$X$. Для начала напомним следующее определение:
Определение 1
Генеральная совокупность -- совокупность случайно отобранных объектов данного вида, над которыми проводят наблюдения с целью получения конкретных значений случайной величины, проводимых в неизменных условиях при изучении одной случайной величины данного вида.
Определение 2
Генеральная дисперсия -- среднее арифметическое квадратов отклонений значений вариант генеральной совокупности от их среднего значения.
Пусть значения вариант $x_1,\ x_2,\dots ,x_k$ имеют, соответственно, частоты $n_1,\ n_2,\dots ,n_k$. Тогда генеральная дисперсия вычисляется по формуле:
Рассмотрим частный случай. Пусть все варианты $x_1,\ x_2,\dots ,x_k$ различны. В этом случае $n_1,\ n_2,\dots ,n_k=1$. Получаем, что в этом случае генеральная дисперсия вычисляется по формуле:
С этим понятием также связано понятие генерального среднего квадратического отклонения.
Определение 3
Генеральное среднее квадратическое отклонение
\[{\sigma }_г=\sqrt{D_г}\]
Выборочная дисперсия
Пусть нам дана выборочная совокупность относительно случайной величины $X$. Для начала напомним следующее определение:
Определение 4
Выборочная совокупность -- часть отобранных объектов из генеральной совокупности.
Определение 5
Выборочная дисперсия -- среднее арифметическое значений вариант выборочной совокупности.
Пусть значения вариант $x_1,\ x_2,\dots ,x_k$ имеют, соответственно, частоты $n_1,\ n_2,\dots ,n_k$. Тогда выборочная дисперсия вычисляется по формуле:
Рассмотрим частный случай. Пусть все варианты $x_1,\ x_2,\dots ,x_k$ различны. В этом случае $n_1,\ n_2,\dots ,n_k=1$. Получаем, что в этом случае выборочная дисперсия вычисляется по формуле:
С этим понятием также связано понятие выборочного среднего квадратического отклонения.
Определение 6
Выборочное среднее квадратическое отклонение -- квадратный корень из генеральной дисперсии:
\[{\sigma }_в=\sqrt{D_в}\]
Исправленная дисперсия
Для нахождения исправленной дисперсии $S^2$ необходимо умножить выборочную дисперсию на дробь $\frac{n}{n-1}$, то есть
С этим понятием также связано понятие исправленного среднего квадратического отклонения, которое находится по формуле:
В случае, когда значение вариант не являются дискретными, а представляют из себя интервалы, то в формулах для вычисления генеральной или выборочной дисперсий за значение $x_i$ принимается значение середины интервала, которому принадлежит $x_i.$
Пример задачи на нахождение дисперсии и среднего квадратического отклонения
Пример 1
Выборочная совокупность задана следующей таблицей распределения:
Рисунок 1.
Найдем для нее выборочную дисперсию, выборочное среднее квадратическое отклонение, исправленную дисперсию и исправленное среднее квадратическое отклонение.
Для решения этой задачи для начала сделаем расчетную таблицу:
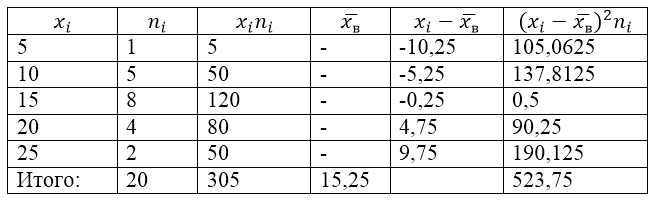
Рисунок 2.
Величина $\overline{x_в}$ (среднее выборочное) в таблице находится по формуле:
\[\overline{x_в}=\frac{\sum\limits^k_{i=1}{x_in_i}}{n}\]
\[\overline{x_в}=\frac{\sum\limits^k_{i=1}{x_in_i}}{n}=\frac{305}{20}=15,25\]
Найдем выборочную дисперсию по формуле:
Выборочное среднее квадратическое отклонение:
\[{\sigma }_в=\sqrt{D_в}\approx 5,12\]
Исправленная дисперсия:
\[{S^2=\frac{n}{n-1}D}_в=\frac{20}{19}\cdot 26,1875\approx 27,57\]
Исправленное среднее квадратическое отклонение.
Программа Excel высоко ценится как профессионалами, так и любителями, ведь работать с нею может пользователь любого уровня подготовки. Например, каждый желающий с минимальными навыками «общения» с Экселем может нарисовать простенький график, сделать приличную табличку и т.д.
Вместе с тем, эта программа даже позволяет выполнять различного рода расчеты, к примеру, расчет , но для этого уже необходим несколько иной уровень подготовки. Впрочем, если вы только начали тесное знакомство с данной прогой и интересуетесь всем, что поможет вам стать более продвинутым юзером, эта статья для вас. Сегодня я расскажу, что собой представляет среднеквадратичное отклонение формула в excel, зачем она вообще нужна и, собственно говоря, когда применяется. Поехали!
Что это такое
Начнем с теории. Средним квадратичным отклонением принято называть квадратный корень, полученный из среднего арифметического всех квадратов разностей между имеющимися величинами, а также их средним арифметическим. К слову, эту величину принято называть греческой буквой «сигма». Стандартное отклонение рассчитывается по формуле СТАНДОТКЛОН, соответственно, программа делает это за пользователя сама.
Суть же данного понятия заключается в том, чтобы выявить степень изменчивости инструмента, то есть, это, в своем роде, индикатор родом из описательной статистики. Он выявляет изменения волатильности инструмента в каком-либо временном промежутке. С помощью формул СТАНДОТКЛОН можно оценить стандартное отклонение при выборке, при этом логические и текстовые значения игнорируются.
Формула
Помогает рассчитать среднее квадратичное отклонение в excel формула, которая автоматически предусмотрена в программе Excel. Чтобы ее найти, необходимо найти в Экселе раздел формулы, а уже там выбрать ту, которая имеет название СТАНДОТКЛОН, так что очень просто.
После этого перед вами появится окошко, в котором нужно будет ввести данные для вычисления. В частности, в специальные поля следует вписать два числа, после чего программа сама высчитает стандартное отклонение по выборке.

Бесспорно, математические формулы и расчеты – вопрос достаточно сложный, и не все пользователи с ходу могут с ним справиться. Тем не менее, если копнуть немного глубже и чуть более детально разобраться в вопросе, оказывается, что не все так уж и печально. Надеюсь, на примере вычисления среднеквадратичного отклонения вы в этом убедились.
Видео в помощь
Мудрые математики и статистики придумали более надежный показатель, хотя и несколько другого назначения – среднее линейное отклонение . Этот показатель характеризует меру разброса значений совокупности данных вокруг их среднего значения.
Для того, чтобы показать меру разброса данных нужно вначале определиться, относительно чего этот самый разброс будет считаться - jбычно это средняя величина. Дальше нужно посчитать, насколько значения анализируемой совокупности данных находятся далеко от средней. Понятное дело, что каждому значению соответствует некоторая величина отклонения, но нас же интересует общая оценка, охватывающая всю совокупность. Поэтому рассчитывают среднее отклонение по формуле обычной средней арифметической. Но! Но для того, чтобы рассчитать среднее из отклонений, их нужно вначале сложить. И если мы сложим положительные и отрицательные числа, то они взаимоуничтожатся и их сумма будет стремиться к нулю. Чтобы этого избежать, все отклонения берутся по модулю, то есть все отрицательные числа становятся положительными. Вот теперь среднее отклонение будет показывать обобщенную меру разброса значений. В итоге, средне линейное отклонение будет рассчитываться по формуле:
a – среднее линейное отклонение,
x – анализируемый показатель, с черточкой сверху – среднее значение показателя,
n – количество значений в анализируемой совокупности данных,
оператор суммирования, надеюсь, никого не пугает.
Рассчитанное по указанной формуле среднее линейное отклонение отражает среднее абсолютное отклонение от средней величины по данной совокупности.

На картинке красная линия - это среднее значение. Отклонения каждого наблюдения от среднего указаны маленькими стрелочками. Именно они берутся по модулю и суммируются. Потом все делится на количество значений.
Для полноты картины нужно привести еще и пример. Допустим, имеется фирма по производству черенков для лопат. Каждый черенок должен быть 1,5 метра длиной, но, что еще важней, все должны быть одинаковыми или, по крайней мере, плюс-минус 5 см. Однако нерадивые работники то 1,2 м отпилят, то 1,8 м. Дачники недовольны. Решил директор фирмы провести статистический анализ длины черенков. Отобрал 10 штук и замерял их длину, нашел среднюю и рассчитал среднее линейное отклонение. Средняя получилась как раз, что надо – 1,5 м. А вот среднее линейное отклонение вышло 0,16 м. Вот и получается, что каждый черенок длиннее или короче, чем нужно в среднем на 16 см. Есть, о чем поговорить с работниками. На самом деле я не встречал реального использования данного показателя, поэтому пример придумал сам. Тем не менее, в статистике есть такой показатель.
Дисперсия
Как и среднее линейное отклонение, дисперсия также отражает меру разброса данных вокруг средней величины.
Формула для расчета дисперсии выглядит так:
 (для вариационных
рядов (взвешенная дисперсия))
(для вариационных
рядов (взвешенная дисперсия))
 (для несгруппированных
данных (простая дисперсия))
(для несгруппированных
данных (простая дисперсия))
Где: σ 2 – дисперсия, Xi – анализируемsq показатель (значение признака), – среднее значение показателя, f i – количество значений в анализируемой совокупности данных.
Дисперсия - это средний квадрат отклонений.
Сначала рассчитывается среднее значение, затем берется разница между каждым исходным и средним значением, возводится в квадрат, умножается на частоту соответствующего значения признака, складывается и затем делится на количество значений в данной совокупности.
Однако в чистом виде, как, например, средняя арифметическая, или индекс, дисперсия не используется. Это скорее вспомогательный и промежуточный показатель, который используется для других видов статистического анализа.
Упрощенный способ расчета дисперсии
![]()
Среднеквадратическое отклонение
Чтобы использовать дисперсию дл анализа данных из нее извлекают квадратный корень. Получается так называемое среднеквадратическое отклонение .

Кстати, стандартное отклонение еще называют сигмой – от греческой буквы, которой его обозначают.
Среднеквадратическое отклонение, очевидно, также характеризует меру рассеяния данных, но теперь (в отличие от дисперсии) его можно сравнивать с исходными данными. Как правило, среднеквадратические показатели в статистике дают более точные результаты, чем линейные. Следовательно, среднеквадратическое отклонение является более точным показателем меры рассеяния данных, чем среднее линейное отклонение.
Среднеквадрати́ческое отклоне́ние (синонимы: среднее квадрати́ческое отклоне́ние , среднеквадрати́чное отклоне́ние , квадрати́чное отклоне́ние ; близкие термины: станда́ртное отклоне́ние , станда́ртный разбро́с ) - в теории вероятностей и статистике наиболее распространённый показатель рассеивания значений случайной величины относительно её математического ожидания . При ограниченных массивах выборок значений вместо математического ожидания используется среднее арифметическое совокупности выборок.
Энциклопедичный YouTube
-
1 / 5
Среднеквадратическое отклонение измеряется в единицах измерения самой случайной величины и используется при расчёте стандартной ошибки среднего арифметического , при построении доверительных интервалов , при статистической проверке гипотез , при измерении линейной взаимосвязи между случайными величинами. Определяется как квадратный корень из дисперсии случайной величины .
Среднеквадратическое отклонение:
s = n n − 1 σ 2 = 1 n − 1 ∑ i = 1 n (x i − x ¯) 2 ; {\displaystyle s={\sqrt {{\frac {n}{n-1}}\sigma ^{2}}}={\sqrt {{\frac {1}{n-1}}\sum _{i=1}^{n}\left(x_{i}-{\bar {x}}\right)^{2}}};}- Примечание: Очень часто встречаются разночтения в названиях СКО (Среднеквадратического отклонения) и СТО (Стандартного отклонения) с их формулами. Например, в модуле numPy языка программирования Python функция std() описывается как "standart deviation", в то время как формула отражает СКО (деление на корень из выборки). В Excel же функция СТАНДОТКЛОН() другая (деление на корень из n-1).
Стандартное отклонение (оценка среднеквадратического отклонения случайной величины x относительно её математического ожидания на основе несмещённой оценки её дисперсии) s {\displaystyle s} :
σ = 1 n ∑ i = 1 n (x i − x ¯) 2 . {\displaystyle \sigma ={\sqrt {{\frac {1}{n}}\sum _{i=1}^{n}\left(x_{i}-{\bar {x}}\right)^{2}}}.}где σ 2 {\displaystyle \sigma ^{2}} - дисперсия ; x i {\displaystyle x_{i}} - i -й элемент выборки; n {\displaystyle n} - объём выборки; - среднее арифметическое выборки:
x ¯ = 1 n ∑ i = 1 n x i = 1 n (x 1 + … + x n) . {\displaystyle {\bar {x}}={\frac {1}{n}}\sum _{i=1}^{n}x_{i}={\frac {1}{n}}(x_{1}+\ldots +x_{n}).}Следует отметить, что обе оценки являются смещёнными. В общем случае несмещённую оценку построить невозможно. Однако оценка на основе оценки несмещённой дисперсии является состоятельной .
В соответствии с ГОСТ Р 8.736-2011 среднеквадратическое отклонение считается по второй формуле данного раздела. Пожалуйста, сверьте результаты.
Правило трёх сигм
Правило трёх сигм ( 3 σ {\displaystyle 3\sigma } ) - практически все значения нормально распределённой случайной величины лежат в интервале (x ¯ − 3 σ ; x ¯ + 3 σ) {\displaystyle \left({\bar {x}}-3\sigma ;{\bar {x}}+3\sigma \right)} . Более строго - приблизительно с вероятностью 0,9973 значение нормально распределённой случайной величины лежит в указанном интервале (при условии, что величина x ¯ {\displaystyle {\bar {x}}} истинная, а не полученная в результате обработки выборки).
Если же истинная величина x ¯ {\displaystyle {\bar {x}}} неизвестна, то следует пользоваться не σ {\displaystyle \sigma } , а s . Таким образом, правило трёх сигм преобразуется в правило трёх s .
Интерпретация величины среднеквадратического отклонения
Большее значение среднеквадратического отклонения показывает больший разброс значений в представленном множестве со средней величиной множества; меньшее значение, соответственно, показывает, что значения в множестве сгруппированы вокруг среднего значения.
Например, у нас есть три числовых множества: {0, 0, 14, 14}, {0, 6, 8, 14} и {6, 6, 8, 8}. У всех трёх множеств средние значения равны 7, а среднеквадратические отклонения, соответственно, равны 7, 5 и 1. У последнего множества среднеквадратическое отклонение маленькое, так как значения в множестве сгруппированы вокруг среднего значения; у первого множества самое большое значение среднеквадратического отклонения - значения внутри множества сильно расходятся со средним значением.
В общем смысле среднеквадратическое отклонение можно считать мерой неопределённости. К примеру, в физике среднеквадратическое отклонение используется для определения погрешности серии последовательных измерений какой-либо величины. Это значение очень важно для определения правдоподобности изучаемого явления в сравнении с предсказанным теорией значением: если среднее значение измерений сильно отличается от предсказанных теорией значений (большое значение среднеквадратического отклонения), то полученные значения или метод их получения следует перепроверить. отождествляется с риском портфеля.
Климат
Предположим, существуют два города с одинаковой средней максимальной дневной температурой, но один расположен на побережье, а другой на равнине. Известно, что в городах, расположенных на побережье, множество различных максимальных дневных температур меньше, чем у городов, расположенных внутри континента. Поэтому среднеквадратическое отклонение максимальных дневных температур у прибрежного города будет меньше, чем у второго города, несмотря на то, что среднее значение этой величины у них одинаковое, что на практике означает, что вероятность того, что максимальная температура воздуха каждого конкретного дня в году будет сильнее отличаться от среднего значения, выше у города, расположенного внутри континента.
Спорт
Предположим, что есть несколько футбольных команд, которые оцениваются по некоторому набору параметров, например, количеству забитых и пропущенных голов, голевых моментов и т. п. Наиболее вероятно, что лучшая в этой группе команда будет иметь лучшие значения по большему количеству параметров. Чем меньше у команды среднеквадратическое отклонение по каждому из представленных параметров, тем предсказуемее является результат команды, такие команды являются сбалансированными. С другой стороны, у команды с большим значением среднеквадратического отклонения сложно предсказать результат, что в свою очередь объясняется дисбалансом, например, сильной защитой, но слабым нападением.
Использование среднеквадратического отклонения параметров команды позволяет в той или иной мере предсказать результат матча двух команд, оценивая сильные и слабые стороны команд, а значит, и выбираемых способов борьбы.
Стоит отметить, что у такого расчета дисперсии есть недостаток – она получается смещенной, т.е. ее математическое ожидание не равно истинному значению дисперсии. Подробней об этом . В то же время не все так плохо. При увеличении объема выборки она все-таки приближается к своему теоретическому аналогу, т.е. является асимптотически не смещенной. Поэтому при работе с большими размерами выборок можно использовать формулу выше.
Язык знаков полезно перевести на язык слов. Получится, что дисперсия — это средний квадрат отклонений. То есть вначале рассчитывается среднее значение, затем берется разница между каждым исходным и средним значением, возводится в квадрат, складывается и затем делится на количество значений в данной совокупности. Разница между отдельным значением и средней отражает меру отклонения. В квадрат возводится для того, чтобы все отклонения стали исключительно положительными числами и чтобы избежать взаимоуничтожения положительных и отрицательных отклонений при их суммировании. Затем, имея квадраты отклонений, мы просто рассчитываем среднюю арифметическую. Средний – квадрат – отклонений. Отклонения возводятся в квадрат, и считается средняя. Разгадка заключается всего в трех словах.
Однако в чистом виде, как, например, средняя арифметическая, или индекс, дисперсия не используется. Это скорее вспомогательный и промежуточный показатель, который необходим для других видов статистического анализа. У нее даже единицы измерения нормальной нет. Судя по формуле, это квадрат единицы измерения исходных данных. Без бутылки, как говорится, не разберешься.
{module 111}
Дабы вернуть дисперсию в реальность, то есть использовать в более приземленных целей, из нее извлекают квадратный корень. Получается так называемое среднеквадратичное отклонение (СКО) . Встречаются названия «стандартное отклонение» или «сигма» (от названия греческой буквы). Формула стандартного отклонения имеет вид:

Для получения этого показателя по выборке используют формулу:

Как и с дисперсией, есть и немного другой вариант расчета . Но с ростом выборки разница исчезает.
Среднеквадратичное отклонение, очевидно, также характеризует меру рассеяния данных, но теперь (в отличие от дисперсии) его можно сравнивать с исходными данными, так как единицы измерения у них одинаковые (это явствует из формулы расчета). Но и этот показатель в чистом виде не очень информативен, так как в нем заложено слишком много промежуточных расчетов, которые сбивают с толку (отклонение, в квадрат, сумма, среднее, корень). Тем не менее, со среднеквадратичным отклонением уже можно работать непосредственно, потому что свойства данного показателя хорошо изучены и известны. К примеру, есть такое правило трех сигм , которое гласит, что у данных 997 значений из 1000 находятся в пределах ±3 сигмы от средней арифметической. Среднеквадратичное отклонение, как мера неопределенности, также участвует во многих статистических расчетах. С ее помощью устанавливают степень точности различных оценок и прогнозов. Если вариация очень большая, то стандартное отклонение тоже получится большим, следовательно, и прогноз будет неточным, что выразится, к примеру, в очень широких доверительных интервалах.
Коэффициент вариации
Среднее квадратическое отклонение дает абсолютную оценку меры разброса. Поэтому чтобы понять, насколько разброс велик относительно самих значений (т.е. независимо от их масштаба), требуется относительный показатель. Такой показатель называется коэффициентом вариации и рассчитывается по следующей формуле:
Коэффициент вариации измеряется в процентах (если умножить на 100%). По этому показателю можно сравнивать самых разных явлений независимо от их масштаба и единиц измерения. Данный факт и делает коэффициент вариации столь популярным.
В статистике принято, что, если значение коэффициента вариации менее 33%, то совокупность считается однородной, если больше 33%, то – неоднородной. Мне здесь трудно что-то прокомментировать. Не знаю, кто и почему так определил, но это считается аксиомой.
Чувствую, что я увлекся сухой теорией и нужно привести что-то наглядное и образное. С другой стороны все показатели вариации описывают примерно одно и то же, только рассчитываются по-разному. Поэтому разнообразием примеров блеснуть трудно, Отличаться могут лишь значения показателей, но не их суть. Вот и сравним, как отличаются значения различных показателей вариации для одной и той же совокупности данных. Возьмем пример с расчетом среднего линейного отклонения (из ). Вот исходные данные:

И график для напоминания.

По этим данным рассчитаем различные показатели вариации.
Среднее значение – это обычная средняя арифметическая.
Размах вариации – разница между максимумом и минимумом:
Среднее линейное отклонение считается по формуле:
Стандартное отклонение:
Расчет сведем в табличку.

Как видно, среднее линейное и среднеквадратичное отклонение дают похожие значения степени вариации данных. Дисперсия – это сигма в квадрате, поэтому она всегда будет относительно большим числом, что, собственно, ни о чем не говорит. Размах вариации – это разница между крайними значениями и может говорить о многом.
Подведем некоторые итоги.
Вариация показателя отражает изменчивость процесса или явления. Ее степень может измеряться с помощью нескольких показателей.
1. Размах вариации – разница между максимумом и минимумом. Отражает диапазон возможных значений.
2. Среднее линейное отклонение – отражает среднее из абсолютных (по модулю) отклонений всех значений анализируемой совокупности от их средней величины.
3. Дисперсия – средний квадрат отклонений.
4. Среднеквадратичное отклонение – корень из дисперсии (среднего квадрата отклонений).
5. Коэффициент вариации – наиболее универсальный показатель, отражающий степень разброса значений независимо от их масштаба и единиц измерения. Коэффициент вариации измеряется в процентах и может быть использован для сравнения вариации различных процессов и явлений.Таким образом, в статистическом анализе существует система показателей, отражающих однородность явлений и устойчивость процессов. Часто показатели вариации не имеют самостоятельного смысла и используются для дальнейшего анализа данных (расчет доверительных интервалов

