Subiectul nr. 11
În practică, pentru a specifica variabile aleatoare vedere generala se foloseşte de obicei funcţia de distribuţie.
Probabilitatea ca valoare aleatorie X va lua o anumită valoare x 0, exprimată prin funcția de distribuție conform formulei
R (X = x 0) = F(x 0 +0) – F(x 0).(3)
În special, dacă în punctul x = x 0 funcția F(x) este continuă, atunci
R (X = x 0) =0.
Valoare aleatoare X cu distributie p(A) se numește discretă dacă există o mulțime finită sau numărabilă W pe dreapta numerică astfel încât R(W,) = 1.
Fie W = ( x 1 , x 2 ,…)Și p i= p({x i}) = p(X = x i), i= 1,2,….Apoi pentru orice set Borel A probabilitate p(A) este determinată în mod unic de formulă
Introducerea acestei formule A = (x i / x i< x}, x Î R , obținem formula funcției de distribuție F(x) variabilă aleatoare discretă X:
F(x) = p(X < X) =. (5)
Graficul unei funcții F(x) este o linie în trepte. Funcția saltă F(x) la puncte x = x 1, x 2…(x 1
Exemplul 1: Găsiți funcția de distribuție
variabila aleatoare discreta x din Exemplul 1§ 13.
Folosind funcția de distribuție, calculați
probabilitatea evenimentelor: x< 3, 1 £ x < 4, 1 £ x £ 3.

|
|
obţinut la § 13, iar formula (5), obţinem
functie de distributie:

Conform formulei (1) Р(x< 3) = F(3) = 0,1808; по формуле (2)
p(1 £ x< 4) = F (4) – F(1) = 0,5904 – 0,0016 = 0,5888;
p (1 £ x £ 3) = p (1 £ x<3) + p(x = 3) = F(3) – F(1) + F(3+0) – F(3) =
F(3+0) – F(1) = 0,5904 – 0,0016 = 0,5888.
Exemplul 2. Dată o funcție

Este funcția F(x) funcția de distribuție a unei variabile aleatoare? Dacă răspunsul este da, găsiți ![]() . Desenați un grafic al funcției F(x).
. Desenați un grafic al funcției F(x).
Soluţie. Pentru ca o funcție predeterminată F(x) să fie o funcție de distribuție a unei variabile aleatoare x, este necesar și suficient să se îndeplinească următoarele condiții (proprietăți caracteristice ale funcției de distribuție):
1.  F(x) este o funcție nedescrescătoare.
F(x) este o funcție nedescrescătoare.
3. Pentru orice x О R F( X– 0) = F( X).
Pentru o funcție dată F(x), execuție
aceste conditii sunt evidente. Mijloace,
F(x) – funcție de distribuție.
Probabilitate  calcula prin
calcula prin
formula (2):
Graficul funcției F( X) este prezentată în Figura 13.
Exemplul 3. Fie F 1 ( X) și F 2 ( X) – funcții de distribuție a variabilelor aleatoare X 1 și X 2 respectiv, A 1 și A 2 sunt numere nenegative a căror sumă este 1.
Demonstrați că F( X) = A 1 F 1 ( X) + A 2 F 2 ( X) este funcția de distribuție a unei variabile aleatoare X.
Soluţie. 1) Deoarece F 1 ( X) și F 2 ( X) sunt funcţii nedescrescătoare şi A 1 ³ 0, A 2 ³ 0, atunci A 1 F 1 ( X) Și A 2 F 2 ( X) sunt nedescrescătoare, prin urmare suma lor F( X) este, de asemenea, nedescrescătoare.
3) Pentru orice x О R F( X - 0) = A 1 F 1 ( X - 0) + A 2 F 2 ( X - 0)= A 1 F 1 ( X) + A 2 F 2 ( X) = F( X).
Exemplul 4. Dată o funcție

Este F(x) funcția de distribuție a unei variabile aleatoare?
Soluţie. Este ușor de observat că F(1) = 0,2 > 0,11 = F(1,1). Prin urmare, F( X) nu este nedescrescătoare și, prin urmare, nu este o funcție de distribuție a unei variabile aleatoare. Rețineți că celelalte două proprietăți sunt valabile pentru această funcție.
Sarcina de testare nr. 11
1. Variabilă aleatoare discretă X
X) și, folosindu-l, găsiți probabilitățile evenimentelor: a) –2 £ X < 1; б) ½X½£ 2. Trasează un grafic al funcției de distribuție.
3. Variabilă aleatoare discretă X dat de tabelul de distribuție:
| x i | |||||
| p i | 0,05 | 0,2 | 0,3 | 0,35 | 0,1 |
Găsiți funcția de distribuție F( X) și găsiți probabilitățile următoarelor evenimente: a) X < 2; б) 1 £ X < 4; в) 1 £ X 4 GBP; d) 1< X 4 GBP; d) X = 2,5.
4. Aflați funcția de distribuție a unei variabile aleatoare discrete X, egal cu numărul de puncte aruncate în timpul unei aruncări a zarului. Folosind funcția de distribuție, găsiți probabilitatea de a obține cel puțin 5 puncte.
5. Se efectuează teste consecutive a 5 dispozitive pentru fiabilitate. Fiecare dispozitiv ulterior este testat numai dacă cel anterior s-a dovedit a fi fiabil. Creați un tabel de distribuție și găsiți funcția de distribuție pentru numărul aleatoriu de teste ale dispozitivelor dacă probabilitatea de a trece testele pentru fiecare dispozitiv este 0,9.
6. Este dată funcția de distribuție a unei variabile aleatoare discrete X:

a) Aflați probabilitatea evenimentului 1 £ X 3 lire sterline.
b) Aflați tabelul de distribuție a variabilei aleatoare X.
7. Este dată funcția de distribuție a unei variabile aleatoare discrete X:

Faceți un tabel cu distribuția acestei variabile aleatoare.
8. Aruncarea monedelor n o singura data. Creați un tabel de distribuție și găsiți funcția de distribuție pentru numărul de apariții ale stemei. Trasează funcția de distribuție la n = 5.
9. Se aruncă moneda până când stema se ridică. Creați un tabel de distribuție și găsiți funcția de distribuție pentru numărul de apariții ale unei cifre.
10. Lunetistul trage în țintă până la prima lovitură. Probabilitatea unei rateuri pentru o singură lovitură este egală cu R. Găsiți funcția de distribuție a numărului de rateuri.
1.2.4. Variabile aleatoare și distribuțiile lor
Distribuții ale variabilelor aleatoare și funcții de distribuție. Distribuția unei variabile aleatoare numerice este o funcție care determină în mod unic probabilitatea ca variabila aleatoare să ia o valoare dată sau să aparțină unui interval dat.
Prima este dacă variabila aleatoare ia un număr finit de valori. Atunci distribuția este dată de funcție P(X = x), atribuirea fiecărei valori posibile X variabilă aleatorie X probabilitatea ca X = x.
Al doilea este dacă variabila aleatoare ia infinit de valori. Acest lucru este posibil numai atunci când spațiul probabilistic pe care este definită variabila aleatoare constă dintr-un număr infinit de evenimente elementare. Atunci distribuția este dată de un set de probabilități P(a <
X
P(a <
X
Această relație arată că atât distribuția poate fi calculată din funcția de distribuție, cât și, invers, funcția de distribuție poate fi calculată din distribuție.
Folosit în probabilism metode statistice luarea deciziilor și altele cercetare aplicată Funcțiile de distribuție sunt fie discrete, fie continue sau combinații ale acestora.
Funcțiile de distribuție discretă corespund variabilelor aleatoare discrete care iau un număr finit de valori sau valori dintr-o mulțime ale cărei elemente pot fi numerotate prin numere naturale (astfel de mulțimi sunt numite numărabile în matematică). Graficul lor arată ca o scară în trepte (Fig. 1).
Exemplul 1. Număr X articolele defecte dintr-un lot iau o valoare de 0 cu o probabilitate de 0,3, o valoare de 1 cu o probabilitate de 0,4, o valoare de 2 cu o probabilitate de 0,2 și o valoare de 3 cu o probabilitate de 0,1. Graficul funcției de distribuție a unei variabile aleatoare X prezentat în Fig. 1.
Fig.1. Graficul funcției de distribuție a numărului de produse defecte.
Funcțiile de distribuție continuă nu au salturi. Ele cresc monoton pe măsură ce argumentul crește - de la 0 la 1 la . Variabilele aleatoare care au funcții de distribuție continuă se numesc continue.
Funcțiile de distribuție continuă utilizate în metodele decizionale probabilistic-statistice au derivate. Prima derivată f(x) functii de distributie F(x) se numește densitate de probabilitate,
Folosind densitatea de probabilitate, puteți determina funcția de distribuție:
![]()
Pentru orice funcție de distribuție
Proprietățile enumerate ale funcțiilor de distribuție sunt utilizate în mod constant în metodele probabilistice și statistice de luare a deciziilor. În special, ultima egalitate implică o formă specifică de constante în formulele pentru densitățile de probabilitate considerate mai jos.
Exemplul 2. Următoarea funcție de distribuție este adesea folosită:
 (1)
(1)
Unde AȘi b– unele numere, A . Să găsim densitatea de probabilitate a acestei funcții de distribuție:

(la puncte x = aȘi x = b derivata unei functii F(x) nu exista).
O variabilă aleatoare cu funcție de distribuție (1) se numește „distribuită uniform pe intervalul [ A; b]».
Funcțiile de distribuție mixte apar, în special, atunci când observațiile se opresc la un moment dat. De exemplu, atunci când se analizează datele statistice obținute din utilizarea planurilor de testare a fiabilității care prevăd încetarea testării după o anumită perioadă. Sau la analiza datelor despre produse tehnice care necesitau reparații în garanție.
Exemplul 3. Să fie, de exemplu, durata de viață a unui bec electric o variabilă aleatorie cu funcție de distribuție F(t), iar testul se efectuează până când becul se defectează, dacă aceasta are loc în mai puțin de 100 de ore de la începutul testului, sau până când t 0= 100 de ore. Lăsa G(t)– functie de distributie a timpului de functionare al becului in stare buna in timpul acestei incercari. Apoi

Funcţie G(t) are un salt la un punct t 0, deoarece variabila aleatoare corespunzătoare ia valoarea t 0 cu probabilitate 1- F(t 0)> 0.
Caracteristicile variabilelor aleatoare.În metodele probabilistic-statistice de luare a deciziilor se folosesc o serie de caracteristici ale variabilelor aleatoare, exprimate prin funcții de distribuție și densități de probabilitate.
Când se descrie diferențierea veniturilor, când se găsesc limite de încredere pentru parametrii distribuțiilor variabilelor aleatoare și în multe alte cazuri, se folosește un concept precum „quantila de ordin”. R", unde 0< p < 1 (обозначается x p). Comandă cuantilă R– valoarea unei variabile aleatoare pentru care funcția de distribuție ia valoarea R sau există un „salt” de la o valoare mai mică R la o valoare mai mare R(Fig. 2). Se poate întâmpla ca această condiție să fie îndeplinită pentru toate valorile lui x aparținând acestui interval (adică funcția de distribuție este constantă pe acest interval și este egală cu R). Apoi fiecare astfel de valoare este numită „cuantilă de ordine” R" Pentru funcțiile de distribuție continuă, de regulă, există o singură cuantilă x p Ordin R(Fig. 2) și
F(x p) = p. (2)

Fig.2. Definiţia quantile x p Ordin R.
Exemplul 4. Să găsim cuantila x p Ordin R pentru funcția de distribuție F(x) din (1).
La 0< p < 1 квантиль x p se găsește din ecuație
acestea. x p = a + p(b – a) = a( 1- p) +bp. La p= 0 oricare X < A este o cuantilă de ordine p= 0. Cuantila de ordin p= 1 este orice număr X > b.
Pentru distribuțiile discrete, de regulă, nu există x p, care satisface ecuația (2). Mai precis, dacă distribuția unei variabile aleatoare este dată în Tabelul 1, unde x 1< x 2 < … < x k , apoi egalitatea (2), considerată ca o ecuație în raport cu x p, are solutii doar pt k valorile p, și anume,
p = p 1 ,
p = p 1 + p 2 ,
p = p 1 + p 2 + p 3 ,
p = p 1 + p 2 + …+ p m, 3 < m < k,
p = p 1 + p 2 + … + p k.
Tabelul 1.
Distribuția unei variabile aleatoare discrete
Pentru cei enumerati k valori de probabilitate p soluţie x p ecuația (2) nu este unică, și anume,
F(x) = p 1 + p 2 + … + p m
pentru toți X astfel încât x m< x < x m+1. Acestea. x p – orice număr din interval (x m; x m+1). Pentru toți ceilalți R din intervalul (0;1), neinclus în lista (3), există un „salt” de la o valoare mai mică R la o valoare mai mare R. Și anume dacă
p 1 + p 2 + … + p m
Acea x p = x m+1.
Proprietatea considerată a distribuțiilor discrete creează dificultăți semnificative la tabelarea și utilizarea unor astfel de distribuții, deoarece este imposibil să se mențină cu exactitate valorile numerice tipice ale caracteristicilor distribuției. În special, acest lucru este valabil pentru valorile critice și nivelurile de semnificație ale testelor statistice neparametrice (a se vedea mai jos), deoarece distribuțiile statisticilor acestor teste sunt discrete.
Ordinea cuantilelor este de mare importanță în statistică R= ½. Se numește mediană (variabilă aleatoare X sau funcția sa de distribuție F(x)) si este desemnat Eu (X).În geometrie există conceptul de „mediană” - o linie dreaptă care trece prin vârful unui triunghi și își împarte latura opusă în jumătate. În statistica matematică, mediana împarte în jumătate nu latura triunghiului, ci distribuția unei variabile aleatoare: egalitatea F(x 0,5)= 0,5 înseamnă că probabilitatea de a ajunge la stânga x 0,5și probabilitatea de a ajunge la dreapta x 0,5(sau direct la x 0,5) sunt egale între ele și egale cu ½, adică
P(X < X 0,5) = P(X > X 0,5) = ½.
Mediana indică „centrul” distribuției. Din punctul de vedere al unuia dintre conceptele moderne - teoria procedurilor statistice stabile - mediana este o caracteristică mai bună a unei variabile aleatoare decât valorea estimata. Când se prelucrează rezultatele măsurătorilor pe o scară ordinală (vezi capitolul despre teoria măsurării), mediana poate fi folosită, dar așteptările matematice nu.
O caracteristică a unei variabile aleatoare, cum ar fi modul, are o semnificație clară - valoarea (sau valorile) unei variabile aleatoare corespunzătoare maximului local al densității de probabilitate pentru o variabilă aleatoare continuă sau maximului local al probabilității pentru o variabilă aleatoare discretă .
Dacă x 0– modul unei variabile aleatoare cu densitate f(x), apoi, după cum se știe din calculul diferențial, .
O variabilă aleatoare poate avea mai multe moduri. Deci, pentru distribuția uniformă (1) fiecare punct X astfel încât A< x < b , este moda. Cu toate acestea, aceasta este o excepție. Majoritatea variabilelor aleatoare utilizate în metodele statistice probabilistice de luare a deciziilor și alte cercetări aplicate au un singur mod. Variabilele aleatoare, densitățile, distribuțiile care au un singur mod sunt numite unimodale.
Așteptările matematice pentru variabile aleatoare discrete cu un număr finit de valori sunt discutate în capitolul „Evenimente și probabilități”. Pentru o variabilă aleatoare continuă X valorea estimata M(X) satisface egalitatea
![]()
care este un analog al formulei (5) din afirmația 2 din capitolul „Evenimente și probabilități”.
Exemplul 5. Așteptări pentru o variabilă aleatoare distribuită uniform X egală
Pentru variabilele aleatoare luate în considerare în acest capitol, sunt adevărate toate acele proprietăți ale așteptărilor și varianțelor matematice care au fost luate în considerare mai devreme pentru variabile aleatoare discrete cu un număr finit de valori. Cu toate acestea, nu oferim dovezi ale acestor proprietăți, deoarece ele necesită aprofundarea subtilităților matematice, ceea ce nu este necesar pentru înțelegerea și aplicarea calificată a metodelor probabilistic-statistice de luare a deciziilor.
Cometariu. Acest manual evită în mod deliberat subtilitățile matematice asociate, în special, cu conceptele de mulțimi măsurabile și funcții măsurabile, algebra evenimentelor etc. Cei care doresc să stăpânească aceste concepte ar trebui să apeleze la literatura de specialitate, în special, la enciclopedie.
Fiecare dintre cele trei caracteristici – așteptare matematică, mediană, mod – descrie „centrul” distribuției probabilităților. Conceptul de „centru” poate fi definit în moduri diferite - de aici trei caracteristici diferite. Cu toate acestea, pentru o clasă importantă de distribuții — simetric unimodal — toate cele trei caracteristici coincid.
Densitatea de distribuție f(x)– densitatea distribuției simetrice, dacă există un număr x 0 astfel încât
![]() . (3)
. (3)
Egalitatea (3) înseamnă că graficul funcției y = f(x) simetric față de o linie verticală care trece prin centrul de simetrie X = X 0 . Din (3) rezultă că funcția de distribuție simetrică satisface relația
![]() (4)
(4)
Pentru o distribuție simetrică cu un singur mod, așteptarea matematică, mediana și modul coincid și sunt egale x 0.
Cel mai important caz este simetria în jurul 0, adică. x 0= 0. Atunci (3) și (4) devin egalități
![]() (6)
(6)
respectiv. Relațiile de mai sus arată că nu este nevoie să se tabulare distribuțiile simetrice pentru toate X, este suficient sa ai mese la X > x 0.
Să remarcăm încă o proprietate a distribuțiilor simetrice, care este utilizată constant în metodele probabilistic-statistice de luare a deciziilor și alte cercetări aplicate. Pentru o funcție de distribuție continuă
P(|X| < a) = P(-a < X < a) = F(a) – F(-a),
Unde F– funcţia de distribuţie a unei variabile aleatoare X. Dacă funcţia de distribuţie F este simetrică în jurul valorii de 0, adică formula (6) este valabilă pentru aceasta, atunci
P(|X| < a) = 2F(a) – 1.
Deseori se foloseşte o altă formulare a enunţului în cauză: dacă
![]() .
.
Dacă și sunt cuantile de ordin și, respectiv (vezi (2)) ale unei funcții de distribuție simetrice în jurul lui 0, atunci din (6) rezultă că
Din caracteristicile poziției - așteptare matematică, mediană, mod - să trecem la caracteristicile răspândirii variabilei aleatoare X: varianță, abatere standard și coeficient de variație v. Definiția și proprietățile dispersiei pentru variabile aleatoare discrete au fost discutate în capitolul anterior. Pentru variabile aleatoare continue
Abaterea standard este valoarea nenegativă a rădăcinii pătrate a varianței:
Coeficientul de variație este raportul dintre abaterea standard și așteptările matematice:
Coeficientul de variaţie se aplică atunci când M(X)> 0. Măsoară răspândirea în unități relative, în timp ce abaterea standard este în unități absolute.
Exemplul 6. Pentru o variabilă aleatoare distribuită uniform X Să găsim dispersia, abaterea standard și coeficientul de variație. Varianta este:

Schimbarea variabilei face posibilă scrierea:
Unde c = (b – A)/ 2. Prin urmare, abaterea standard este egală cu și coeficientul de variație este:
Pentru fiecare variabilă aleatoare X determina inca trei marimi - centrate Y, normalizat Vși dat U. Variabilă aleatoare centrată Y este diferența dintre o variabilă aleatoare dată Xși așteptările sale matematice M(X), acestea. Y = X – M(X). Așteptarea unei variabile aleatoare centrate Y este egal cu 0, iar varianța este varianța unei variabile aleatoare date: M(Y) = 0, D(Y) = D(X). Funcția de distribuție F Y(X) variabilă aleatoare centrată Y legate de funcţia de distribuţie F(X) variabilă aleatoare inițială X raport:
F Y(X) = F(X + M(X)).
Densitățile acestor variabile aleatoare satisfac egalitatea
f Y(X) = f(X + M(X)).
Variabilă aleatorie normalizată V este raportul unei variabile aleatoare date X la abaterea sa standard, adică . Așteptările și varianța unei variabile aleatoare normalizate V exprimate prin caracteristici X Asa de:
![]() ,
,
Unde v– coeficientul de variație al variabilei aleatoare inițiale X. Pentru funcția de distribuție F V(X) si densitate f V(X) variabilă aleatoare normalizată V avem:
Unde F(X) – funcția de distribuție a variabilei aleatoare originale X, A f(X) – densitatea sa de probabilitate.
Variabilă aleatoare redusă U este o variabilă aleatoare centrată și normalizată:
![]() .
.
Pentru variabila aleatoare dată
Variabile aleatoare normalizate, centrate și reduse sunt utilizate în mod constant atât în studii teoretice, cât și în algoritmi, produse software, documentație de reglementare, tehnică și instrucțională. În special, pentru că egalitățile ![]() fac posibilă simplificarea justificării metodelor, formularea de teoreme și formule de calcul.
fac posibilă simplificarea justificării metodelor, formularea de teoreme și formule de calcul.
Se folosesc transformări ale variabilelor aleatoare și altele mai generale. Astfel, dacă Y = topor + b, Unde AȘi b– niște numere, atunci
Exemplul 7. Daca atunci Y este variabila aleatoare redusă, iar formulele (8) se transformă în formule (7).
Cu fiecare variabilă aleatoare X puteți asocia multe variabile aleatoare Y, dat de formula Y = topor + b la diferit A> 0 și b. Acest set se numește familie cu schimbare la scară, generat de variabila aleatoare X. Funcții de distribuție F Y(X) constituie o familie de distribuții cu schimbare la scară generată de funcția de distribuție F(X). În loc de Y = topor + b folosesc adesea înregistrarea
![]()
Număr Cu se numește parametrul de schimbare și numărul d- parametrul de scară. Formula (9) arată că X– rezultatul măsurării unei anumite cantități – intră în U– rezultatul măsurării aceleiași mărimi dacă începutul măsurării este mutat la punct Cu, apoi utilizați noua unitate de măsură, în d ori mai mare decât cea veche.
Pentru familia scale-shift (9), distribuția lui X se numește standard. În metodele statistice probabilistice de luare a deciziilor și alte cercetări aplicate, sunt utilizate distribuția normală standard, distribuția standard Weibull-Gnedenko, distribuția gamma standard etc. (vezi mai jos).
Sunt utilizate și alte transformări ale variabilelor aleatoare. De exemplu, pentru o variabilă aleatoare pozitivă X iau în considerare Y= jurnal X, unde lg X– logaritmul zecimal al unui număr X. Lanț de egalități
F Y (x) = P( lg X< x) = P(X < 10x) = F( 10X)
conectează funcțiile de distribuție XȘi Y.
La procesarea datelor, sunt utilizate următoarele caracteristici ale unei variabile aleatorii X ca momente de ordine q, adică așteptările matematice ale unei variabile aleatorii Xq, q= 1, 2, ... Astfel, așteptarea matematică în sine este un moment de ordin 1. Pentru o variabilă aleatoare discretă, momentul de ordin q poate fi calculat ca
![]()
Pentru o variabilă aleatoare continuă
![]()
Momente de ordine q numite și momente inițiale de ordine q, spre deosebire de caracteristicile conexe – momente centrale de ordine q, dat de formula
Deci, dispersia este un moment central de ordinul 2.
Distribuția normală și teorema limitei centrale.În metodele probabilistic-statistice de luare a deciziilor vorbim adesea despre distribuție normală. Uneori încearcă să-l folosească pentru a modela distribuția datelor inițiale (aceste încercări nu sunt întotdeauna justificate - vezi mai jos). Mai important, multe metode de procesare a datelor se bazează pe faptul că valorile calculate au distribuții apropiate de normal.
Lăsa X 1 , X 2 ,…, Xn M(X i) = mși variații D(X i) = , i = 1, 2,…, n,... După cum rezultă din rezultatele capitolului anterior,
Luați în considerare variabila aleatoare redusă U n pentru suma ![]() , și anume,
, și anume,
![]()
După cum rezultă din formulele (7), M(U n) = 0, D(U n) = 1.
(pentru termeni distribuiti identic). Lăsa X 1 , X 2 ,…, Xn, … – variabile aleatoare independente distribuite identic cu așteptări matematice M(X i) = mși variații D(X i) = , i = 1, 2,…, n,... Atunci pentru orice x există o limită
![]()
Unde F(x)– functie standard distributie normala.
Mai multe despre funcție F(x) – mai jos (citiți „fi din x”, pentru că F- Literă majusculă grecească „phi”).
Teorema limită centrală (CLT) își primește numele deoarece este rezultatul matematic central, cel mai frecvent utilizat al teoriei probabilităților și al statisticii matematice. Istoria CLT durează aproximativ 200 de ani - din 1730, când matematicianul englez A. Moivre (1667-1754) a publicat primul rezultat legat de CLT (vezi mai jos despre teorema Moivre-Laplace), până în anii douăzeci și treizeci de ani. secolul al XX-lea, când Finn J.W. Lindeberg, francezul Paul Levy (1886-1971), iugoslav V. Feller (1906-1970), rusul A.Ya. Khinchin (1894-1959) și alți oameni de știință au obținut condiții necesare și suficiente pentru validitatea teoremei limitei centrale clasice.
Dezvoltarea subiectului luat în considerare nu s-a oprit aici - au studiat variabile aleatoare care nu au dispersie, adică. cei pentru care
![]()
(academician B.V. Gnedenko și alții), situație în care se însumează variabile aleatoare (mai precis, elemente aleatoare) de natură mai complexă decât numerele (academicienii Yu.V. Prokhorov, A.A. Borovkov și asociații lor), etc. .d.
Funcția de distribuție F(x) este dat de egalitate
![]() ,
,
unde este densitatea distribuției normale standard, care are o expresie destul de complexă:
![]() .
.
Aici =3,1415925... este un număr cunoscut în geometrie, egal cu raportul dintre circumferință și diametru, e = 2,718281828... - baza logaritmilor naturali (pentru a reține acest număr, rețineți că 1828 este anul nașterii scriitorului L.N. Tolstoi). După cum se știe din analiza matematică,
![]()
La procesarea rezultatelor observației, funcția de distribuție normală nu este calculată folosind formulele date, ci este găsită folosind tabele speciale sau programe de calculator. Cele mai bune „Tabele de statistici matematice” în limba rusă au fost întocmite de membrii corespunzători ai Academiei de Științe a URSS L.N. Bolşev şi N.V. Smirnov.
Forma densității distribuției normale standard decurge din teoria matematică, pe care nu o putem considera aici, precum și demonstrația CLT.
Pentru ilustrare, oferim mici tabele ale funcției de distribuție F(x)(Tabelul 2) și cuantilele sale (Tabelul 3). Funcţie F(x) simetric în jurul valorii de 0, care este reflectat în Tabelul 2-3.
Masa 2.
Funcția de distribuție normală standard.
Dacă variabila aleatoare X are o funcție de distribuție F(x), Acea M(X) = 0, D(X) = 1. Această afirmație este dovedită în teoria probabilității pe baza formei densității probabilității. Este în concordanță cu o afirmație similară pentru caracteristicile variabilei aleatoare reduse U n, ceea ce este destul de firesc, întrucât CLT precizează că, cu o creștere nelimitată a numărului de termeni, funcția de distribuție U n tinde spre funcția de distribuție normală standard F(x), si pentru orice X.
Tabelul 3.
Cuantile ale distribuției normale standard.
Comandă cuantilă R |
Comandă cuantilă R |
||
Să introducem conceptul de familie de distribuții normale. Prin definiție, o distribuție normală este distribuția unei variabile aleatoare X, pentru care distribuția variabilei aleatoare reduse este F(x). După cum rezultă din proprietățile generale ale familiilor de distribuții cu schimbare la scară (vezi mai sus), o distribuție normală este o distribuție a unei variabile aleatoare
Unde X– variabilă aleatoare cu distribuție F(X),și m = M(Y), = D(Y). Distribuție normală cu parametrii de deplasare m iar scara este de obicei indicată N(m, ) (uneori se folosește notația N(m, ) ).
După cum rezultă din (8), densitatea de probabilitate a distribuției normale N(m, ) Există

Distribuțiile normale formează o familie cu schimbare la scară. În acest caz, parametrul scară este d= 1/ și parametrul de deplasare c = - m/ .
Pentru momentele centrale de ordinul trei și al patrulea ale distribuției normale sunt valabile următoarele egalități:
![]()
Aceste egalități formează baza metodelor clasice de verificare a faptului că observațiile urmează o distribuție normală. În zilele noastre se recomandă de obicei testarea normalității folosind criteriul W Shapiro - Wilka. Problema testării normalității este discutată mai jos.
Dacă variabile aleatorii X 1Și X 2 au funcții de distribuție N(m 1
, 1)
Și N(m 2
, 2)
în consecință, atunci X 1+ X 2 are o distributie ![]() Prin urmare, dacă variabile aleatoare X 1
,
X 2
,…,
Xn N(m, )
, apoi media lor aritmetică
Prin urmare, dacă variabile aleatoare X 1
,
X 2
,…,
Xn N(m, )
, apoi media lor aritmetică
![]()
are o distributie N(m, ) . Aceste proprietăți ale distribuției normale sunt utilizate în mod constant în diferite metode probabilistice și statistice de luare a deciziilor, în special, în reglementarea statistică a proceselor tehnologice și în controlul acceptării statistice bazat pe criterii cantitative.
Folosind distribuția normală, sunt definite trei distribuții care sunt acum adesea folosite în procesarea datelor statistice.
Distribuție (chi - pătrat) – distribuția unei variabile aleatoare
unde sunt variabilele aleatoare X 1 , X 2 ,…, Xn independente și au aceeași distribuție N(0,1). În acest caz, numărul de termeni, adică n, se numește „numărul de grade de libertate” al distribuției chi-pătrat.
Distributie t t al lui Student este distribuția unei variabile aleatoare
unde sunt variabilele aleatoare UȘi X independent, U are o distribuție normală standard N(0,1) și X– distribuția chi – pătratul c n grade de libertate. în care n se numește „numărul de grade de libertate” al distribuției Student. Această distribuție a fost introdusă în 1908 de statisticianul englez W. Gosset, care lucra la o fabrică de bere. Pentru luarea deciziilor economice și tehnice la această fabrică au fost folosite metode probabilistice și statistice, așa că conducerea acesteia i-a interzis lui V. Gosset să publice articole științifice sub nume propriu. În acest fel au fost protejate secretele comerciale și „know-how” sub forma metodelor probabilistice și statistice dezvoltate de V. Gosset. A avut însă ocazia să publice sub pseudonimul „Student”. Istoria Gosset-Student arată că încă o sută de ani, managerii din Marea Britanie au fost conștienți de eficiența economică mai mare a metodelor probabilistic-statistice de luare a deciziilor.
Distribuția Fisher este distribuția unei variabile aleatoare
unde sunt variabilele aleatoare X 1Și X 2 sunt independente și au distribuții chi-pătrat cu numărul de grade de libertate k 1 Și k 2 respectiv. În același timp, cuplul (k 1 , k 2 ) – o pereche de „grade de libertate” ale distribuției Fisher și anume, k 1 este numărul de grade de libertate ale numărătorului și k 2 – numărul de grade de libertate al numitorului. Distribuția variabilei aleatoare F este numită după marele statistician englez R. Fisher (1890-1962), care a folosit-o activ în lucrările sale.
Expresiile pentru funcțiile de distribuție chi-pătrat, Student și Fisher, densitățile și caracteristicile acestora, precum și tabele pot fi găsite în literatura de specialitate (vezi, de exemplu,).
După cum sa menționat deja, distribuțiile normale sunt acum adesea folosite în modele probabilistice în diferite domenii aplicate. Care este motivul pentru care această familie de distribuții cu doi parametri este atât de răspândită? Se clarifică prin următoarea teoremă.
Teorema limitei centrale(pentru termeni distribuiti diferit). Lăsa X 1 , X 2 ,…, Xn,… - variabile aleatoare independente cu așteptări matematice M(X 1 ), M(X 2 ),…, M(X n), ... și variații D(X 1 ), D(X 2 ),…, D(X n), ... respectiv. Lăsa
Atunci, dacă sunt adevărate anumite condiții care asigură contribuția mică a oricăruia dintre termenii din U n,
![]()
pentru oricine X.
Nu vom formula aici condițiile în cauză. Ele pot fi găsite în literatura de specialitate (vezi, de exemplu,). „Clarificarea condițiilor în care funcționează CPT este meritul remarcabililor oameni de știință ruși A.A. Markov (1857-1922) și, în special, A.M. Lyapunov (1857-1918).”
Teorema limită centrală arată că în cazul în care rezultatul unei măsurători (observări) se formează sub influența mai multor cauze, fiecare dintre ele aducând doar o mică contribuție, iar rezultatul total este determinat aditiv, adică prin adăugare, atunci distribuția rezultatului măsurării (observării) este aproape de normal.
Uneori se crede că pentru ca distribuția să fie normală, este suficient ca rezultatul măsurării (observării) X se formează sub influența mai multor motive, fiecare dintre ele având un impact mic. Este gresit. Ceea ce contează este modul în care acţionează aceste cauze. Dacă este aditiv, atunci X are o distribuție aproximativ normală. Dacă în mod multiplicativ(adică acțiunile cauzelor individuale sunt multiplicate și nu adăugate), apoi distribuția X aproape nu de normal, ci de așa-zis. normal din punct de vedere logaritmic, adică Nu X, iar log X are o distribuție aproximativ normală. Dacă nu există niciun motiv să credem că unul dintre aceste două mecanisme pentru formarea rezultatului final funcționează (sau un alt mecanism bine definit), atunci despre distribuție X nimic cert nu se poate spune.
Din cele de mai sus rezultă că, într-o problemă aplicată specifică, normalitatea rezultatelor măsurătorilor (observațiilor), de regulă, nu poate fi stabilită din considerații generale; ea trebuie verificată folosind criterii statistice. Sau utilizați metode statistice neparametrice care nu se bazează pe ipoteze despre apartenența funcțiilor de distribuție a rezultatelor măsurătorilor (observații) la una sau la alta familie de parametri.
Distribuții continue utilizate în metodele probabilistice și statistice de luare a deciziilor.În plus față de familia de distribuții normale cu schimbare la scară, o serie de alte familii de distribuții sunt utilizate pe scară largă - distribuții lognormale, exponențiale, Weibull-Gnedenko, gamma. Să ne uităm la aceste familii.
Valoare aleatoare X are o distribuție lognormală dacă variabila aleatoare Y= jurnal X are o distribuție normală. Apoi Z= jurnal X = 2,3026…Y are de asemenea o distribuție normală N(A 1 ,σ 1), unde ln X- logaritmul natural X. Densitatea distribuției lognormale este:

Din teorema limită centrală rezultă că produsul X = X 1 X 2 … Xn variabile aleatoare pozitive independente X i, i = 1, 2,…, n, în mare n poate fi aproximată printr-o distribuție lognormală. În special, modelul multiplicativ al formării salariilor sau veniturilor conduce la recomandarea de a aproxima distribuțiile salariilor și veniturilor prin legi normale din punct de vedere logaritmic. Pentru Rusia, această recomandare s-a dovedit a fi justificată - datele statistice o confirmă.
Există și alte modele probabilistice care conduc la legea lognormală. Un exemplu clasic de astfel de model a fost dat de A.N. Kolmogorov, care, dintr-un sistem de postulate bazat fizic, a ajuns la concluzia că dimensiunile particulelor la zdrobirea bucăților de minereu, cărbune etc. în morile cu bile au o distribuţie lognormală.
Să trecem la o altă familie de distribuții, utilizată pe scară largă în diverse metode probabilistic-statistice de luare a deciziilor și alte cercetări aplicate - familia distribuțiilor exponențiale. Să începem cu un model probabilistic care duce la astfel de distribuții. Pentru a face acest lucru, luați în considerare „fluxul de evenimente”, adică. o succesiune de evenimente care au loc unul după altul în anumite momente în timp. Exemplele includ: fluxul de apeluri la o centrală telefonică; fluxul defecțiunilor echipamentelor în lanțul tehnologic; fluxul de defecțiuni ale produsului în timpul testării produsului; fluxul cererilor clienților către sucursala băncii; fluxul de cumpărători care solicită bunuri și servicii etc. În teoria fluxurilor de evenimente este valabilă o teoremă similară teoremei limitei centrale, dar nu este vorba despre însumarea variabilelor aleatoare, ci despre însumarea fluxurilor de evenimente. Considerăm un debit total compus dintr-un număr mare de fluxuri independente, niciunul dintre care nu are o influență predominantă asupra debitului total. De exemplu, un flux de apeluri care intră într-o centrală telefonică este compus dintr-un număr mare de fluxuri de apel independente care provin de la abonați individuali. S-a dovedit că în cazul în care caracteristicile fluxurilor nu depind de timp, debitul total este complet descris printr-un număr - intensitatea fluxului. Pentru debitul total, luați în considerare variabila aleatoare X- lungimea intervalului de timp dintre evenimente succesive. Funcția sa de distribuție are forma
 (10)
(10)
Această distribuție se numește distribuție exponențială deoarece formula (10) implică funcția exponențială e -λ X. Valoarea 1/λ este un parametru de scară. Uneori este introdus și un parametru de schimbare Cu, distribuția unei variabile aleatoare se numește exponențială X + s, unde distribuția X este dat de formula (10).
Distribuțiile exponențiale sunt un caz special al așa-numitelor. Distribuții Weibull - Gnedenko. Ele sunt numite după numele inginerului V. Weibull, care a introdus aceste distribuții în practica analizei rezultatelor testelor de oboseală, și al matematicianului B.V. Gnedenko (1912-1995), care a primit astfel de distribuții ca limite atunci când studia maximul de rezultatele testelor. Lăsa X- o variabilă aleatorie care caracterizează durata de funcționare a unui produs, sistem complex, element (adică resursă, timp de funcționare până la o stare limită etc.), durata de funcționare a unei întreprinderi sau viața unei ființe vii etc. Intensitatea eșecului joacă un rol important
![]() (11)
(11)
Unde F(X) Și f(X) - funcţia de distribuţie şi densitatea unei variabile aleatoare X.
Să descriem comportamentul tipic al ratei de eșec. Întregul interval de timp poate fi împărțit în trei perioade. Pe primul dintre ele funcţia λ(x) are valori ridicate și o tendință clară de scădere (cel mai adesea scade monoton). Acest lucru poate fi explicat prin prezența în lotul de unități de produs în cauză cu defecte evidente și ascunse, care duc la o defecțiune relativ rapidă a acestor unități de produs. Prima perioadă se numește „perioada de evaziune” (sau „perioada de evaziune”). Aceasta este ceea ce acoperă de obicei perioada de garanție.
Urmează apoi o perioadă de funcționare normală, caracterizată printr-o rată de eșec aproximativ constantă și relativ scăzută. Natura defecțiunilor în această perioadă este bruscă (accidente, erori ale personalului de exploatare etc.) și nu depinde de durata de funcționare a unității de produs.
În sfârșit, ultima perioadă de funcționare este perioada de îmbătrânire și uzură. Natura defecțiunilor în această perioadă este în modificări fizice, mecanice și chimice ireversibile ale materialelor, conducând la o deteriorare progresivă a calității unei unități de produs și la defecțiunea finală a acesteia.
Fiecare perioadă are propriul său tip de funcție λ(x). Să luăm în considerare clasa dependențelor de putere
λ(x) = λ 0bx b -1 , (12)
Unde λ 0 > 0 și b> 0 - unii parametri numerici. Valori b < 1, b= 0 și b> 1 corespund tipului de defecțiune în perioadele de rodare, de funcționare normală și, respectiv, de îmbătrânire.
Relația (11) la o rată de eșec dată λ(x)- ecuație diferențială pentru o funcție F(X). Din teorie ecuatii diferentiale urmează că
 (13)
(13)
Înlocuind (12) în (13), obținem că
 (14)
(14)
Distribuția dată de formula (14) se numește distribuție Weibull - Gnedenko. Deoarece
apoi din formula (14) rezultă că cantitatea A, dat de formula (15), este un parametru de scară. Uneori este introdus și un parametru de schimbare, de ex. Se numesc funcțiile de distribuție Weibull-Gnedenko F(X - c), Unde F(X) este dat de formula (14) pentru unele λ 0 și b.
Densitatea de distribuție Weibull-Gnedenko are forma
 (16)
(16)
Unde A> 0 - parametrul de scară, b> 0 - parametru de formă, Cu- parametrul de schimbare. În acest caz, parametrul A din formula (16) este asociat cu parametrul λ 0 din formula (14) prin relația specificată în formula (15).
Distribuția exponențială este un caz foarte special al distribuției Weibull-Gnedenko, corespunzătoare valorii parametrului de formă. b = 1.
Distribuția Weibull-Gnedenko este, de asemenea, utilizată în construirea modelelor probabilistice ale situațiilor în care comportamentul unui obiect este determinat de „cea mai slabă verigă”. Există o analogie cu un lanț, a cărui siguranță este determinată de veriga care are cea mai mică rezistență. Cu alte cuvinte, lasă X 1 , X 2 ,…, Xn- variabile aleatoare independente distribuite identic,
X(1)=min( X 1, X 2,…, X n), X(n)=max( X 1, X 2,…, X n).
Într-o serie de probleme aplicate, acestea joacă un rol important X(1) Și X(n) , în special, atunci când se studiază valorile maxime posibile ("înregistrări") ale anumitor valori, de exemplu, plăți de asigurare sau pierderi datorate riscurilor comerciale, când se studiază limitele de elasticitate și rezistență ale oțelului, o serie de caracteristici de fiabilitate etc. . Se arată că pentru n mari distribuţiile X(1) Și X(n) , de regulă, sunt bine descrise de distribuțiile Weibull-Gnedenko. Contribuție fundamentală la studiul distribuțiilor X(1) Și X(n) contribuit de matematicianul sovietic B.V. Gnedenko. Lucrările lui V. Weibull, E. Gumbel, V.B. sunt dedicate utilizării rezultatelor obținute în economie, management, tehnologie și alte domenii. Nevzorova, E.M. Kudlaev și mulți alți specialiști.
Să trecem la familia distribuțiilor gamma. Ele sunt utilizate pe scară largă în economie și management, teoria și practica fiabilității și testării, în diverse domenii ale tehnologiei, meteorologiei etc. În special, în multe situații, distribuția gamma este supusă unor cantități precum durata de viață totală a produsului, lungimea lanțului de particule conductoare de praf, timpul în care produsul atinge starea limită în timpul coroziunii, timpul de funcționare până la k-al-lea refuz, k= 1, 2, … etc. Speranța de viață a pacienților boli cronice, timpul pentru a obține un anumit efect în timpul tratamentului are în unele cazuri o distribuție gamma. Această distribuție este cea mai adecvată pentru descrierea cererii în modelele economice și matematice de gestionare a stocurilor (logistică).
Densitatea distribuției gamma are forma
 (17)
(17)
Densitatea de probabilitate din formula (17) este determinată de trei parametri A, b, c, Unde A>0, b>0. în care A este un parametru de formă, b- parametrul de scară și Cu- parametrul de schimbare. Factor 1/Γ(a) se normalizează, a fost introdus
![]()
Aici Γ(a)- una dintre cele folosite la matematică funcții speciale, așa-numita „funcție gamma”, după care se numește distribuția definită prin formula (17),

La fix A formula (17) specifică o familie de distribuții cu deplasare la scară generată de o distribuție cu densitate
 (18)
(18)
O distribuție de forma (18) se numește distribuție gamma standard. Se obține din formula (17) la b= 1 și Cu= 0.
Un caz special de distribuții gamma pentru A= 1 sunt distribuții exponențiale (cu λ = 1/b). Cu naturale AȘi Cu=0 distribuțiile gamma se numesc distribuții Erlang. Din lucrările omului de știință danez K.A. Erlang (1878-1929), angajat al Companiei de telefonie din Copenhaga, care a studiat în 1908-1922. funcţionarea reţelelor de telefonie, a început dezvoltarea teoriei cozilor de aşteptare. Această teorie se ocupă de modelarea probabilistică și statistică a sistemelor în care un flux de cereri este deservit pentru a lua decizii optime. Distribuțiile Erlang sunt utilizate în aceleași domenii de aplicație în care sunt utilizate distribuțiile exponențiale. Aceasta se bazează pe următorul fapt matematic: suma k variabile aleatoare independente distribuite exponențial cu aceiași parametri λ și Cu, are o distribuție gamma cu un parametru de formă a =k, parametrul de scară b= 1/λ și parametrul de deplasare kc. La Cu= 0 obținem distribuția Erlang.
Dacă variabila aleatoare X are o distribuție gamma cu un parametru de formă A astfel încât d = 2 A- întreg, b= 1 și Cu= 0, apoi 2 X are o distribuție chi-pătrat cu d grade de libertate.
Valoare aleatoare X cu distribuția gvmma are următoarele caracteristici:
Valorea estimata M(X) =ab + c,
Varianta D(X) = σ 2 = ab 2 ,
Coeficientul de variație
Asimetrie ![]()
Exces ![]()
Distribuția normală este un caz extrem al distribuției gamma. Mai precis, să fie Z o variabilă aleatoare având o distribuție gamma standard dată de formula (18). Apoi
![]()
pentru orice număr real X, Unde F(x)- functie de distributie normala standard N(0,1).
În cercetarea aplicată se folosesc și alte familii parametrice de distribuții, dintre care cele mai cunoscute sunt sistemul de curbe Pearson, seria Edgeworth și Charlier. Ele nu sunt luate în considerare aici.
Discret distribuţii utilizate în metodele probabilistice şi statistice de luare a deciziilor. Cele mai frecvent utilizate sunt trei familii de distribuții discrete - binomială, hipergeometrică și Poisson, precum și alte familii - geometrice, binom negative, multinomiale, hipergeometrice negative etc.
După cum sa menționat deja, distribuția binomială are loc în încercări independente, în fiecare dintre acestea cu probabilitate R apare evenimentul A. Dacă numărul total teste n dat, apoi numărul de teste Y, în care a apărut evenimentul A, are o distribuție binomială. Pentru o distribuție binomială, probabilitatea de a fi acceptată ca variabilă aleatorie este Y valorile y este determinat de formula
![]()
Numărul de combinații de n elemente prin y, cunoscut din combinatorică. Pentru toți y, cu excepția 0, 1, 2, …, n, avem P(Y= y)= 0. Distribuție binomială cu dimensiunea eșantionului fixă n este specificat de parametru p, adică distribuțiile binomiale formează o familie cu un singur parametru. Ele sunt utilizate în analiza datelor din studiile pe eșantion, în special în studiul preferințelor consumatorilor, controlul selectiv al calității produselor conform planurilor de control într-o singură etapă, la testarea populațiilor de indivizi în demografie, sociologie, medicină, biologie etc. .
Dacă Y 1 Și Y 2 - variabile aleatoare binomiale independente cu același parametru p 0 , determinat din probe cu volume n 1 Și n 2 în consecință, atunci Y 1 + Y 2 - variabilă aleatoare binomială având distribuţia (19) cu R = p 0 Și n = n 1 + n 2 . Această remarcă extinde aplicabilitatea distribuției binomiale permițând combinarea rezultatelor mai multor grupuri de teste atunci când există motive să credem că același parametru corespunde tuturor acestor grupuri.
Caracteristicile distribuției binomiale au fost calculate mai devreme:
M(Y) = n.p., D(Y) = n.p.( 1- p).
În secțiunea „Evenimente și probabilități” legea numerelor mari este dovedită pentru o variabilă aleatoare binomială:
![]()
pentru oricine . Folosind teorema limitei centrale, legea numerelor mari poate fi rafinată indicând cât Y/ n difera de R.
Teorema lui De Moivre-Laplace. Pentru orice numere a și b, A< b, avem

Unde F(X) este o funcție a distribuției normale standard cu așteptarea matematică 0 și varianța 1.
Pentru a dovedi, este suficient să folosim reprezentarea Y sub forma unei sume de variabile aleatoare independente corespunzătoare rezultatelor testelor individuale, formule pentru M(Y) Și D(Y) și teorema limitei centrale.
Această teoremă este pentru caz R= ½ a fost dovedit de matematicianul englez A. Moivre (1667-1754) în 1730. În formularea de mai sus, a fost dovedit în 1810 de matematicianul francez Pierre Simon Laplace (1749 - 1827).
Distribuția hipergeometrică are loc în timpul controlului selectiv al unui set finit de obiecte de volum N conform unui criteriu alternativ. Fiecare obiect controlat este clasificat fie ca având atributul A, sau ca neavând această caracteristică. Distribuția hipergeometrică are o variabilă aleatorie Y, egală cu numărul obiecte care au caracteristica Aîntr-o probă aleatorie de volum n, Unde n< N. De exemplu, numărul Y unități defecte de produs într-un eșantion aleatoriu de volum n din volumul lotului N are o distribuţie hipergeometrică dacă n< N. Un alt exemplu este loteria. Lasă semnul A biletul este un semn de „a fi un câștigător”. Lăsați numărul total de bilete N, și o persoană dobândită n dintre ei. Atunci numărul de bilete câștigătoare pentru această persoană are o distribuție hipergeometrică.
Pentru o distribuție hipergeometrică, probabilitatea ca o variabilă aleatoare Y să accepte valoarea y are forma
 (20)
(20)
Unde D– numărul de obiecte care au atributul A, în setul considerat de volum N. în care y ia valori de la max(0, n - (N - D)) la min( n, D), alte lucruri y probabilitatea din formula (20) este egală cu 0. Astfel, distribuția hipergeometrică este determinată de trei parametri - volum populatia N, numărul de obiecte Dîn ea, posedând caracteristica în cauză A, și dimensiunea eșantionului n.
Eșantionare aleatoare simplă a volumului n din volumul total N este un eșantion obținut ca urmare a selecției aleatorii în care oricare dintre seturile de n obiectele au aceeași probabilitate de a fi selectate. Metodele de selectare aleatorie a eșantioanelor de respondenți (intervievați) sau a unităților de mărfuri sunt discutate în documentele de instrucție, metodologice și de reglementare. Una dintre metodele de selecție este aceasta: obiectele sunt selectate unul din altul, iar la fiecare pas, fiecare dintre obiectele rămase din set are aceeași șansă de a fi selectat. În literatură, termenii „eșantion aleatoriu” și „eșantion aleatoriu fără returnare” sunt utilizați și pentru tipul de eșantioane luate în considerare.
Deoarece volumele populației (lot) Nși mostre n sunt de obicei cunoscute, atunci parametrul distribuției hipergeometrice de estimat este D. În metodele statistice de management al calității produselor D– de obicei numărul de unități defecte dintr-un lot. Caracteristica distribuției este, de asemenea, de interes D/ N– nivelul defectelor.
Pentru distribuția hipergeometrică
Ultimul factor din expresia pentru varianță este aproape de 1 dacă N>10 n. Dacă faci un înlocuitor p = D/ N, atunci expresiile pentru așteptarea și varianța matematică a distribuției hipergeometrice se vor transforma în expresii pentru așteptarea și varianța matematică a distribuției binomiale. Aceasta nu este o coincidență. Se poate arăta că

la N>10 n, Unde p = D/ N. Raportul limitativ este valabil
iar această relaţie limitativă poate fi folosită când N>10 n.
A treia distribuție discretă utilizată pe scară largă este distribuția Poisson. Variabila aleatoare Y are o distribuție Poisson dacă
![]() ,
,
unde λ este parametrul distribuției Poisson și P(Y= y)= 0 pentru toate celelalte y(pentru y=0 este desemnat 0! =1). Pentru distribuția Poisson
M(Y) = λ, D(Y) = λ.
Această distribuție este numită după matematicianul francez S. D. Poisson (1781-1840), care a obținut-o pentru prima dată în 1837. Distribuția Poisson este cazul limită al distribuției binomiale, când probabilitatea R implementarea evenimentului este mică, dar numărul de teste n grozav, și n.p.= λ. Mai exact, relația limită este valabilă
Prin urmare, distribuția Poisson (în vechea terminologie „legea distribuției”) este adesea numită și „legea evenimentelor rare”.
Distribuția Poisson își are originea în teoria fluxului de evenimente (vezi mai sus). S-a dovedit că pentru cel mai simplu flux cu intensitate constantă Λ, numărul de evenimente (apeluri) care au avut loc în timpul t, are o distribuție Poisson cu parametrul λ = Λ t. Prin urmare, probabilitatea ca pe parcursul timpului t nu va avea loc nici un eveniment, egal cu e - Λ t, adică funcţia de distribuţie a lungimii intervalului dintre evenimente este exponenţială.
Distribuția Poisson este utilizată în analiza rezultatelor sondajelor de marketing prin eșantion ale consumatorilor, calculând caracteristicile operaționale ale planurilor de control statistic de acceptare în cazul unor valori mici ale nivelului de acceptare a defectelor, pentru a descrie numărul de defecțiuni ale unui control statistic. proces tehnologic pe unitatea de timp, numărul de „cerințe de serviciu” primite pe unitatea de timp în sistemul de așteptare, modelele statistice ale accidentelor și boli rare, etc.
Descrierea altor familii parametrice de distribuții discrete și posibilitățile acestora uz practic sunt considerate în literatură.
În unele cazuri, de exemplu, când se studiază prețurile, volumele de producție sau timpul total dintre eșecurile problemelor de fiabilitate, funcțiile de distribuție sunt constante pe anumite intervale în care valorile variabilelor aleatoare studiate nu pot scădea.
| Anterior |
3. Funcția de distribuție este nescădere: daca atunci
4. Funcția de distribuție lăsat continuu: pentru oricine .
Notă. Ultima proprietate indică ce valori ia funcția de distribuție la punctele de întrerupere. Uneori definiția funcției de distribuție este formulată folosind o inegalitate liberă: . În acest caz, continuitatea din stânga este înlocuită cu continuitatea din dreapta: când . Acest lucru nu schimbă nicio proprietăți semnificative ale funcției de distribuție, așa că această întrebare este doar terminologică.
Proprietățile 1-4 sunt caracteristice, adică orice funcție care satisface aceste proprietăți este o funcție de distribuție a unei variabile aleatoare.
Funcția de distribuție definește în mod unic distribuția de probabilitate a unei variabile aleatoare. De fapt, este un mod universal și cel mai vizual de a descrie această distribuție.
Cu cât funcția de distribuție crește mai mult pe un interval dat al dreptei numerice, cu atât este mai mare probabilitatea ca o variabilă aleatorie să cadă în acest interval. Dacă probabilitatea de a cădea într-un interval este zero, atunci funcția de distribuție a acestuia este constantă.
În special, probabilitatea ca o variabilă aleatorie să ia o valoare dată este egală cu saltul în funcția de distribuție la un punct dat:
.Dacă funcția de distribuție este continuă în punctul , atunci probabilitatea de a lua această valoare pentru o variabilă aleatorie este zero. În special, dacă funcția de distribuție este continuă pe toată axa numerică (în acest caz, distribuția corespunzătoare se numește continuu), atunci probabilitatea de a accepta orice valoare dată este zero.
Din definiția funcției de distribuție rezultă că probabilitatea ca o variabilă aleatoare să cadă într-un interval închis la stânga și deschis la dreapta este egală cu:
Folosind această formulă și metoda de mai sus de a găsi probabilitatea de a atinge orice punct dat, probabilitățile ca o variabilă aleatoare să intre în intervale de alte tipuri sunt ușor de determinat: , și . În plus, prin teorema extinderii măsurii, putem extinde măsura în mod unic la toate seturile Borel ale dreptei numerice. Pentru aplicarea acestei teoreme este necesar să se arate că măsura astfel definită pe intervale este sigma-aditivă asupra acestora; atunci când se demonstrează acest lucru, se folosesc exact proprietățile 1-4 (în special, proprietatea continuității stângi 4, deci nu poate fi aruncată).
Generarea unei variabile aleatoare cu o distribuție dată
Să considerăm o variabilă aleatoare care are o funcție de distribuție. Să ne prefacem că continuu. Luați în considerare variabila aleatoare
.Este ușor de arătat că atunci va avea o distribuție uniformă pe segment.
Definirea unei funcții de variabile aleatoare. Funcția argumentului aleator discret și caracteristicile sale numerice. Funcția argumentului aleator continuu și caracteristicile sale numerice. Funcțiile a două argumente aleatorii. Determinarea funcției de distribuție a probabilității și a densității pentru o funcție a două argumente aleatorii.
Legea distribuției de probabilitate a unei funcții a unei variabile aleatoare
La rezolvarea problemelor legate de evaluarea acurateței funcționării diferitelor sisteme automate, a preciziei producției de elemente individuale ale sistemelor etc., este adesea necesar să se ia în considerare funcțiile uneia sau mai multor variabile aleatoare. Astfel de funcții sunt și variabile aleatoare. Prin urmare, la rezolvarea problemelor, este necesar să se cunoască legile de distribuție a variabilelor aleatoare care apar în problemă. În acest caz, legea de distribuție a sistemului de argumente aleatoare și dependența funcțională sunt de obicei cunoscute.
Astfel, apare o problemă care poate fi formulată după cum urmează.
Dat un sistem de variabile aleatoare (X_1,X_2,\ldots,X_n), a cărui lege de distribuție este cunoscută. O variabilă aleatoare Y este considerată în funcție de aceste variabile aleatoare:
Y=\varphi(X_1,X_2,\ldots,X_n).
Se cere determinarea legii de distribuție a variabilei aleatoare Y, cunoscând forma funcțiilor (6.1) și legea distribuției în comun a argumentelor acesteia.
Să luăm în considerare problema legii de distribuție a unei funcții a unui argument aleatoriu
Y=\varphi(X).
\begin(array)(|c|c|c|c|c|)\hline(X)&x_1&x_2&\cdots&x_n\\\hline(P)&p_1&p_2&\cdots&p_n\\\hline\end(array)
Atunci Y=\varphi(X) este, de asemenea, o variabilă aleatorie discretă cu valori posibile. Dacă toate valorile y_1,y_2,\ldots,y_n sunt diferite, atunci pentru fiecare k=1,2,\ldots,n evenimentele \(X=x_k\) și \(Y=y_k=\varphi(x_k)\) sunt identice. Prin urmare,
P\(Y=y_k\)=P\(X=x_k\)=p_k
iar seria de distribuție necesară are forma
\begin(array)(|c|c|c|c|c|)\hline(Y)&y_1=\varphi(x_1)&y_2=\varphi(x_2)&\cdots&y_n=\varphi(x_n)\\\hline (P)&p_1&p_2&\cdots&p_n\\\hline\end(array)
Dacă printre numere y_1=\varphi(x_1),y_2=\varphi(x_2),\ldots,y_n=\varphi(x_n) există unele identice, apoi fiecare grup de valori identice y_k=\varphi(x_k) trebuie să i se aloce o coloană în tabel și să se adună probabilitățile corespunzătoare.
Pentru variabile aleatoare continue, problema se pune astfel: cunoscând densitatea de distribuție f(x) a variabilei aleatoare X, găsiți densitatea de distribuție g(y) a variabilei aleatoare Y=\varphi(X). Când rezolvăm problema, luăm în considerare două cazuri.
Să presupunem mai întâi că funcția y=\varphi(x) este monoton crescătoare, continuă și diferențiabilă pe intervalul (a;b) pe care toate valori posibile valorile X. Atunci funcția inversă x=\psi(y) există, fiind totodată monoton crescătoare, continuă și diferențiabilă. În acest caz obținem
G(y)=f\bigl(\psi(y)\bigr)\cdot |\psi"(y)|.
Exemplul 1. Variabila aleatoare X distribuită cu densitate
F(x)=\frac(1)(\sqrt(2\pi))e^(-x^2/2)
Aflați legea de distribuție a variabilei aleatoare Y asociată cu valoarea X prin dependența Y=X^3.
Soluţie. Deoarece funcția y=x^3 este monotonă pe intervalul (-\infty;+\infty), putem aplica formula (6.2). Funcție inversăîn raport cu funcția \varphi(x)=x^3 există \psi(y)=\sqrt(y) , derivata acesteia \psi"(y)=\frac(1)(3\sqrt(y^2)). Prin urmare,
G(y)=\frac(1)(3\sqrt(2\pi))e^(-\sqrt(y^2)/2)\frac(1)(\sqrt(y^2))
Să luăm în considerare cazul unei funcții nemonotone. Fie funcția y=\varphi(x) astfel încât funcția inversă x=\psi(y) să fie ambiguă, adică o valoare a lui y corespunde mai multor valori ale argumentului x, pe care le notăm x_1=\psi_1(y),x_2=\psi_2(y),\ldots,x_n=\psi_n(y), unde n este numărul de secțiuni în care funcția y=\varphi(x) se modifică monoton. Apoi
G(y)=\sum\limits_(k=1)^(n)f\bigl(\psi_k(y)\bigr)\cdot |\psi"_k(y)|.
Exemplul 2. În condițiile exemplului 1, găsiți distribuția variabilei aleatoare Y=X^2.
Soluţie. Funcția inversă x=\psi(y) este ambiguă. O valoare a argumentului y corespunde cu două valori ale funcției x
Aplicând formula (6.3), obținem:
\begin(gathered)g(y)=f(\psi_1(y))|\psi"_1(y)|+f(\psi_2(y))|\psi"_2(y)|=\\\\ =\frac(1)(\sqrt(2\pi))\,e^(-\left(-\sqrt(y^2)\right)^2/2)\!\left|-\frac(1 )(2\sqrt(y))\right|+\frac(1)(\sqrt(2\pi))\,e^(-\left(\sqrt(y^2)\right)^2/2 )\!\left|\frac(1)(2\sqrt(y))\right|=\frac(1)(\sqrt(2\pi(y)))\,e^(-y/2) .\end(adunat)
Legea distribuției unei funcții a două variabile aleatoare
Fie variabila aleatoare Y o funcție a două variabile aleatoare care formează sistemul (X_1;X_2), adică. Y=\varphi(X_1;X_2). Sarcina este de a găsi distribuția variabilei aleatoare Y folosind distribuția cunoscută a sistemului (X_1;X_2).
Fie f(x_1;x_2) densitatea de distribuție a sistemului de variabile aleatoare (X_1;X_2) . Să introducem în considerare o nouă mărime Y_1 egală cu X_1 și să considerăm sistemul de ecuații
Vom presupune că acest sistem este solubil în mod unic în raport cu x_1,x_2
si satisface conditiile de diferentiabilitate.
Densitatea de distribuție a variabilei aleatoare Y
G_1(y)=\int\limits_(-\infty)^(+\infty)f(x_1;\psi(y;x_1))\!\left|\frac(\partial\psi(y;x_1)) (\partial(y))\right|dx_1.
Rețineți că raționamentul nu se schimbă dacă noua valoare introdusă Y_1 este setată egală cu X_2.
Așteptarea matematică a unei funcții de variabile aleatoare
În practică, există adesea cazuri în care nu este necesară determinarea completă a legii de distribuție a unei funcții de variabile aleatoare, ci este suficient doar să indicați caracteristicile sale numerice. Astfel, se pune problema determinării caracteristicilor numerice ale funcţiilor variabilelor aleatoare pe lângă legile de distribuţie ale acestor funcţii.
Fie variabila aleatoare Y o funcție a argumentului aleator X cu o lege de distribuție dată
Y=\varphi(X).
Se cere, fără a găsi legea de distribuție a mărimii Y, să se determine așteptarea ei matematică
M(Y)=M[\varphi(X)].
Fie X o variabilă aleatoare discretă având o serie de distribuție
\begin(array)(|c|c|c|c|c|)\hline(x_i)&x_1&x_2&\cdots&x_n\\\hline(p_i)&p_1&p_2&\cdots&p_n\\\hline\end(array)
Să facem un tabel cu valorile valorii Y și probabilitățile acestor valori:
\begin(array)(|c|c|c|c|c|)\hline(y_i=\varphi(x_i))&y_1=\varphi(x_1)&y_2=\varphi(x_2)&\cdots&y_n=\varphi( x_n)\\\hline(p_i)&p_1&p_2&\cdots&p_n\\\hline\end(array)
Acest tabel nu este o serie de distribuție a variabilei aleatoare Y, deoarece în cazul general unele dintre valori pot coincide între ele, iar valorile din rândul de sus nu sunt neapărat în ordine crescătoare. Cu toate acestea, așteptarea matematică a variabilei aleatoare Y poate fi determinată prin formulă
M[\varphi(X)]=\sum\limits_(i=1)^(n)\varphi(x_i)p_i,
întrucât valoarea determinată prin formula (6.4) nu se poate modifica datorită faptului că sub semnul sumei se vor combina în prealabil unii termeni, iar ordinea termenilor va fi modificată.
Formula (6.4) nu conține în mod explicit legea de distribuție a funcției \varphi(X) în sine, ci conține doar legea de distribuție a argumentului X. Astfel, pentru a determina așteptarea matematică a funcției Y=\varphi(X), nu este deloc necesar să se cunoască legea de distribuție a funcției \varphi(X), ci mai degrabă să se cunoască legea distribuției argumentului X.
Pentru o variabilă aleatoare continuă, așteptarea matematică este calculată folosind formula
M[\varphi(X)]=\int\limits_(-\infty)^(+\infty)\varphi(x)f(x)\,dx,
unde f(x) este densitatea distribuției de probabilitate a variabilei aleatoare X.
Să luăm în considerare cazurile în care, pentru a afla așteptarea matematică a unei funcții de argumente aleatoare, nu este necesară cunoașterea nici măcar a legilor de distribuție a argumentelor, dar este suficient să cunoaștem doar câteva dintre caracteristicile lor numerice. Să formulăm aceste cazuri sub formă de teoreme.
Teorema 6.1. Așteptările matematice ale sumei a două variabile aleatoare atât dependente, cât și independente este egală cu suma așteptărilor matematice ale acestor variabile:
M(X+Y)=M(X)+M(Y).
Teorema 6.2. Așteptările matematice ale produsului a două variabile aleatoare este egală cu produsul așteptărilor lor matematice plus momentul de corelație:
M(XY)=M(X)M(Y)+\mu_(xy).
Corolarul 6.1. Așteptările matematice ale produsului a două variabile aleatoare necorelate este egală cu produsul așteptărilor lor matematice.
Corolarul 6.2. Așteptările matematice ale produsului a două variabile aleatoare independente este egală cu produsul așteptărilor lor matematice.
Varianta unei functii de variabile aleatoare
Prin definiția dispersiei avem D[Y]=M[(Y-M(Y))^2].. Prin urmare,
D[\varphi(x)]=M[(\varphi(x)-M(\varphi(x)))^2], Unde .
Prezentăm formulele de calcul doar pentru cazul argumentelor aleatoare continue. Pentru o funcție a unui argument aleator Y=\varphi(X), varianța este exprimată prin formula
D[\varphi(x)]=\int\limits_(-\infty)^(+\infty)(\varphi(x)-M(\varphi(x)))^2f(x)\,dx,
Unde M(\varphi(x))=M[\varphi(X)]- asteptarea matematica a functiei \varphi(X) ; f(x) - densitatea de distribuție a valorii X.
Formula (6.5) poate fi înlocuită cu următoarea:
D[\varphi(x)]=\int\limits_(-\infty)^(+\infty)\varphi^2(x)f(x)\,dx-M^2(X)
Sa luam in considerare teoreme de dispersie, care joacă un rol important în teoria probabilității și în aplicațiile acesteia.
Teorema 6.3. Varianța sumei variabilelor aleatoare este egală cu suma varianțelor acestor mărimi plus suma dublată a momentelor de corelație ale fiecăreia dintre sume cu toate cele ulterioare:
D\!\left[\sum\limits_(i=1)^(n)X_i\right]=\sum\limits_(i=1)^(n)D+2\sum\limits_(i Corolarul 6.3. Varianța sumei variabilelor aleatoare necorelate este egală cu suma varianțelor termenilor: D\!\left[\sum\limits_(i=1)^(n)X_i\right]=\sum\limits_(i=1)^(n)D\mu_(y_1y_2)= M(Y_1Y_2)-M(Y_1)M(Y_2). \mu_(y_1y_2)=M(\varphi_1(X)\varphi_2(X))-M(\varphi_1(X))M(\varphi_2(X)). Să ne uităm la principal proprietăţile momentului de corelaţie şi ale coeficientului de corelaţie. Proprietatea 1. Adăugarea de constante la variabile aleatoare nu modifică momentul de corelație și coeficientul de corelație. Proprietatea 2. Pentru orice variabile aleatoare X și Y, valoarea absolută a momentului de corelare nu depășește media geometrică a variațiilor acestor valori: |\mu_(xy)|\leqslant\sqrt(D[X]\cdot D[Y])=\sigma_x\cdot \sigma_y, Variabilă aleatorie
este o variabilă care poate lua anumite valori în funcție de diverse circumstanțe și variabila aleatoare se numeste continua
, dacă poate lua orice valoare din orice interval limitat sau nelimitat. Pentru o variabilă aleatoare continuă, este imposibil să se indice toate valorile posibile, așa că desemnăm intervale ale acestor valori care sunt asociate cu anumite probabilități. Exemple de variabile aleatoare continue includ: diametrul unei piese care este măcinată la o dimensiune dată, înălțimea unei persoane, raza de zbor a unui proiectil etc. Deoarece pentru variabile aleatoare continue funcţia F(X), Spre deosebire de variabile aleatoare discrete, nu are salturi nicăieri, atunci probabilitatea oricărei valori individuale a unei variabile aleatoare continue este zero. Aceasta înseamnă că pentru o variabilă aleatoare continuă nu are sens să vorbim despre distribuția probabilității dintre valorile sale: fiecare dintre ele are probabilitate zero. Cu toate acestea, într-un sens, printre valorile unei variabile aleatoare continue există „mai mult și mai puțin probabil”. De exemplu, aproape nimeni nu s-ar îndoi că valoarea unei variabile aleatoare - înălțimea unei persoane întâlnite aleatoriu - 170 cm - este mai probabilă decât 220 cm, deși ambele valori pot apărea în practică. Ca lege de distribuție care are sens numai pentru variabile aleatoare continue, este introdus conceptul de densitate de distribuție sau densitate de probabilitate. Să o abordăm comparând semnificația funcției de distribuție pentru o variabilă aleatoare continuă și pentru o variabilă aleatoare discretă. Deci, funcția de distribuție a unei variabile aleatoare (atât discrete, cât și continue) sau funcţie integrală se numește funcție care determină probabilitatea ca valoarea unei variabile aleatoare X mai mică sau egală cu valoarea limită X. Pentru o variabilă aleatoare discretă în punctele valorilor sale X1
, X 2
, ..., X eu,... se concentrează mase de probabilităţi p1
, p 2
, ..., p eu,..., iar suma tuturor maselor este egală cu 1. Să transferăm această interpretare în cazul unei variabile aleatoare continue. Să ne imaginăm că o masă egală cu 1 nu este concentrată în puncte individuale, ci este continuu „untată” de-a lungul axei absciselor Oh cu o oarecare densitate neuniformă. Probabilitatea ca o variabilă aleatoare să cadă în orice zonă Δ X va fi interpretată ca masa pe secțiune, iar densitatea medie la acea secțiune ca raportul dintre masă și lungime. Tocmai am introdus un concept important în teoria probabilității: densitatea distribuției. Probabilitate densitate f(X) a unei variabile aleatoare continue este derivata funcției sale de distribuție: Cunoscând funcția de densitate, puteți găsi probabilitatea ca valoarea unei variabile aleatoare continue să aparțină intervalului închis [ A; b]: probabilitatea ca o variabilă aleatoare continuă X va lua orice valoare din intervalul [ A; b], este egal cu o anumită integrală a densității sale de probabilitate variind de la A inainte de b: În acest caz, formula generală a funcției F(X) distribuția de probabilitate a unei variabile aleatoare continue, care poate fi utilizată dacă este cunoscută funcția de densitate f(X)
: Graficul densității de probabilitate a unei variabile aleatoare continue se numește curba de distribuție (figura de mai jos). Aria unei figuri (umbrite în figură) delimitată de o curbă, linii drepte trasate din puncte AȘi b perpendicular pe axa x și pe axa Oh, afișează grafic probabilitatea ca valoarea unei variabile aleatoare continue X se află în raza de A inainte de b. 1. Probabilitatea ca o variabilă aleatorie să ia orice valoare din interval (și aria figurii care este limitată de graficul funcției f(X) și axa Oh) este egal cu unu: 2. Funcția de densitate de probabilitate nu poate lua valori negative: iar în afara existenţei distribuţiei valoarea acesteia este zero Densitatea de distribuție f(X), precum și funcția de distribuție F(X), este una dintre formele legii distribuției, dar spre deosebire de funcția de distribuție, nu este universală: densitatea distribuției există doar pentru variabile aleatoare continue. Să menționăm cele mai importante două tipuri de distribuție a unei variabile aleatoare continue în practică. Dacă funcţia de densitate de distribuţie f(X) variabilă aleatoare continuă într-un interval finit [ A; b] ia o valoare constantă C, iar în afara intervalului ia o valoare egală cu zero, apoi aceasta distribuția se numește uniformă . Dacă graficul funcției densității distribuției este simetric față de centru, valorile medii sunt concentrate în apropierea centrului, iar atunci când se îndepărtează de centru, sunt colectate cele mai diferite de medie (graficul funcției seamănă cu o secțiune a unui clopot), apoi aceasta distribuția se numește normală . Exemplul 1. Funcția de distribuție a probabilității a unei variabile aleatoare continue este cunoscută: Funcția de căutare f(X) densitatea de probabilitate a unei variabile aleatoare continue. Construiți grafice ale ambelor funcții. Aflați probabilitatea ca o variabilă aleatoare continuă să ia orice valoare în intervalul de la 4 la 8: . Soluţie. Obținem funcția de densitate a probabilității găsind derivata funcției de distribuție a probabilității: Graficul unei funcții F(X) - parabola: Graficul unei funcții f(X) - Drept: Să găsim probabilitatea ca o variabilă aleatoare continuă să ia orice valoare în intervalul de la 4 la 8: Exemplul 2. Funcția de densitate de probabilitate a unei variabile aleatoare continue este dată astfel: Calculați coeficientul C. Funcția de căutare F(X) distribuția de probabilitate a unei variabile aleatoare continue. Construiți grafice ale ambelor funcții. Aflați probabilitatea ca o variabilă aleatoare continuă să ia orice valoare în intervalul de la 0 la 5: . Soluţie. Coeficient C găsim, folosind proprietatea 1 a funcției de densitate de probabilitate: Astfel, funcția de densitate de probabilitate a unei variabile aleatoare continue este: Prin integrare, găsim funcția F(X) distribuţii de probabilitate. Dacă X < 0
, то
F(X) = 0 . Daca 0< X < 10
, то X> 10, atunci F(X) = 1
. Prin urmare, înregistrare completă funcții de distribuție a probabilității: Graficul unei funcții f(X)
: Graficul unei funcții F(X)
: Să găsim probabilitatea ca o variabilă aleatoare continuă să ia orice valoare în intervalul de la 0 la 5: Exemplul 3. Densitatea de probabilitate a unei variabile aleatoare continue X este dat de egalitatea , și . Găsiți coeficientul A, probabilitatea ca o variabilă aleatoare continuă X va lua orice valoare din intervalul ]0, 5[, funcția de distribuție a unei variabile aleatoare continue X. Soluţie. Prin condiție ajungem la egalitate Prin urmare, de unde . Asa de, Acum găsim probabilitatea ca o variabilă aleatoare continuă X va lua orice valoare din intervalul ]0, 5[: Acum obținem funcția de distribuție a acestei variabile aleatoare: Exemplul 4. Aflați densitatea de probabilitate a unei variabile aleatoare continue X, care ia numai valori nenegative și funcția de distribuție
adică momentul de corelare a două funcții ale variabilelor aleatoare este egal cu așteptarea matematică a produsului acestor funcții minus produsul așteptărilor matematice. Funcția de distribuție a unei variabile aleatoare continue și densitatea probabilității
![]() .
.
![]()
![]() .
.![]() .
.
Proprietăți ale funcției de densitate de probabilitate a unei variabile aleatoare continue





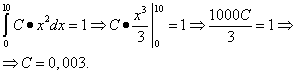
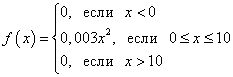
![]() .
.


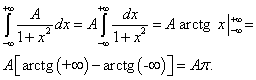
![]() .
.

![]() .
.

