del fracaso juega un papel importante.
![]() (11)
(11)
Dónde F(X) Y F(X) - función de distribución y densidad de una variable aleatoria X.
Describamos el comportamiento típico de la tasa de fracaso. Todo el intervalo de tiempo se puede dividir en tres períodos. En el primero de ellos la función λ(x) tiene valores altos y una clara tendencia a disminuir (la mayoría de las veces disminuye de forma monótona). Esto puede explicarse por la presencia en el lote de unidades de producto en cuestión con defectos evidentes y ocultos, que conducen a un fallo relativamente rápido de estas unidades de producto. El primer período se denomina “período de asentamiento” (o “asentamiento”). Esto es lo que suele cubrir el periodo de garantía.
Luego viene un período de funcionamiento normal, caracterizado por una tasa de fallos aproximadamente constante y relativamente baja. La naturaleza de las fallas durante este período es repentina (accidentes, errores del personal operativo, etc.) y no depende de la duración del funcionamiento de la unidad del producto.
Finalmente, el último período de funcionamiento es el período de envejecimiento y desgaste. La naturaleza de las fallas durante este período radica en cambios físicos, mecánicos y químicos irreversibles en los materiales, que conducen a un deterioro progresivo en la calidad de una unidad de producto y su falla final.
Cada período tiene su propio tipo de función. λ(x). Consideremos la clase de dependencias de poder.
λ(x) = λ0bxb -1 , (12)
Dónde λ 0 > 0 y b> 0: algunos parámetros numéricos. Valores b < 1, b= 0 y b> 1 corresponde al tipo de tasa de fallo durante los periodos de rodaje, funcionamiento normal y envejecimiento, respectivamente.
Relación (11) a una determinada tasa de fracaso λ(x)- ecuación diferencial para una función F(X). De la teoría ecuaciones diferenciales sigue eso
 (13)
(13)
Sustituyendo (12) en (13), obtenemos que
 (14)
(14)
La distribución dada por la fórmula (14) se denomina distribución de Weibull-Gnedenko. Porque el
entonces de la fórmula (14) se deduce que la cantidad A, dado por la fórmula (15), es un parámetro de escala. A veces también se introduce un parámetro de cambio, es decir Las funciones de distribución de Weibull-Gnedenko se denominan F(X - C), Dónde F(X) viene dada por la fórmula (14) para algunos λ 0 y b.
La densidad de distribución de Weibull-Gnedenko tiene la forma
 (16)
(16)
Dónde a> 0 - parámetro de escala, b> 0 - parámetro de formulario, Con- parámetro de cambio. En este caso, el parámetro A de la fórmula (16) está asociado con el parámetro λ 0 de la fórmula (14) por la relación especificada en la fórmula (15).
La distribución exponencial es un caso muy especial de la distribución de Weibull-Gnedenko, correspondiente al valor del parámetro de forma. b = 1.
La distribución de Weibull-Gnedenko también se utiliza para construir modelos probabilísticos de situaciones en las que el comportamiento de un objeto está determinado por el "eslabón más débil". Existe una analogía con una cadena, cuya seguridad está determinada por el eslabón que tiene menor resistencia. En otras palabras, dejemos X 1 , X 2 ,…, xn- variables aleatorias independientes distribuidas idénticamente,
X(1)=mín( X 1, X 2,…, X n), X(n)=máximo( X 1, X 2,…, X n).
En una serie de problemas aplicados, juegan un papel importante. X(1) Y X(norte) , en particular, al estudiar los valores máximos posibles ("registros") de determinados valores, por ejemplo, pagos de seguros o pérdidas por riesgos comerciales, al estudiar los límites de elasticidad y resistencia del acero, una serie de características de fiabilidad, etc. . Se muestra que para n grandes las distribuciones X(1) Y X(norte) , por regla general, están bien descritos mediante las distribuciones de Weibull-Gnedenko. Contribución fundamental al estudio de las distribuciones. X(1) Y X(norte) aportado por el matemático soviético B.V. Gnedenko. Los trabajos de V. Weibull, E. Gumbel, V. B. están dedicados al uso de los resultados obtenidos en economía, gestión, tecnología y otros campos. Nevzorova, E.M. Kudlaev y muchos otros especialistas.
Pasemos a la familia de distribuciones gamma. Se utilizan ampliamente en economía y gestión, teoría y práctica de confiabilidad y pruebas, en diversos campos de la tecnología, meteorología, etc. En particular, en muchas situaciones, la distribución gamma está sujeta a cantidades tales como la vida útil total del producto, la longitud de la cadena de partículas de polvo conductoras, el tiempo que el producto alcanza el estado límite durante la corrosión, el tiempo de funcionamiento hasta k-ésima negativa, k= 1, 2,…, etc. Esperanza de vida de los pacientes. enfermedades crónicas, el tiempo para lograr un determinado efecto durante el tratamiento en algunos casos tiene una distribución gamma. Esta distribución es más adecuada para describir la demanda en modelos económicos y matemáticos de gestión de inventarios (logística).
La densidad de distribución gamma tiene la forma
 (17)
(17)
La densidad de probabilidad en la fórmula (17) está determinada por tres parámetros a, b, C, Dónde a>0, b>0. Donde a es un parámetro de formulario, b- parámetro de escala y Con- parámetro de cambio. Factor 1/Γ(a) se está normalizando, se introdujo a
![]()
Aquí Γ(a)- uno de los utilizados en matemáticas funciones especiales, la llamada "función gamma", que da nombre a la distribución definida por la fórmula (17),

en fijo A La fórmula (17) especifica una familia de distribuciones de cambio de escala generada por una distribución con densidad.
 (18)
(18)
Una distribución de la forma (18) se denomina distribución gamma estándar. Se obtiene de la fórmula (17) en b= 1 y Con= 0.
Un caso especial de distribuciones gamma para A= 1 son distribuciones exponenciales (con λ = 1/b). con naturales A Y Con Las distribuciones gamma =0 se denominan distribuciones de Erlang. De los trabajos del científico danés K.A. Erlang (1878-1929), empleado de la Compañía Telefónica de Copenhague, que estudió en 1908-1922. El funcionamiento de las redes telefónicas comenzó el desarrollo de la teoría de las colas. Esta teoría se ocupa del modelado probabilístico y estadístico de sistemas en los que se atiende un flujo de solicitudes para tomar decisiones óptimas. Las distribuciones de Erlang se utilizan en las mismas áreas de aplicación en las que se utilizan las distribuciones exponenciales. Esto se basa en el siguiente hecho matemático: la suma de k variables aleatorias independientes distribuidas exponencialmente con los mismos parámetros λ y Con, tiene una distribución gamma con un parámetro de forma un =k, parámetro de escala b= 1/λ y parámetro de desplazamiento kc. En Con= 0 obtenemos la distribución de Erlang.
Si la variable aleatoria X tiene una distribución gamma con un parámetro de forma A tal que d = 2 a- número entero, b= 1 y Con= 0, entonces 2 X tiene una distribución chi-cuadrado con d grados de libertad.
Valor aleatorio X con distribución gvmma tiene las siguientes características:
Valor esperado M(X) =ab + C,
Diferencia D(X) = σ 2 = ab 2 ,
El coeficiente de variación.
Asimetría ![]()
Exceso ![]()
La distribución normal es un caso extremo de la distribución gamma. Más precisamente, sea Z una variable aleatoria que tiene una distribución gamma estándar dada por la fórmula (18). Entonces
![]()
para cualquier número real X, Dónde F(x)- función de distribución normal estándar norte(0,1).
En la investigación aplicada también se utilizan otras familias paramétricas de distribuciones, de las cuales las más famosas son el sistema de curvas de Pearson, las series de Edgeworth y Charlier. Aquí no se consideran.
Discreto distribuciones utilizadas en métodos probabilísticos y estadísticos de toma de decisiones. Las más utilizadas son tres familias de distribuciones discretas: binomial, hipergeométrica y de Poisson, así como algunas otras familias: geométrica, binomial negativa, multinomial, hipergeométrica negativa, etc.
Como ya se mencionó, la distribución binomial ocurre en ensayos independientes, en cada uno de los cuales con probabilidad R aparece el evento A. Si numero total pruebas norte dado, entonces el número de pruebas Y, en el que apareció el evento A, tiene una distribución binomial. Para una distribución binomial, la probabilidad de ser aceptada como variable aleatoria es Y valores y está determinado por la fórmula
![]()
Número de combinaciones de norte elementos por y, conocido de combinatoria. Para todos y, excepto 0, 1, 2,…, norte, tenemos PAG(Y= y)= 0. Distribución binomial con tamaño de muestra fijo norte está especificado por el parámetro pag, es decir. Las distribuciones binomiales forman una familia de un solo parámetro. Se utilizan en el análisis de datos de estudios de muestra, en particular, en el estudio de las preferencias de los consumidores, control selectivo de la calidad del producto según planes de control de una sola etapa, al realizar pruebas de poblaciones de individuos en demografía, sociología, medicina, biología, etc. .
Si Y 1 Y Y 2 - variables aleatorias binomiales independientes con el mismo parámetro pag 0 , determinado a partir de muestras con volúmenes norte 1 Y norte 2 en consecuencia, entonces Y 1 + Y 2 - variable aleatoria binomial que tiene distribución (19) con R = pag 0 Y norte = norte 1 + norte 2 . Esta observación amplía la aplicabilidad de la distribución binomial al permitir combinar los resultados de varios grupos de pruebas cuando hay motivos para creer que el mismo parámetro corresponde a todos estos grupos.
Las características de la distribución binomial se calcularon anteriormente:
METRO(Y) = notario público., D(Y) = notario público.( 1- pag).
En la sección "Eventos y probabilidades" se demuestra la ley de los grandes números para una variable aleatoria binomial:
![]()
para cualquiera . Utilizando el teorema del límite central, la ley de los grandes números se puede refinar indicando cuánto Y/ norte difiere de R.
Teorema de De Moivre-Laplace. Para cualquier número a y b, a< b, tenemos

Dónde F(X) es una función de distribución normal estándar con expectativa matemática 0 y varianza 1.
Para demostrarlo basta utilizar la representación Y en forma de una suma de variables aleatorias independientes correspondientes a los resultados de pruebas individuales, fórmulas para METRO(Y) Y D(Y) y el teorema del límite central.
Este teorema es para el caso R= ½ fue demostrado por el matemático inglés A. Moivre (1667-1754) en 1730. En la formulación anterior, fue demostrado en 1810 por el matemático francés Pierre Simon Laplace (1749 - 1827).
La distribución hipergeométrica ocurre durante el control selectivo de un conjunto finito de objetos de volumen N según un criterio alternativo. Cada objeto controlado se clasifica ya sea con el atributo A, o como si no tuviera esta característica. La distribución hipergeométrica tiene una variable aleatoria. Y, igual al numero objetos que tienen la característica A en una muestra aleatoria de volumen norte, Dónde norte< norte. Por ejemplo, número Y Unidades defectuosas de producto en una muestra aleatoria de volumen. norte del volumen del lote norte tiene una distribución hipergeométrica si norte< norte. Otro ejemplo es la lotería. deja la señal A El billete es señal de “ser ganador”. Sea el número total de boletos. norte, y alguna persona adquirió norte de ellos. Entonces el número de boletos ganadores de esta persona tiene una distribución hipergeométrica.
Para una distribución hipergeométrica, la probabilidad de que una variable aleatoria Y acepte el valor y tiene la forma
 (20)
(20)
Dónde D– el número de objetos que tienen el atributo A, en el conjunto de volumen considerado norte. Donde y toma valores de max(0, norte - (norte - D)) a min( norte, D), otras cosas y la probabilidad en la fórmula (20) es igual a 0. Por tanto, la distribución hipergeométrica está determinada por tres parámetros: volumen población norte, numero de objetos D en él, poseyendo la característica en cuestión A y tamaño de la muestra norte.
Muestreo de volumen aleatorio simple norte del volumen total norte Es una muestra obtenida como resultado de una selección aleatoria en la que cualquiera de los conjuntos de norte Los objetos tienen la misma probabilidad de ser seleccionados. Los métodos para seleccionar aleatoriamente muestras de encuestados (entrevistados) o unidades de bienes por pieza se analizan en los documentos instructivos, metodológicos y reglamentarios. Uno de los métodos de selección es el siguiente: los objetos se seleccionan uno de otro y, en cada paso, cada uno de los objetos restantes del conjunto tiene las mismas posibilidades de ser seleccionado. En la literatura, los términos “muestra aleatoria” y “muestra aleatoria sin retorno” también se utilizan para el tipo de muestras bajo consideración.
Dado que los volúmenes de la población (lote) norte y muestras norte generalmente se conocen, entonces el parámetro de la distribución hipergeométrica a estimar es D. En métodos estadísticos de gestión de la calidad del producto. D– normalmente el número de unidades defectuosas en un lote. La característica de distribución también es de interés. D/ norte– nivel de defectos.
Para distribución hipergeométrica
El último factor en la expresión de varianza es cercano a 1 si norte>10 norte. Si haces un reemplazo pag = D/ norte, luego, las expresiones para la expectativa matemática y la varianza de la distribución hipergeométrica se convertirán en expresiones para la expectativa matemática y la varianza de la distribución binomial. Esto no es una coincidencia. Se puede demostrar que

en norte>10 norte, Dónde pag = D/ norte. La relación límite es válida.
y esta relación limitante se puede utilizar cuando norte>10 norte.
La tercera distribución discreta más utilizada es la distribución de Poisson. La variable aleatoria Y tiene una distribución de Poisson si
![]() ,
,
donde λ es el parámetro de distribución de Poisson, y PAG(Y= y)= 0 para todos los demás y(para y=0 se designa 0! =1). Para distribución de Poisson
METRO(Y) = λ, D(Y) = λ.
Esta distribución lleva el nombre del matemático francés S. D. Poisson (1781-1840), quien la obtuvo por primera vez en 1837. La distribución de Poisson es el caso límite de la distribución binomial, cuando la probabilidad R la implementación del evento es pequeña, pero el número de pruebas norte genial y notario público.= λ. Más precisamente, la relación límite es válida
Por lo tanto, la distribución de Poisson (en la antigua terminología “ley de distribución”) a menudo también se denomina “ley de eventos raros”.
La distribución de Poisson se origina en la teoría del flujo de eventos (ver arriba). Se ha comprobado que para el flujo más simple con intensidad constante Λ, el número de eventos (llamadas) que ocurrieron durante el tiempo t, tiene una distribución de Poisson con parámetro λ = Λ t. Por lo tanto, la probabilidad de que durante el tiempo t no ocurrirá ningún evento, igual a mi - Λ t, es decir. la función de distribución de la duración del intervalo entre eventos es exponencial.
La distribución de Poisson se utiliza para analizar los resultados de encuestas de marketing por muestreo de consumidores, calcular las características operativas de los planes de control de aceptación estadística en el caso de valores pequeños del nivel de aceptación de defectos, para describir el número de averías de un producto estadísticamente controlado. proceso tecnológico por unidad de tiempo, el número de “requisitos de servicio” recibidos por unidad de tiempo en el sistema de colas, patrones estadísticos de accidentes y enfermedades raras, etc.
Descripción de otras familias paramétricas de distribuciones discretas y sus posibilidades. uso práctico son considerados en la literatura.
En algunos casos, por ejemplo, al estudiar precios, volúmenes de producción o tiempo total entre fallas en problemas de confiabilidad, las funciones de distribución son constantes en algunos intervalos, en los que los valores de las variables aleatorias estudiadas no pueden caer.
| Anterior |
3. La función de distribución es no decreciente: si entonces
4. Función de distribución izquierda continua: para cualquiera .
Nota. La última propiedad indica qué valores toma la función de distribución en los puntos de ruptura. A veces, la definición de la función de distribución se formula utilizando una desigualdad vaga: . En este caso se sustituye la continuidad por la izquierda por la continuidad por la derecha: cuando. Esto no cambia ninguna propiedad significativa de la función de distribución, por lo que esta pregunta es sólo terminológica.
Las propiedades 1-4 son características, es decir cualquier función que satisfaga estas propiedades es una función de distribución de alguna variable aleatoria.
La función de distribución define de forma única la distribución de probabilidad de una variable aleatoria. De hecho, es una forma universal y muy visual de describir esta distribución.
Cuanto más crece la función de distribución en un intervalo dado de la recta numérica, mayor es la probabilidad de que una variable aleatoria caiga en este intervalo. Si la probabilidad de caer en un intervalo es cero, entonces la función de distribución es constante.
En particular, la probabilidad de que una variable aleatoria tome un valor dado es igual al salto en la función de distribución en un punto dado:
.Si la función de distribución es continua en el punto , entonces la probabilidad de tomar este valor para una variable aleatoria es cero. En particular, si la función de distribución es continua en todo el eje numérico (en este caso, la distribución correspondiente se llama continuo), entonces la probabilidad de aceptar cualquier valor dado es cero.
De la definición de función de distribución se deduce que la probabilidad de que una variable aleatoria caiga en un intervalo cerrado por la izquierda y abierto por la derecha es igual a:
Usando esta fórmula y el método anterior para encontrar la probabilidad de llegar a cualquier punto dado, las probabilidades de que una variable aleatoria entre en intervalos de otros tipos se determinan fácilmente: , y . Además, mediante el teorema de extensión de la medida, podemos extender de forma única la medida a todos los conjuntos de Borel de la recta numérica. Para aplicar este teorema, es necesario demostrar que la medida así definida en intervalos es sigma-aditiva en ellos; al probar esto, las propiedades 1-4 se usan exactamente (en particular, la propiedad de continuidad izquierda 4, por lo que no se puede descartar).
Generando una variable aleatoria con una distribución dada
Consideremos una variable aleatoria que tiene una función de distribución. pretendamos que continuo. Considere la variable aleatoria
.Es fácil demostrar que entonces tendrá una distribución uniforme en el segmento.
Definición de una función de variables aleatorias. Función de argumento aleatorio discreto y sus características numéricas. Función de argumento aleatorio continuo y sus características numéricas. Funciones de dos argumentos aleatorios. Determinación de la función de distribución de probabilidad y densidad para una función de dos argumentos aleatorios.
Ley de distribución de probabilidad de una función de una variable aleatoria.
Al resolver problemas relacionados con la evaluación de la precisión del funcionamiento de varios sistemas automáticos, la precisión de la producción de elementos individuales de los sistemas, etc., a menudo es necesario considerar funciones de una o más variables aleatorias. Estas funciones también son variables aleatorias. Por tanto, a la hora de resolver problemas, es necesario conocer las leyes de distribución de las variables aleatorias que aparecen en el problema. En este caso, normalmente se conocen la ley de distribución del sistema de argumentos aleatorios y la dependencia funcional.
Surge así un problema que puede formularse de la siguiente manera.
Dado un sistema de variables aleatorias. (X_1,X_2,\ldots,X_n), cuya ley de distribución se conoce. Alguna variable aleatoria Y se considera en función de estas variables aleatorias:
Y=\varphi(X_1,X_2,\ldots,X_n).
Se requiere determinar la ley de distribución de la variable aleatoria Y, conociendo la forma de las funciones (6.1) y la ley de distribución conjunta de sus argumentos.
Consideremos el problema de la ley de distribución de una función de un argumento aleatorio.
Y=\varphi(X).
\begin(array)(|c|c|c|c|c|)\hline(X)&x_1&x_2&\cdots&x_n\\\hline(P)&p_1&p_2&\cdots&p_n\\\hline\end(array)
Entonces Y=\varphi(X) también es una variable aleatoria discreta con valores posibles. Si todos los valores y_1,y_2,\ldots,y_n son diferentes, entonces para cada k=1,2,\ldots,n los eventos \(X=x_k\) y \(Y=y_k=\varphi(x_k)\) Son identicos. Por eso,
P\(Y=y_k\)=P\(X=x_k\)=p_k
y la serie de distribución requerida tiene la forma
\begin(array)(|c|c|c|c|c|)\hline(Y)&y_1=\varphi(x_1)&y_2=\varphi(x_2)&\cdots&y_n=\varphi(x_n)\\\hline (P)&p_1&p_2&\cdots&p_n\\\hline\end(matriz)
Si entre los números y_1=\varphi(x_1),y_2=\varphi(x_2),\ldots,y_n=\varphi(x_n) hay valores idénticos, entonces a cada grupo de valores idénticos y_k=\varphi(x_k) se le debe asignar una columna en la tabla y se deben sumar las probabilidades correspondientes.
Para variables aleatorias continuas, el problema se plantea de la siguiente manera: conociendo la densidad de distribución f(x) de la variable aleatoria X, encuentre la densidad de distribución g(y) de la variable aleatoria Y=\varphi(X). Al resolver el problema, consideramos dos casos.
Supongamos primero que la función y=\varphi(x) es monótonamente creciente, continua y diferenciable en el intervalo (a;b) en el que todos valores posibles Valores X. Entonces existe la función inversa x=\psi(y), aunque también es monótonamente creciente, continua y diferenciable. En este caso obtenemos
G(y)=f\bigl(\psi(y)\bigr)\cdot |\psi"(y)|.
Ejemplo 1. Variable aleatoria X distribuida con densidad
F(x)=\frac(1)(\sqrt(2\pi))e^(-x^2/2)
Encuentre la ley de distribución de la variable aleatoria Y asociada al valor X por la dependencia Y=X^3.
Solución. Dado que la función y=x^3 es monótona en el intervalo (-\infty;+\infty), podemos aplicar la fórmula (6.2). Función inversa en relación a la función \varphi(x)=x^3 existe \psi(y)=\sqrt(y) , su derivada \psi"(y)=\frac(1)(3\sqrt(y^2)). Por eso,
G(y)=\frac(1)(3\sqrt(2\pi))e^(-\sqrt(y^2)/2)\frac(1)(\sqrt(y^2))
Consideremos el caso de una función no monótona. Sea la función y=\varphi(x) tal que la función inversa x=\psi(y) sea ambigua, es decir, un valor de y corresponde a varios valores del argumento x, que denotamos x_1=\psi_1(y),x_2=\psi_2(y),\ldots,x_n=\psi_n(y), donde n es el número de secciones en las que la función y=\varphi(x) cambia monótonamente. Entonces
G(y)=\sum\limits_(k=1)^(n)f\bigl(\psi_k(y)\bigr)\cdot |\psi"_k(y)|.
Ejemplo 2. En las condiciones del ejemplo 1, encuentre la distribución de la variable aleatoria Y=X^2.
Solución. La función inversa x=\psi(y) es ambigua. Un valor del argumento y corresponde a dos valores de la función x
Aplicando la fórmula (6.3), obtenemos:
\begin(reunidos)g(y)=f(\psi_1(y))|\psi"_1(y)|+f(\psi_2(y))|\psi"_2(y)|=\\\\ =\frac(1)(\sqrt(2\pi))\,e^(-\left(-\sqrt(y^2)\right)^2/2)\!\left|-\frac(1 )(2\sqrt(y))\right|+\frac(1)(\sqrt(2\pi))\,e^(-\left(\sqrt(y^2)\right)^2/2 )\!\left|\frac(1)(2\sqrt(y))\right|=\frac(1)(\sqrt(2\pi(y)))\,e^(-y/2) .\end(reunidos)
Ley de distribución de una función de dos variables aleatorias.
Sea la variable aleatoria Y una función de dos variables aleatorias que forman el sistema (X_1;X_2), es decir Y=\varphi(X_1;X_2). La tarea consiste en encontrar la distribución de la variable aleatoria Y utilizando la distribución conocida del sistema (X_1;X_2).
Sea f(x_1;x_2) la densidad de distribución del sistema de variables aleatorias (X_1;X_2). Introduzcamos en consideración una nueva cantidad Y_1 igual a X_1 y consideremos el sistema de ecuaciones
Supondremos que este sistema tiene solución única con respecto a x_1,x_2
y satisface las condiciones de diferenciabilidad.
Densidad de distribución de la variable aleatoria Y
G_1(y)=\int\limits_(-\infty)^(+\infty)f(x_1;\psi(y;x_1))\!\left|\frac(\partial\psi(y;x_1)) (\partial(y))\right|dx_1.
Tenga en cuenta que el razonamiento no cambia si el nuevo valor introducido Y_1 se establece en X_2.
Expectativa matemática de una función de variables aleatorias.
En la práctica, a menudo hay casos en los que no existe una necesidad particular de determinar completamente la ley de distribución de una función de variables aleatorias, sino que basta con indicar sus características numéricas. Así, surge el problema de determinar las características numéricas de funciones de variables aleatorias además de las leyes de distribución de estas funciones.
Sea la variable aleatoria Y una función del argumento aleatorio X con una ley de distribución dada
Y=\varphi(X).
Se requiere, sin encontrar la ley de distribución de la cantidad Y, determinar su esperanza matemática.
M(Y)=M[\varphi(X)].
Sea X una variable aleatoria discreta que tiene una serie de distribución.
\begin(array)(|c|c|c|c|c|)\hline(x_i)&x_1&x_2&\cdots&x_n\\\hline(p_i)&p_1&p_2&\cdots&p_n\\\hline\end(array)
Hagamos una tabla de los valores del valor Y y las probabilidades de estos valores:
\begin(array)(|c|c|c|c|c|)\hline(y_i=\varphi(x_i))&y_1=\varphi(x_1)&y_2=\varphi(x_2)&\cdots&y_n=\varphi( x_n)\\\hline(p_i)&p_1&p_2&\cdots&p_n\\\hline\end(array)
Esta tabla no es una serie de la distribución de la variable aleatoria Y, ya que en el caso general algunos de los valores pueden coincidir entre sí y los valores de la fila superior no necesariamente están en orden ascendente. Sin embargo, la expectativa matemática de la variable aleatoria Y puede determinarse mediante la fórmula
M[\varphi(X)]=\sum\limits_(i=1)^(n)\varphi(x_i)p_i,
ya que el valor determinado por la fórmula (6.4) no puede cambiar debido a que bajo el signo de suma algunos términos se combinarán de antemano y se cambiará el orden de los términos.
La fórmula (6.4) no contiene explícitamente la ley de distribución de la función \varphi(X) en sí, sino que contiene sólo la ley de distribución del argumento X. Así, para determinar la expectativa matemática de la función Y=\varphi(X), no es en absoluto necesario conocer la ley de distribución de la función \varphi(X), sino más bien conocer la ley de distribución del argumento X.
Para una variable aleatoria continua, la expectativa matemática se calcula usando la fórmula
M[\varphi(X)]=\int\limits_(-\infty)^(+\infty)\varphi(x)f(x)\,dx,
donde f(x) es la densidad de distribución de probabilidad de la variable aleatoria X.
Consideremos casos en los que, para encontrar la expectativa matemática de una función de argumentos aleatorios, no se requiere conocimiento ni siquiera de las leyes de distribución de argumentos, sino que basta con conocer solo algunas de sus características numéricas. Formulemos estos casos en forma de teoremas.
Teorema 6.1. La expectativa matemática de la suma de dos variables aleatorias dependientes e independientes es igual a la suma de las expectativas matemáticas de estas variables:
M(X+Y)=M(X)+M(Y).
Teorema 6.2. La expectativa matemática del producto de dos variables aleatorias es igual al producto de sus expectativas matemáticas más el momento de correlación:
M(XY)=M(X)M(Y)+\mu_(xy).
Corolario 6.1. La expectativa matemática del producto de dos variables aleatorias no correlacionadas es igual al producto de sus expectativas matemáticas.
Corolario 6.2. La expectativa matemática del producto de dos variables aleatorias independientes es igual al producto de sus expectativas matemáticas.
Varianza de una función de variables aleatorias.
Por definición de dispersión tenemos D[Y]=M[(Y-M(Y))^2].. Por eso,
D[\varphi(x)]=M[(\varphi(x)-M(\varphi(x)))^2], Dónde .
Presentamos las fórmulas de cálculo sólo para el caso de argumentos aleatorios continuos. Para una función de un argumento aleatorio Y=\varphi(X), la varianza se expresa mediante la fórmula
D[\varphi(x)]=\int\limits_(-\infty)^(+\infty)(\varphi(x)-M(\varphi(x)))^2f(x)\,dx,
Dónde M(\varphi(x))=M[\varphi(X)]- expectativa matemática de la función \varphi(X) ; f(x) - densidad de distribución del valor X.
La fórmula (6.5) se puede sustituir por la siguiente:
D[\varphi(x)]=\int\limits_(-\infty)^(+\infty)\varphi^2(x)f(x)\,dx-M^2(X)
Consideremos teoremas de dispersión, que juegan un papel importante en la teoría de la probabilidad y sus aplicaciones.
Teorema 6.3. La varianza de la suma de variables aleatorias es igual a la suma de las varianzas de estas cantidades más la suma duplicada de los momentos de correlación de cada uno de los sumandos con todos los siguientes:
D\!\left[\sum\limits_(i=1)^(n)X_i\right]=\sum\limits_(i=1)^(n)D+2\sum\limits_(i Corolario 6.3. La varianza de la suma de variables aleatorias no correlacionadas es igual a la suma de las varianzas de los términos: D\!\left[\sum\limits_(i=1)^(n)X_i\right]=\sum\limits_(i=1)^(n)D\mu_(y_1y_2)= M(Y_1Y_2)-M(Y_1)M(Y_2). \mu_(y_1y_2)=M(\varphi_1(X)\varphi_2(X))-M(\varphi_1(X))M(\varphi_2(X)). Veamos los principales propiedades del momento de correlación y coeficiente de correlación. Propiedad 1. Agregar constantes a variables aleatorias no cambia el momento de correlación ni el coeficiente de correlación. Propiedad 2. Para cualquier variable aleatoria X e Y, el valor absoluto del momento de correlación no excede la media geométrica de las varianzas de estos valores: |\mu_(xy)|\leqslant\sqrt(D[X]\cdot D[Y])=\sigma_x\cdot \sigma_y, Variable aleatoria
es una variable que puede tomar ciertos valores dependiendo de diversas circunstancias, y La variable aleatoria se llama continua.
, si puede tomar cualquier valor de cualquier intervalo limitado o ilimitado. Para una variable aleatoria continua, es imposible indicar todos los valores posibles, por lo que designamos intervalos de estos valores que están asociados con ciertas probabilidades. Ejemplos de variables aleatorias continuas incluyen: el diámetro de una pieza que se está rectificando a un tamaño determinado, la altura de una persona, el alcance de vuelo de un proyectil, etc. Dado que para variables aleatorias continuas la función F(X), A diferencia de variables aleatorias discretas, no tiene saltos en ninguna parte, entonces la probabilidad de cualquier valor individual de una variable aleatoria continua es cero. Esto significa que para una variable aleatoria continua no tiene sentido hablar de la distribución de probabilidad entre sus valores: cada uno de ellos tiene probabilidad cero. Sin embargo, en cierto sentido, entre los valores de una variable aleatoria continua los hay “más y menos probables”. Por ejemplo, casi nadie dudaría de que el valor de una variable aleatoria (la altura de una persona encontrada al azar - 170 cm) es más probable que 220 cm, aunque ambos valores pueden ocurrir en la práctica. Como ley de distribución que tiene sentido sólo para variables aleatorias continuas, se introduce el concepto de densidad de distribución o densidad de probabilidad. Abordémoslo comparando el significado de la función de distribución para una variable aleatoria continua y una variable aleatoria discreta. Entonces, la función de distribución de una variable aleatoria (tanto discreta como continua) o función integral Se llama función que determina la probabilidad de que el valor de una variable aleatoria. X menor o igual al valor límite X. Para una variable aleatoria discreta en los puntos de sus valores X1
, X 2
, ..., X i,... masas de probabilidades están concentradas pag1
, pag 2
, ..., pag i,..., y la suma de todas las masas es igual a 1. Transferimos esta interpretación al caso de una variable aleatoria continua. Imaginemos que una masa igual a 1 no se concentra en puntos individuales, sino que se “mancha” continuamente a lo largo del eje de abscisas. Oh con cierta densidad desigual. Probabilidad de que una variable aleatoria caiga en cualquier área Δ X se interpretará como la masa por sección y la densidad promedio en esa sección como la relación entre masa y longitud. Acabamos de introducir un concepto importante en la teoría de la probabilidad: la densidad de distribución. Densidad de probabilidad F(X) de una variable aleatoria continua es la derivada de su función de distribución: Conociendo la función de densidad, se puede encontrar la probabilidad de que el valor de una variable aleatoria continua pertenezca al intervalo cerrado [ a; b]: la probabilidad de que una variable aleatoria continua X tomará cualquier valor del intervalo [ a; b], es igual a una cierta integral de su densidad de probabilidad que va desde a antes b: En este caso, la fórmula general de la función. F(X) distribución de probabilidad de una variable aleatoria continua, que se puede utilizar si se conoce la función de densidad F(X)
: El gráfico de densidad de probabilidad de una variable aleatoria continua se llama curva de distribución (figura siguiente). Área de una figura (sombreada en la figura) delimitada por una curva, líneas rectas dibujadas desde puntos a Y b perpendicular al eje x, y el eje Oh, muestra gráficamente la probabilidad de que el valor de una variable aleatoria continua X está dentro del rango de a antes b. 1. La probabilidad de que una variable aleatoria tome cualquier valor del intervalo (y el área de la figura que está limitada por la gráfica de la función F(X) y eje Oh) es igual a uno: 2. La función de densidad de probabilidad no puede tomar valores negativos: y fuera de la existencia de la distribución su valor es cero Densidad de distribución F(X), así como la función de distribución. F(X), es una de las formas de la ley de distribución, pero a diferencia de la función de distribución, no es universal: la densidad de distribución existe sólo para variables aleatorias continuas. Mencionemos los dos tipos de distribución de una variable aleatoria continua más importantes en la práctica. Si la función de densidad de distribución F(X) variable aleatoria continua en algún intervalo finito [ a; b] toma un valor constante C, y fuera del intervalo toma un valor igual a cero, entonces esto la distribución se llama uniforme . Si la gráfica de la función de densidad de distribución es simétrica respecto al centro, los valores medios se concentran cerca del centro, y alejándose del centro se recogen los más diferentes a la media (la gráfica de la función se asemeja a una sección de una campana), entonces esto la distribución se llama normal . Ejemplo 1. Se conoce la función de distribución de probabilidad de una variable aleatoria continua: Encontrar función F(X) densidad de probabilidad de una variable aleatoria continua. Construya gráficas de ambas funciones. Encuentre la probabilidad de que una variable aleatoria continua tome cualquier valor en el intervalo de 4 a 8: . Solución. Obtenemos la función de densidad de probabilidad encontrando la derivada de la función de distribución de probabilidad: Gráfica de una función F(X) - parábola: Gráfica de una función F(X) - derecho: Encontremos la probabilidad de que una variable aleatoria continua tome cualquier valor en el rango de 4 a 8: Ejemplo 2. La función de densidad de probabilidad de una variable aleatoria continua viene dada por: Calcular coeficiente C. Encontrar función F(X) distribución de probabilidad de una variable aleatoria continua. Construya gráficas de ambas funciones. Encuentre la probabilidad de que una variable aleatoria continua tome cualquier valor en el rango de 0 a 5: . Solución. Coeficiente C encontramos, usando la propiedad 1 de la función de densidad de probabilidad: Por tanto, la función de densidad de probabilidad de una variable aleatoria continua es: Integrando encontramos la función F(X) distribuciones de probabilidad. Si X < 0
, то
F(X) = 0 . Si 0< X < 10
, то X> 10, entonces F(X) = 1
. De este modo, registro completo funciones de distribución de probabilidad: Gráfica de una función F(X)
: Gráfica de una función F(X)
: Encontremos la probabilidad de que una variable aleatoria continua tome cualquier valor en el rango de 0 a 5: Ejemplo 3. Densidad de probabilidad de una variable aleatoria continua X está dada por la igualdad , y . encontrar coeficiente A, la probabilidad de que una variable aleatoria continua X tomará cualquier valor del intervalo ]0, 5[, la función de distribución de una variable aleatoria continua X. Solución. Por condición llegamos a la igualdad. Por tanto, de dónde. Entonces, Ahora encontramos la probabilidad de que una variable aleatoria continua X tomará cualquier valor del intervalo ]0, 5[: Ahora obtenemos la función de distribución de esta variable aleatoria: Ejemplo 4. Encuentre la densidad de probabilidad de una variable aleatoria continua X, que toma sólo valores no negativos, y su función de distribución
es decir, el momento de correlación de dos funciones de variables aleatorias es igual a la expectativa matemática del producto de estas funciones menos el producto de las expectativas matemáticas. Función de distribución de una variable aleatoria continua y densidad de probabilidad.
![]() .
.
![]()
![]() .
.![]() .
.
Propiedades de la función de densidad de probabilidad de una variable aleatoria continua





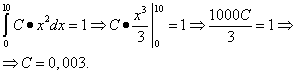
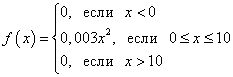
![]() .
.


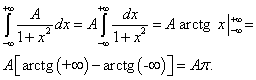
![]() .
.

![]() .
.

